 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Risk Assessments for Offensive Cybersecurity Agents
May 23, 2025



Foundation models are increasingly becoming better autonomous programmers, raising the prospect that they could also automate dangerous offensive cyber-operations. Current frontier model audits probe the cybersecurity risks of such agents, but most fail to account for the degrees of freedom available to adversaries in the real world. In particular, with strong verifiers and financial incentives, agents for offensive cybersecurity are amenable to iterative improvement by would-be adversaries. We argue that assessments should take into account an expanded threat model in the context of cybersecurity, emphasizing the varying degrees of freedom that an adversary may possess in stateful and non-stateful environments within a fixed compute budget. We show that even with a relatively small compute budget (8 H100 GPU Hours in our study), adversaries can improve an agent's cybersecurity capability on InterCode CTF by more than 40\% relative to the baseline -- without any external assistance. These results highlight the need to evaluate agents' cybersecurity risk in a dynamic manner, painting a more representative picture of risk.
Localized Cultural Knowledge is Conserved and Controllable in Large Language Models
Apr 14, 2025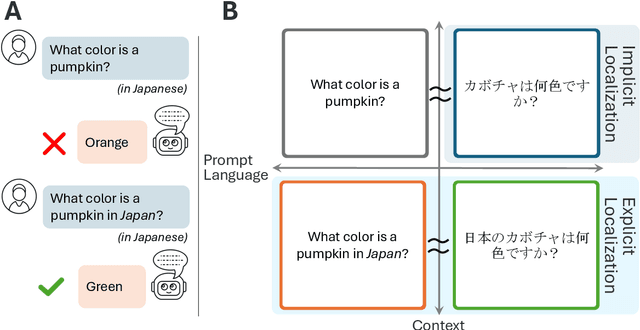

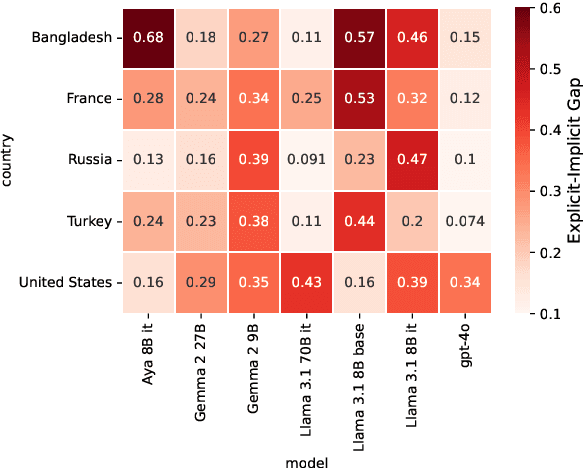
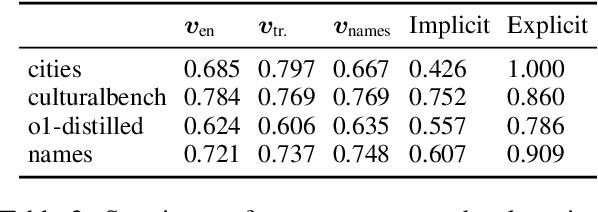
Just as humans display language patterns influenced by their native tongue when speaking new languages, LLMs often default to English-centric responses even when generating in other languages. Nevertheless, we observe that local cultural information persists within the models and can be readily activated for cultural customization. We first demonstrate that explicitly providing cultural context in prompts significantly improves the models' ability to generate culturally localized responses. We term the disparity in model performance with versus without explicit cultural context the explicit-implicit localization gap, indicating that while cultural knowledge exists within LLMs, it may not naturally surface in multilingual interactions if cultural context is not explicitly provided. Despite the explicit prompting benefit, however, the answers reduce in diversity and tend toward stereotypes. Second, we identify an explicit cultural customization vector, conserved across all non-English languages we explore, which enables LLMs to be steered from the synthetic English cultural world-model toward each non-English cultural world. Steered responses retain the diversity of implicit prompting and reduce stereotypes to dramatically improve the potential for customization. We discuss the implications of explicit cultural customization for understanding the conservation of alternative cultural world models within LLMs, and their controllable utility for translation, cultural customization, and the possibility of making the explicit implicit through soft control for expanded LLM function and appeal.
Inference Scaling fLaws: The Limits of LLM Resampling with Imperfect Verifiers
Dec 02, 2024



