 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative AI collective behavior needs an interactionist paradigm
Jan 15, 2026In this article, we argue that understanding the collective behavior of agents based on large language models (LLMs) is an essential area of inquiry, with important implications in terms of risks and benefits, impacting us as a society at many levels. We claim that the distinctive nature of LLMs--namely, their initialization with extensive pre-trained knowledge and implicit social priors, together with their capability of adaptation through in-context learning--motivates the need for an interactionist paradigm consisting of alternative theoretical foundations, methodologies, and analytical tools, in order to systematically examine how prior knowledge and embedded values interact with social context to shape emergent phenomena in multi-agent generative AI systems. We propose and discuss four directions that we consider crucial for the development and deployment of LLM-based collectives, focusing on theory, methods, and trans-disciplinary dialogue.
Reasoning Models Generate Societies of Thought
Jan 15, 2026Large language models have achieved remarkable capabilities across domains, yet mechanisms underlying sophisticated reasoning remain elusive. Recent reasoning models outperform comparable instruction-tuned models on complex cognitive tasks, attributed to extended computation through longer chains of thought. Here we show that enhanced reasoning emerges not from extended computation alone, but from simulating multi-agent-like interactions -- a society of thought -- which enables diversification and debate among internal cognitive perspectives characterized by distinct personality traits and domain expertise. Through quantitative analysis and mechanistic interpretability methods applied to reasoning traces, we find that reasoning models like DeepSeek-R1 and QwQ-32B exhibit much greater perspective diversity than instruction-tuned models, activating broader conflict between heterogeneous personality- and expertise-related features during reasoning. This multi-agent structure manifests in conversational behaviors, including question-answering, perspective shifts, and the reconciliation of conflicting views, and in socio-emotional roles that characterize sharp back-and-forth conversations, together accounting for the accuracy advantage in reasoning tasks. Controlled reinforcement learning experiments reveal that base models increase conversational behaviors when rewarded solely for reasoning accuracy, and fine-tuning models with conversational scaffolding accelerates reasoning improvement over base models. These findings indicate that the social organization of thought enables effective exploration of solution spaces. We suggest that reasoning models establish a computational parallel to collective intelligence in human groups, where diversity enables superior problem-solving when systematically structured, which suggests new opportunities for agent organization to harness the wisdom of crowds.
Classroom AI: Large Language Models as Grade-Specific Teachers
Jan 09, 2026Large Language Models (LLMs) offer a promising solution to complement traditional teaching and address global teacher shortages that affect hundreds of millions of children, but they fail to provide grade-appropriate responses for students at different educational levels. We introduce a framework for finetuning LLMs to generate age-appropriate educational content across six grade levels, from lower elementary to adult education. Our framework successfully adapts explanations to match students' comprehension capacities without sacrificing factual correctness. This approach integrates seven established readability metrics through a clustering method and builds a comprehensive dataset for grade-specific content generation. Evaluations across multiple datasets with 208 human participants demonstrate substantial improvements in grade-level alignment, achieving a 35.64 percentage point increase compared to prompt-based methods while maintaining response accuracy. AI-assisted learning tailored to different grade levels has the potential to advance educational engagement and equity.
Deep versus Broad Technology Search and the Timing of Innovation Impact
Dec 30, 2025This study offers a new perspective on the depth-versus-breadth debate in innovation strategy, by modeling inventive search within dynamic collective knowledge systems, and underscoring the importance of timing for technological impact. Using frontier machine learning to project patent citation networks in hyperbolic space, we analyze 4.9 million U.S. patents to examine how search strategies give rise to distinct temporal patterns in impact accumulation. We find that inventions based on deep search, which relies on a specialized understanding of complex recombination structures, drive higher short-term impact through early adoption within specialized communities, but face diminishing returns as innovations become "locked-in" with limited diffusion potential. Conversely, when inventions are grounded in broad search that spans disparate domains, they encounter initial resistance but achieve wider diffusion and greater long-term impact by reaching cognitively diverse audiences. Individual inventions require both depth and breadth for stable impact. Organizations can strategically balance approaches across multiple inventions: using depth to build reliable technological infrastructure while pursuing breadth to expand applications. We advance innovation theory by demonstrating how deep and broad search strategies distinctly shape the timing and trajectory of technological impact, and how individual inventors and organizations can leverage these mechanisms to balance exploitation and exploration.
