 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBest Practices for Biorisk Evaluations on Open-Weight Bio-Foundation Models
Nov 03, 2025Open-weight bio-foundation models present a dual-use dilemma. While holding great promise for accelerating scientific research and drug development, they could also enable bad actors to develop more deadly bioweapons. To mitigate the risk posed by these models, current approaches focus on filtering biohazardous data during pre-training. However, the effectiveness of such an approach remains unclear, particularly against determined actors who might fine-tune these models for malicious use. To address this gap, we propose \eval, a framework to evaluate the robustness of procedures that are intended to reduce the dual-use capabilities of bio-foundation models. \eval assesses models' virus understanding through three lenses, including sequence modeling, mutational effects prediction, and virulence prediction. Our results show that current filtering practices may not be particularly effective: Excluded knowledge can be rapidly recovered in some cases via fine-tuning, and exhibits broader generalizability in sequence modeling. Furthermore, dual-use signals may already reside in the pretrained representations, and can be elicited via simple linear probing. These findings highlight the challenges of data filtering as a standalone procedure, underscoring the need for further research into robust safety and security strategies for open-weight bio-foundation models.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025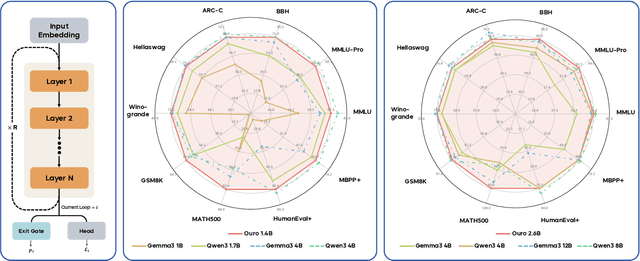
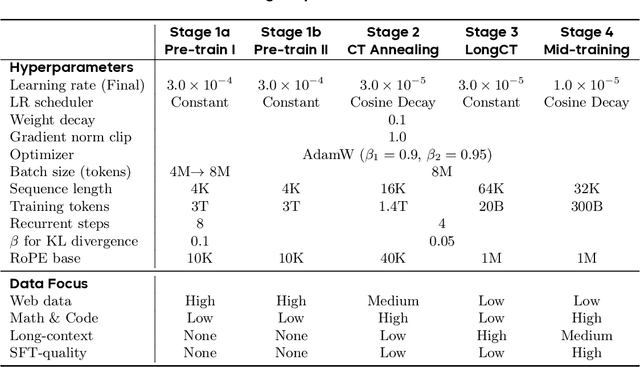
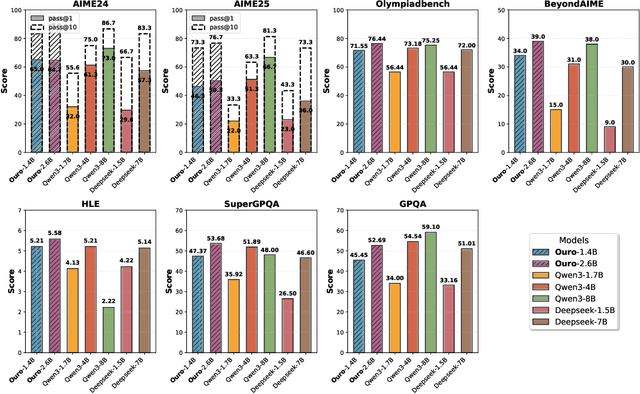

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
Dynamic Risk Assessments for Offensive Cybersecurity Agents
May 23, 2025



Foundation models are increasingly becoming better autonomous programmers, raising the prospect that they could also automate dangerous offensive cyber-operations. Current frontier model audits probe the cybersecurity risks of such agents, but most fail to account for the degrees of freedom available to adversaries in the real world. In particular, with strong verifiers and financial incentives, agents for offensive cybersecurity are amenable to iterative improvement by would-be adversaries. We argue that assessments should take into account an expanded threat model in the context of cybersecurity, emphasizing the varying degrees of freedom that an adversary may possess in stateful and non-stateful environments within a fixed compute budget. We show that even with a relatively small compute budget (8 H100 GPU Hours in our study), adversaries can improve an agent's cybersecurity capability on InterCode CTF by more than 40\% relative to the baseline -- without any external assistance. These results highlight the need to evaluate agents' cybersecurity risk in a dynamic manner, painting a more representative picture of risk.
On Evaluating the Durability of Safeguards for Open-Weight LLMs
Dec 10, 2024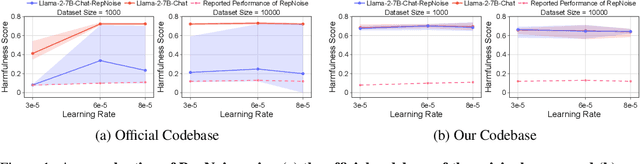