Recent research has generated hope that inference scaling could allow weaker language models to match or exceed the accuracy of stronger models, such as by repeatedly sampling solutions to a coding problem until it passes unit tests. The central thesis of this paper is that there is no free lunch for inference scaling: indefinite accuracy improvement through resampling can only be realized if the "verifier" (in this case, a set of unit tests) is perfect. When the verifier is imperfect, as it almost always is in domains such as reasoning or coding (for example, unit tests have imperfect coverage), there is a nonzero probability of false positives: incorrect solutions that pass the verifier. Resampling cannot decrease this probability, so it imposes an upper bound to the accuracy of resampling-based inference scaling even with an infinite compute budget. We find that there is a very strong correlation between the model's single-sample accuracy (i.e. accuracy without unit tests) and its false positive rate on coding benchmarks HumanEval and MBPP, whose unit tests have limited coverage. Therefore, no amount of inference scaling of weaker models can enable them to match the single-sample accuracy of a sufficiently strong model (Fig. 1a). When we consider that false positives have a negative utility compared to abstaining from producing a solution, it bends the inference scaling curve further downward. Empirically, we find that the optimal number of samples can be less than 10 under realistic assumptions (Fig. 1b). Finally, we show that beyond accuracy, false positives may have other undesirable qualities, such as poor adherence to coding style conventions.
Inference Scaling $\scriptsize\mathtt{F}$Laws: The Limits of LLM Resampling with Imperfect Verifiers
Nov 26, 2024Recent research has generated hope that inference scaling could allow weaker language models to match or exceed the accuracy of stronger models, such as by repeatedly sampling solutions to a coding problem until it passes unit tests. The central thesis of this paper is that there is no free lunch for inference scaling: indefinite accuracy improvement through resampling can only be realized if the "verifier" (in this case, a set of unit tests) is perfect. When the verifier is imperfect, as it almost always is in domains such as reasoning or coding (for example, unit tests have imperfect coverage), there is a nonzero probability of false positives: incorrect solutions that pass the verifier. Resampling cannot decrease this probability, so it imposes an upper bound to the accuracy of resampling-based inference scaling even with an infinite compute budget. We find that there is a very strong correlation between the model's single-sample accuracy (i.e. accuracy without unit tests) and its false positive rate on coding benchmarks HumanEval and MBPP, whose unit tests have limited coverage. Therefore, no amount of inference scaling of weaker models can enable them to match the single-sample accuracy of a sufficiently strong model (Fig. 1a). When we consider that false positives have a negative utility compared to abstaining from producing a solution, it bends the inference scaling curve further downward. Empirically, we find that the optimal number of samples can be less than 10 under realistic assumptions (Fig. 1b). Finally, we show that beyond accuracy, false positives may have other undesirable qualities, such as poor adherence to coding style conventions.
CORE-Bench: Fostering the Credibility of Published Research Through a Computational Reproducibility Agent Benchmark
Sep 17, 2024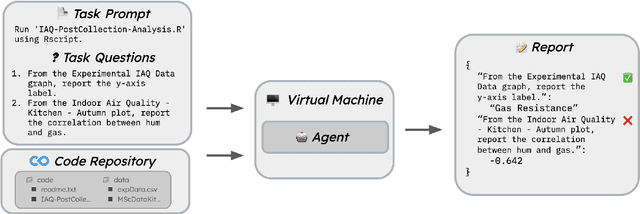
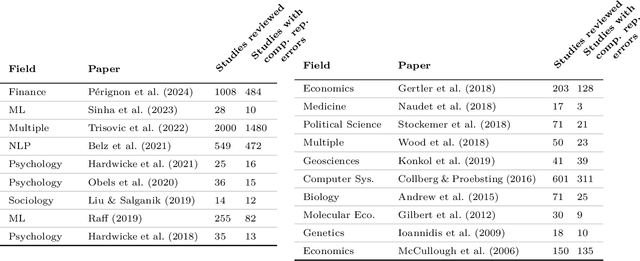

