 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Mono3DVG-EnSD: Enhanced Spatial-aware and Dimension-decoupled Text Encoding for Monocular 3D Visual Grounding
Nov 10, 2025Monocular 3D Visual Grounding (Mono3DVG) is an emerging task that locates 3D objects in RGB images using text descriptions with geometric cues. However, existing methods face two key limitations. Firstly, they often over-rely on high-certainty keywords that explicitly identify the target object while neglecting critical spatial descriptions. Secondly, generalized textual features contain both 2D and 3D descriptive information, thereby capturing an additional dimension of details compared to singular 2D or 3D visual features. This characteristic leads to cross-dimensional interference when refining visual features under text guidance. To overcome these challenges, we propose Mono3DVG-EnSD, a novel framework that integrates two key components: the CLIP-Guided Lexical Certainty Adapter (CLIP-LCA) and the Dimension-Decoupled Module (D2M). The CLIP-LCA dynamically masks high-certainty keywords while retaining low-certainty implicit spatial descriptions, thereby forcing the model to develop a deeper understanding of spatial relationships in captions for object localization. Meanwhile, the D2M decouples dimension-specific (2D/3D) textual features from generalized textual features to guide corresponding visual features at same dimension, which mitigates cross-dimensional interference by ensuring dimensionally-consistent cross-modal interactions. Through comprehensive comparisons and ablation studies on the Mono3DRefer dataset, our method achieves state-of-the-art (SOTA) performance across all metrics. Notably, it improves the challenging Far(Acc@0.5) scenario by a significant +13.54%.
A Dual-stage Prompt-driven Privacy-preserving Paradigm for Person Re-Identification
Nov 07, 2025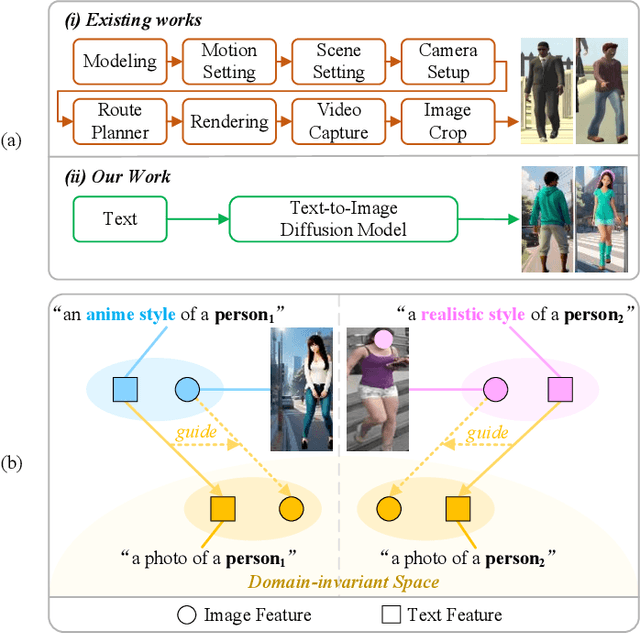
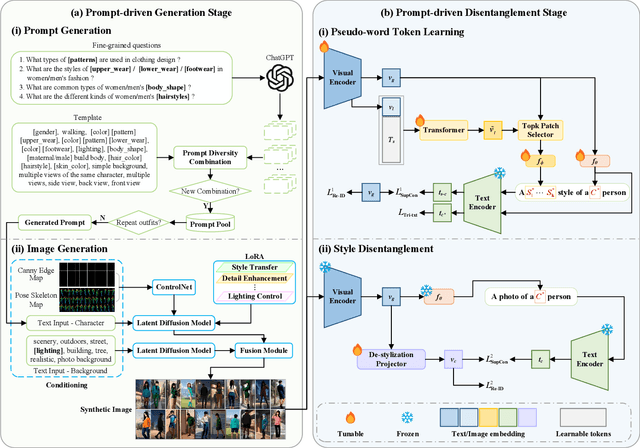
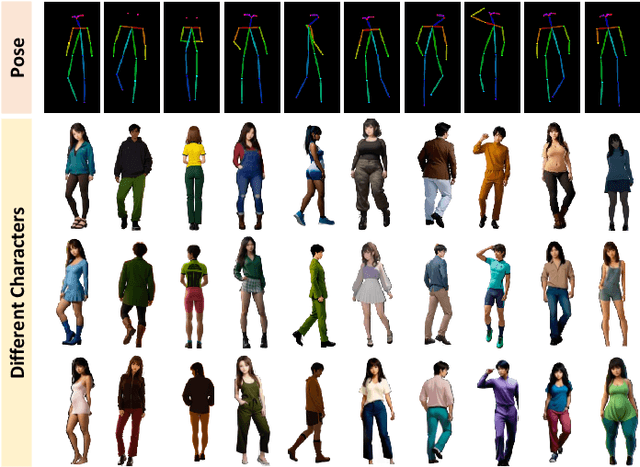

With growing concerns over data privacy, researchers have started using virtual data as an alternative to sensitive real-world images for training person re-identification (Re-ID) models. However, existing virtual datasets produced by game engines still face challenges such as complex construction and poor domain generalization, making them difficult to apply in real scenarios. To address these challenges, we propose a Dual-stage Prompt-driven Privacy-preserving Paradigm (DPPP). In the first stage, we generate rich prompts incorporating multi-dimensional attributes such as pedestrian appearance, illumination, and viewpoint that drive the diffusion model to synthesize diverse data end-to-end, building a large-scale virtual dataset named GenePerson with 130,519 images of 6,641 identities. In the second stage, we propose a Prompt-driven Disentanglement Mechanism (PDM) to learn domain-invariant generalization features. With the aid of contrastive learning, we employ two textual inversion networks to map images into pseudo-words representing style and content, respectively, thereby constructing style-disentangled content prompts to guide the model in learning domain-invariant content features at the image level. Experiments demonstrate that models trained on GenePerson with PDM achieve state-of-the-art generalization performance, surpassing those on popular real and virtual Re-ID datasets.