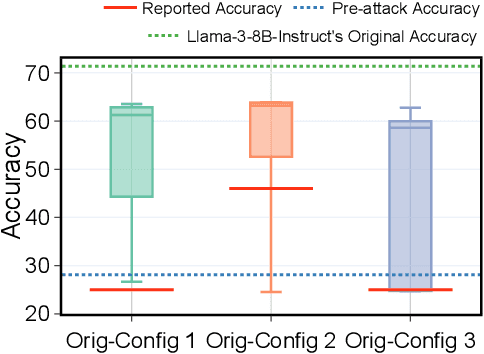
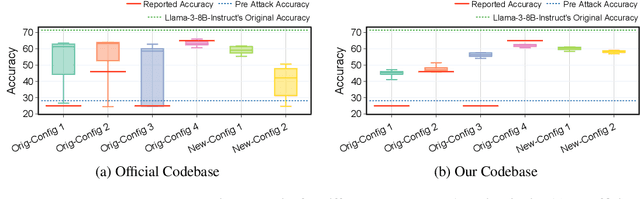
Stakeholders -- from model developers to policymakers -- seek to minimize the dual-use risks of large language models (LLMs). An open challenge to this goal is whether technical safeguards can impede the misuse of LLMs, even when models are customizable via fine-tuning or when model weights are fully open. In response, several recent studies have proposed methods to produce durable LLM safeguards for open-weight LLMs that can withstand adversarial modifications of the model's weights via fine-tuning. This holds the promise of raising adversaries' costs even under strong threat models where adversaries can directly fine-tune model weights. However, in this paper, we urge for more careful characterization of the limits of these approaches. Through several case studies, we demonstrate that even evaluating these defenses is exceedingly difficult and can easily mislead audiences into thinking that safeguards are more durable than they really are. We draw lessons from the evaluation pitfalls that we identify and suggest future research carefully cabin claims to more constrained, well-defined, and rigorously examined threat models, which can provide more useful and candid assessments to stakeholders.
An Adversarial Perspective on Machine Unlearning for AI Safety
Sep 26, 2024Large language models are finetuned to refuse questions about hazardous knowledge, but these protections can often be bypassed. Unlearning methods aim at completely removing hazardous capabilities from models and make them inaccessible to adversaries. This work challenges the fundamental differences between unlearning and traditional safety post-training from an adversarial perspective. We demonstrate that existing jailbreak methods, previously reported as ineffective against unlearning, can be successful when applied carefully. Furthermore, we develop a variety of adaptive methods that recover most supposedly unlearned capabilities. For instance, we show that finetuning on 10 unrelated examples or removing specific directions in the activation space can recover most hazardous capabilities for models edited with RMU, a state-of-the-art unlearning method. Our findings challenge the robustness of current unlearning approaches and question their advantages over safety training.
Evaluating Copyright Takedown Methods for Language Models
Jun 26, 2024



Language models (LMs) derive their capabilities from extensive training on diverse data, including potentially copyrighted material. These models can memorize and generate content similar to their training data, posing potential concerns. Therefore, model creators are motivated to develop mitigation methods that prevent generating protected content. We term this procedure as copyright takedowns for LMs, noting the conceptual similarity to (but legal distinction from) the DMCA takedown This paper introduces the first evaluation of the feasibility and side effects of copyright takedowns for LMs. We propose CoTaEval, an evaluation framework to assess the effectiveness of copyright takedown methods, the impact on the model's ability to retain uncopyrightable factual knowledge from the training data whose recitation is embargoed, and how well the model maintains its general utility and efficiency. We examine several strategies, including adding system prompts, decoding-time filtering interventions, and unlearning approaches. Our findings indicate that no tested method excels across all metrics, showing significant room for research in this unique problem setting and indicating potential unresolved challenges for live policy proposals.
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal Behaviors
Jun 20, 2024