Hollywood Town: Long-Video Generation via Cross-Modal Multi-Agent Orchestration
Oct 25, 2025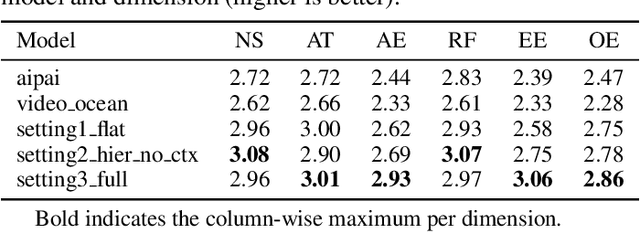
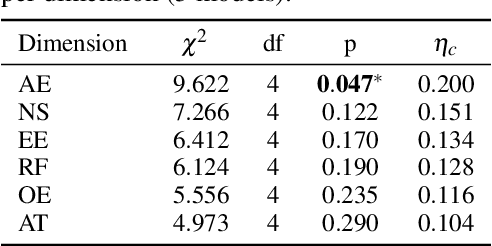
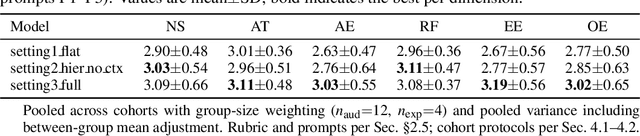
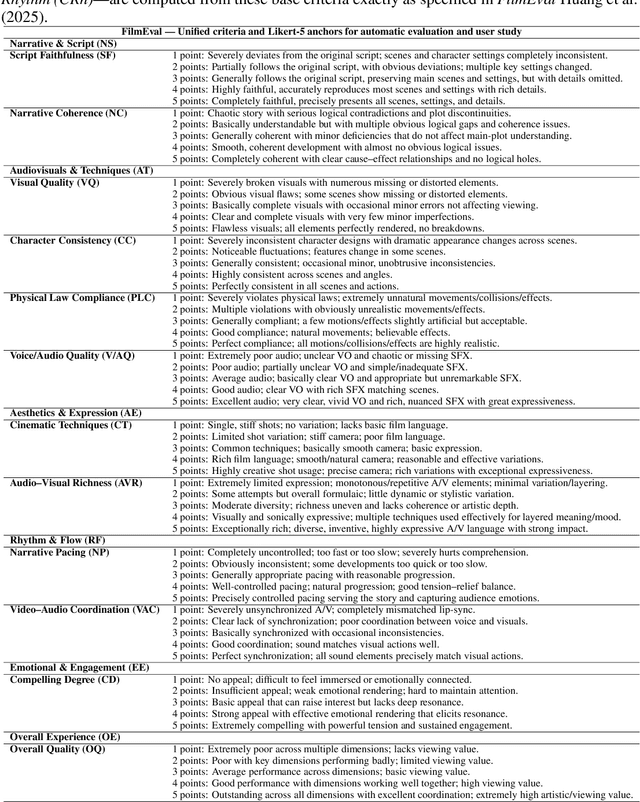
Recent advancements in multi-agent systems have demonstrated significant potential for enhancing creative task performance, such as long video generation. This study introduces three innovations to improve multi-agent collaboration. First, we propose OmniAgent, a hierarchical, graph-based multi-agent framework for long video generation that leverages a film-production-inspired architecture to enable modular specialization and scalable inter-agent collaboration. Second, inspired by context engineering, we propose hypergraph nodes that enable temporary group discussions among agents lacking sufficient context, reducing individual memory requirements while ensuring adequate contextual information. Third, we transition from directed acyclic graphs (DAGs) to directed cyclic graphs with limited retries, allowing agents to reflect and refine outputs iteratively, thereby improving earlier stages through feedback from subsequent nodes. These contributions lay the groundwork for developing more robust multi-agent systems in creative tasks.
Rationality Check! Benchmarking the Rationality of Large Language Models
Sep 18, 2025Large language models (LLMs), a recent advance in deep learning and machine intelligence, have manifested astonishing capacities, now considered among the most promising for artificial general intelligence. With human-like capabilities, LLMs have been used to simulate humans and serve as AI assistants across many applications. As a result, great concern has arisen about whether and under what circumstances LLMs think and behave like real human agents. Rationality is among the most important concepts in assessing human behavior, both in thinking (i.e., theoretical rationality) and in taking action (i.e., practical rationality). In this work, we propose the first benchmark for evaluating the omnibus rationality of LLMs, covering a wide range of domains and LLMs. The benchmark includes an easy-to-use toolkit, extensive experimental results, and analysis that illuminates where LLMs converge and diverge from idealized human rationality. We believe the benchmark can serve as a foundational tool for both developers and users of LLMs.