Dual Enhancement on 3D Vision-Language Perception for Monocular 3D Visual Grounding
Aug 26, 2025Monocular 3D visual grounding is a novel task that aims to locate 3D objects in RGB images using text descriptions with explicit geometry information. Despite the inclusion of geometry details in the text, we observe that the text embeddings are sensitive to the magnitude of numerical values but largely ignore the associated measurement units. For example, simply equidistant mapping the length with unit "meter" to "decimeters" or "centimeters" leads to severe performance degradation, even though the physical length remains equivalent. This observation signifies the weak 3D comprehension of pre-trained language model, which generates misguiding text features to hinder 3D perception. Therefore, we propose to enhance the 3D perception of model on text embeddings and geometry features with two simple and effective methods. Firstly, we introduce a pre-processing method named 3D-text Enhancement (3DTE), which enhances the comprehension of mapping relationships between different units by augmenting the diversity of distance descriptors in text queries. Next, we propose a Text-Guided Geometry Enhancement (TGE) module to further enhance the 3D-text information by projecting the basic text features into geometrically consistent space. These 3D-enhanced text features are then leveraged to precisely guide the attention of geometry features. We evaluate the proposed method through extensive comparisons and ablation studies on the Mono3DRefer dataset. Experimental results demonstrate substantial improvements over previous methods, achieving new state-of-the-art results with a notable accuracy gain of 11.94\% in the "Far" scenario. Our code will be made publicly available.
Structure and Smoothness Constrained Dual Networks for MR Bias Field Correction
Jul 02, 2025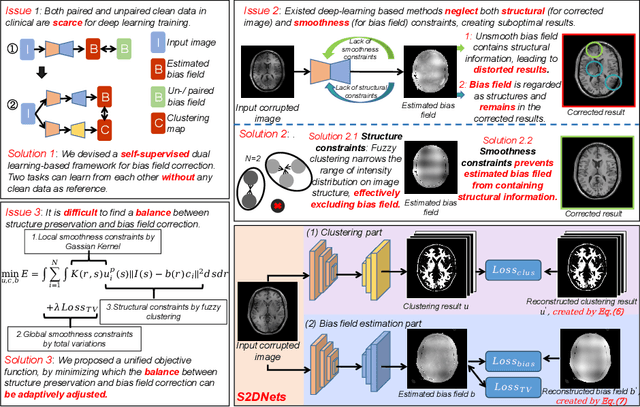
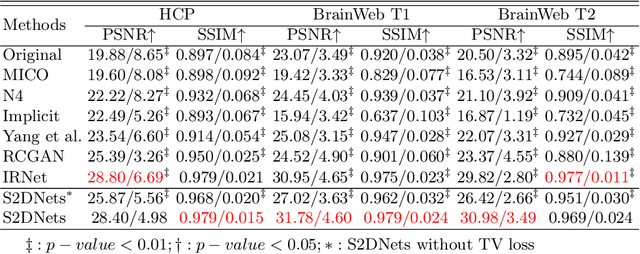
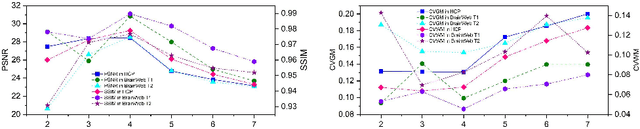
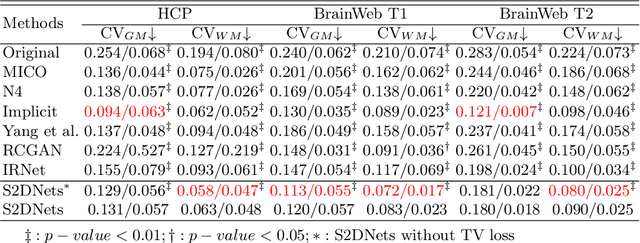
MR imaging techniques are of great benefit to disease diagnosis. However, due to the limitation of MR devices, significant intensity inhomogeneity often exists in imaging results, which impedes both qualitative and quantitative medical analysis. Recently, several unsupervised deep learning-based models have been proposed for MR image improvement. However, these models merely concentrate on global appearance learning, and neglect constraints from image structures and smoothness of bias field, leading to distorted corrected results. In this paper, novel structure and smoothness constrained dual networks, named S2DNets, are proposed aiming to self-supervised bias field correction. S2DNets introduce piece-wise structural constraints and smoothness of bias field for network training to effectively remove non-uniform intensity and retain much more structural details. Extensive experiments executed on both clinical and simulated MR datasets show that the proposed model outperforms other conventional and deep learning-based models. In addition to comparison on visual metrics, downstream MR image segmentation tasks are also used to evaluate the impact of the proposed model. The source code is available at: https://github.com/LeongDong/S2DNets}{https://github.com/LeongDong/S2DNets.