Evaluating aligned large language models' (LLMs) ability to recognize and reject unsafe user requests is crucial for safe, policy-compliant deployments. Existing evaluation efforts, however, face three limitations that we address with SORRY-Bench, our proposed benchmark. First, existing methods often use coarse-grained taxonomies of unsafe topics, and are over-representing some fine-grained topics. For example, among the ten existing datasets that we evaluated, tests for refusals of self-harm instructions are over 3x less represented than tests for fraudulent activities. SORRY-Bench improves on this by using a fine-grained taxonomy of 45 potentially unsafe topics, and 450 class-balanced unsafe instructions, compiled through human-in-the-loop methods. Second, linguistic characteristics and formatting of prompts are often overlooked, like different languages, dialects, and more -- which are only implicitly considered in many evaluations. We supplement SORRY-Bench with 20 diverse linguistic augmentations to systematically examine these effects. Third, existing evaluations rely on large LLMs (e.g., GPT-4) for evaluation, which can be computationally expensive. We investigate design choices for creating a fast, accurate automated safety evaluator. By collecting 7K+ human annotations and conducting a meta-evaluation of diverse LLM-as-a-judge designs, we show that fine-tuned 7B LLMs can achieve accuracy comparable to GPT-4 scale LLMs, with lower computational cost. Putting these together, we evaluate over 40 proprietary and open-source LLMs on SORRY-Bench, analyzing their distinctive refusal behaviors. We hope our effort provides a building block for systematic evaluations of LLMs' safety refusal capabilities, in a balanced, granular, and efficient manner.
A Label-Free and Non-Monotonic Metric for Evaluating Denoising in Event Cameras
Jun 13, 2024
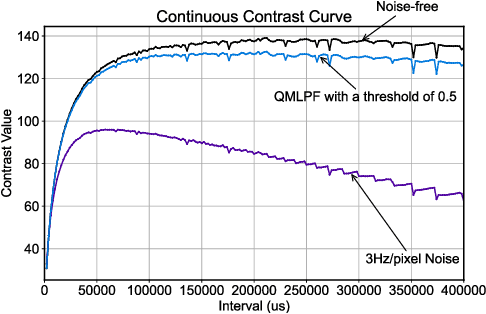
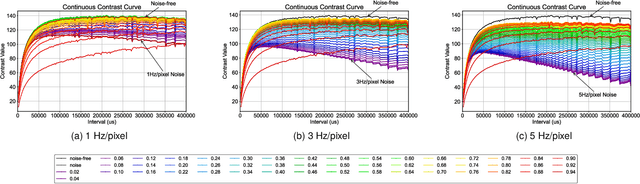
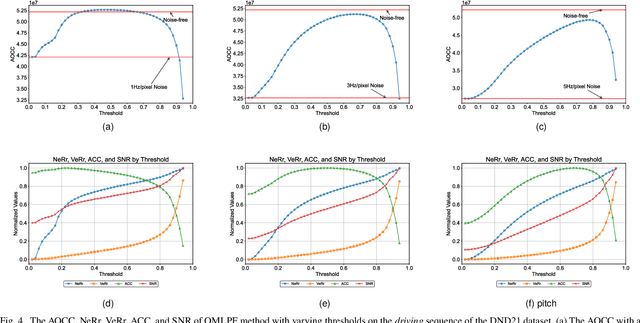
Event cameras are renowned for their high efficiency due to outputting a sparse, asynchronous stream of events. However, they are plagued by noisy events, especially in low light conditions. Denoising is an essential task for event cameras, but evaluating denoising performance is challenging. Label-dependent denoising metrics involve artificially adding noise to clean sequences, complicating evaluations. Moreover, the majority of these metrics are monotonic, which can inflate scores by removing substantial noise and valid events. To overcome these limitations, we propose the first label-free and non-monotonic evaluation metric, the area of the continuous contrast curve (AOCC), which utilizes the area enclosed by event frame contrast curves across different time intervals. This metric is inspired by how events capture the edge contours of scenes or objects with high temporal resolution. An effective denoising method removes noise without eliminating these edge-contour events, thus preserving the contrast of event frames. Consequently, contrast across various time ranges serves as a metric to assess denoising effectiveness. As the time interval lengthens, the curve will initially rise and then fall. The proposed metric is validated through both theoretical and experimental evidence.
AI Risk Management Should Incorporate Both Safety and Security
May 29, 2024
The exposure of security vulnerabilities in safety-aligned language models, e.g., susceptibility to adversarial attacks, has shed light on the intricate interplay between AI safety and AI security. Although the two disciplines now come together under the overarching goal of AI risk management, they have historically evolved separately, giving rise to differing perspectives. Therefore, in this paper, we advocate that stakeholders in AI risk management should be aware of the nuances, synergies, and interplay between safety and security, and unambiguously take into account the perspectives of both disciplines in order to devise mostly effective and holistic risk mitigation approaches. Unfortunately, this vision is often obfuscated, as the definitions of the basic concepts of "safety" and "security" themselves are often inconsistent and lack consensus across communities. With AI risk management being increasingly cross-disciplinary, this issue is particularly salient. In light of this conceptual challenge, we introduce a unified reference framework to clarify the differences and interplay between AI safety and AI security, aiming to facilitate a shared understanding and effective collaboration across communities.
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications
Feb 07, 2024



Large language models (LLMs) show inherent brittleness in their safety mechanisms, as evidenced by their susceptibility to jailbreaking and even non-malicious fine-tuning. This study explores this brittleness of safety alignment by leveraging pruning and low-rank modifications. We develop methods to identify critical regions that are vital for safety guardrails, and that are disentangled from utility-relevant regions at both the neuron and rank levels. Surprisingly, the isolated regions we find are sparse, comprising about $3\%$ at the parameter level and $2.5\%$ at the rank level. Removing these regions compromises safety without significantly impacting utility, corroborating the inherent brittleness of the model's safety mechanisms. Moreover, we show that LLMs remain vulnerable to low-cost fine-tuning attacks even when modifications to the safety-critical regions are restricted. These findings underscore the urgent need for more robust safety strategies in LLMs.