Subjective Perspectives within Learned Representations Predict High-Impact Innovation
Jun 05, 2025Existing studies of innovation emphasize the power of social structures to shape innovation capacity. Emerging machine learning approaches, however, enable us to model innovators' personal perspectives and interpersonal innovation opportunities as a function of their prior trajectories of experience. We theorize then quantify subjective perspectives and innovation opportunities based on innovator positions within the geometric space of concepts inscribed by dynamic language representations. Using data on millions of scientists, inventors, writers, entrepreneurs, and Wikipedia contributors across the creative domains of science, technology, film, entrepreneurship, and Wikipedia, here we show that measured subjective perspectives anticipate what ideas individuals and groups creatively attend to and successfully combine in future. When perspective and background diversity are decomposed as the angular difference between collaborators' perspectives on their creation and between their experiences, the former consistently anticipates creative achievement while the latter portends its opposite, across all cases and time periods examined. We analyze a natural experiment and simulate creative collaborations between AI (large language model) agents designed with various perspective and background diversity, which are consistent with our observational findings. We explore mechanisms underlying these findings and identify how successful collaborators leverage common language to weave together diverse experience obtained through trajectories of prior work that converge to provoke one another and innovate. We explore the importance of these findings for team assembly and research policy.
Topological Structure Learning Should Be A Research Priority for LLM-Based Multi-Agent Systems
May 29, 2025Large Language Model-based Multi-Agent Systems (MASs) have emerged as a powerful paradigm for tackling complex tasks through collaborative intelligence. Nevertheless, the question of how agents should be structurally organized for optimal cooperation remains largely unexplored. In this position paper, we aim to gently redirect the focus of the MAS research community toward this critical dimension: develop topology-aware MASs for specific tasks. Specifically, the system consists of three core components - agents, communication links, and communication patterns - that collectively shape its coordination performance and efficiency. To this end, we introduce a systematic, three-stage framework: agent selection, structure profiling, and topology synthesis. Each stage would trigger new research opportunities in areas such as language models, reinforcement learning, graph learning, and generative modeling; together, they could unleash the full potential of MASs in complicated real-world applications. Then, we discuss the potential challenges and opportunities in the evaluation of multiple systems. We hope our perspective and framework can offer critical new insights in the era of agentic AI.
Advancing the Scientific Method with Large Language Models: From Hypothesis to Discovery
May 22, 2025With recent Nobel Prizes recognising AI contributions to science, Large Language Models (LLMs) are transforming scientific research by enhancing productivity and reshaping the scientific method. LLMs are now involved in experimental design, data analysis, and workflows, particularly in chemistry and biology. However, challenges such as hallucinations and reliability persist. In this contribution, we review how Large Language Models (LLMs) are redefining the scientific method and explore their potential applications across different stages of the scientific cycle, from hypothesis testing to discovery. We conclude that, for LLMs to serve as relevant and effective creative engines and productivity enhancers, their deep integration into all steps of the scientific process should be pursued in collaboration and alignment with human scientific goals, with clear evaluation metrics. The transition to AI-driven science raises ethical questions about creativity, oversight, and responsibility. With careful guidance, LLMs could evolve into creative engines, driving transformative breakthroughs across scientific disciplines responsibly and effectively. However, the scientific community must also decide how much it leaves to LLMs to drive science, even when associations with 'reasoning', mostly currently undeserved, are made in exchange for the potential to explore hypothesis and solution regions that might otherwise remain unexplored by human exploration alone.
* 45 pages
Big Data and the Computational Social Science of Entrepreneurship and Innovation
May 13, 2025As large-scale social data explode and machine-learning methods evolve, scholars of entrepreneurship and innovation face new research opportunities but also unique challenges. This chapter discusses the difficulties of leveraging large-scale data to identify technological and commercial novelty, document new venture origins, and forecast competition between new technologies and commercial forms. It suggests how scholars can take advantage of new text, network, image, audio, and video data in two distinct ways that advance innovation and entrepreneurship research. First, machine-learning models, combined with large-scale data, enable the construction of precision measurements that function as system-level observatories of innovation and entrepreneurship across human societies. Second, new artificial intelligence models fueled by big data generate 'digital doubles' of technology and business, forming laboratories for virtual experimentation about innovation and entrepreneurship processes and policies. The chapter argues for the advancement of theory development and testing in entrepreneurship and innovation by coupling big data with big models.