* 11 pages, 3 figures, accepted by MICCAI
GRFormer: Grouped Residual Self-Attention for Lightweight Single Image Super-Resolution
Aug 14, 2024Previous works have shown that reducing parameter overhead and computations for transformer-based single image super-resolution (SISR) models (e.g., SwinIR) usually leads to a reduction of performance. In this paper, we present GRFormer, an efficient and lightweight method, which not only reduces the parameter overhead and computations, but also greatly improves performance. The core of GRFormer is Grouped Residual Self-Attention (GRSA), which is specifically oriented towards two fundamental components. Firstly, it introduces a novel grouped residual layer (GRL) to replace the Query, Key, Value (QKV) linear layer in self-attention, aimed at efficiently reducing parameter overhead, computations, and performance loss at the same time. Secondly, it integrates a compact Exponential-Space Relative Position Bias (ES-RPB) as a substitute for the original relative position bias to improve the ability to represent position information while further minimizing the parameter count. Extensive experimental results demonstrate that GRFormer outperforms state-of-the-art transformer-based methods for $\times$2, $\times$3 and $\times$4 SISR tasks, notably outperforming SOTA by a maximum PSNR of 0.23dB when trained on the DIV2K dataset, while reducing the number of parameter and MACs by about \textbf{60\%} and \textbf{49\% } in only self-attention module respectively. We hope that our simple and effective method that can easily applied to SR models based on window-division self-attention can serve as a useful tool for further research in image super-resolution. The code is available at \url{https://github.com/sisrformer/GRFormer}.
IDO-VFI: Identifying Dynamics via Optical Flow Guidance for Video Frame Interpolation with Events
May 18, 2023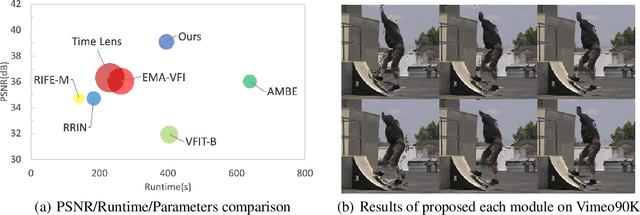
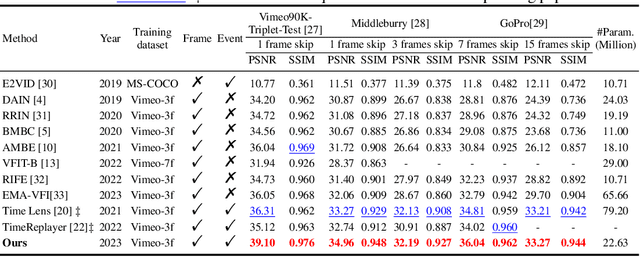

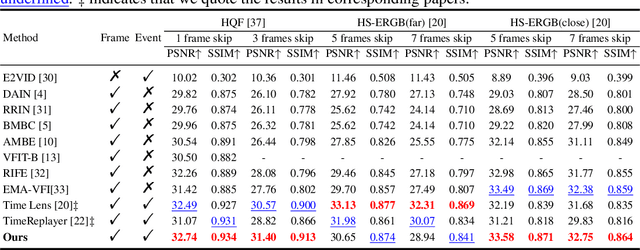
Video frame interpolation aims to generate high-quality intermediate frames from boundary frames and increase frame rate. While existing linear, symmetric and nonlinear models are used to bridge the gap from the lack of inter-frame motion, they cannot reconstruct real motions. Event cameras, however, are ideal for capturing inter-frame dynamics with their extremely high temporal resolution. In this paper, we propose an event-and-frame-based video frame interpolation method named IDO-VFI that assigns varying amounts of computation for different sub-regions via optical flow guidance. The proposed method first estimates the optical flow based on frames and events, and then decides whether to further calculate the residual optical flow in those sub-regions via a Gumbel gating module according to the optical flow amplitude. Intermediate frames are eventually generated through a concise Transformer-based fusion network. Our proposed method maintains high-quality performance while reducing computation time and computational effort by 10% and 17% respectively on Vimeo90K datasets, compared with a unified process on the whole region. Moreover, our method outperforms state-of-the-art frame-only and frames-plus-events methods on multiple video frame interpolation benchmarks. Codes and models are available at https://github.com/shicy17/IDO-VFI.