AI agents have the potential to aid users on a variety of consequential tasks, including conducting scientific research. To spur the development of useful agents, we need benchmarks that are challenging, but more crucially, directly correspond to real-world tasks of interest. This paper introduces such a benchmark, designed to measure the accuracy of AI agents in tackling a crucial yet surprisingly challenging aspect of scientific research: computational reproducibility. This task, fundamental to the scientific process, involves reproducing the results of a study using the provided code and data. We introduce CORE-Bench (Computational Reproducibility Agent Benchmark), a benchmark consisting of 270 tasks based on 90 scientific papers across three disciplines (computer science, social science, and medicine). Tasks in CORE-Bench consist of three difficulty levels and include both language-only and vision-language tasks. We provide an evaluation system to measure the accuracy of agents in a fast and parallelizable way, saving days of evaluation time for each run compared to a sequential implementation. We evaluated two baseline agents: the general-purpose AutoGPT and a task-specific agent called CORE-Agent. We tested both variants using two underlying language models: GPT-4o and GPT-4o-mini. The best agent achieved an accuracy of 21% on the hardest task, showing the vast scope for improvement in automating routine scientific tasks. Having agents that can reproduce existing work is a necessary step towards building agents that can conduct novel research and could verify and improve the performance of other research agents. We hope that CORE-Bench can improve the state of reproducibility and spur the development of future research agents.
AI Agents That Matter
Jul 01, 2024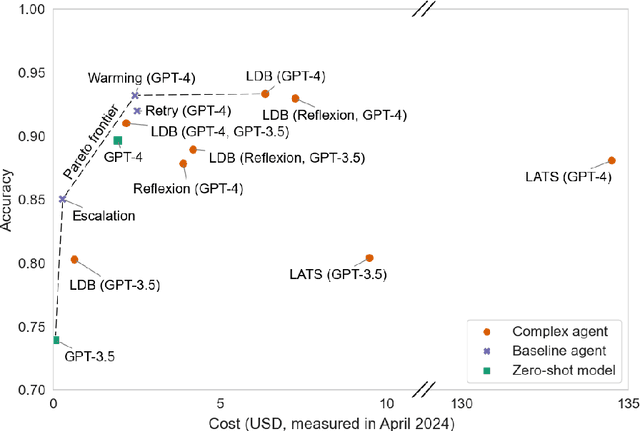

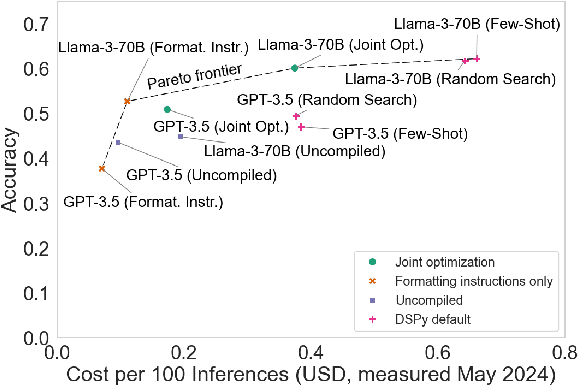
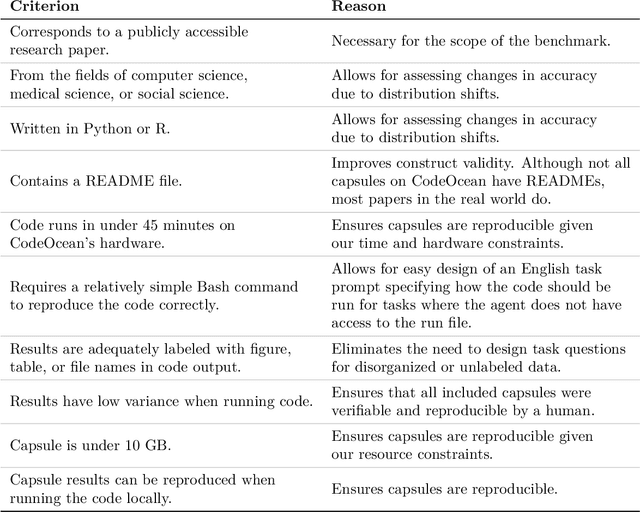
AI agents are an exciting new research direction, and agent development is driven by benchmarks. Our analysis of current agent benchmarks and evaluation practices reveals several shortcomings that hinder their usefulness in real-world applications. First, there is a narrow focus on accuracy without attention to other metrics. As a result, SOTA agents are needlessly complex and costly, and the community has reached mistaken conclusions about the sources of accuracy gains. Our focus on cost in addition to accuracy motivates the new goal of jointly optimizing the two metrics. We design and implement one such optimization, showing its potential to greatly reduce cost while maintaining accuracy. Second, the benchmarking needs of model and downstream developers have been conflated, making it hard to identify which agent would be best suited for a particular application. Third, many agent benchmarks have inadequate holdout sets, and sometimes none at all. This has led to agents that are fragile because they take shortcuts and overfit to the benchmark in various ways. We prescribe a principled framework for avoiding overfitting. Finally, there is a lack of standardization in evaluation practices, leading to a pervasive lack of reproducibility. We hope that the steps we introduce for addressing these shortcomings will spur the development of agents that are useful in the real world and not just accurate on benchmarks.