 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoSTF: Stress-Testing Output Repetition in Video Large Language Models
Feb 11, 2026Video Large Language Models (VideoLLMs) have recently achieved strong performance in video understanding tasks. However, we identify a previously underexplored generation failure: severe output repetition, where models degenerate into self-reinforcing loops of repeated phrases or sentences. This failure mode is not captured by existing VideoLLM benchmarks, which focus primarily on task accuracy and factual correctness. We introduce VideoSTF, the first framework for systematically measuring and stress-testing output repetition in VideoLLMs. VideoSTF formalizes repetition using three complementary n-gram-based metrics and provides a standardized testbed of 10,000 diverse videos together with a library of controlled temporal transformations. Using VideoSTF, we conduct pervasive testing, temporal stress testing, and adversarial exploitation across 10 advanced VideoLLMs. We find that output repetition is widespread and, critically, highly sensitive to temporal perturbations of video inputs. Moreover, we show that simple temporal transformations can efficiently induce repetitive degeneration in a black-box setting, exposing output repetition as an exploitable security vulnerability. Our results reveal output repetition as a fundamental stability issue in modern VideoLLMs and motivate stability-aware evaluation for video-language systems. Our evaluation code and scripts are available at: https://github.com/yuxincao22/VideoSTF_benchmark.
E2E-VGuard: Adversarial Prevention for Production LLM-based End-To-End Speech Synthesis
Nov 10, 2025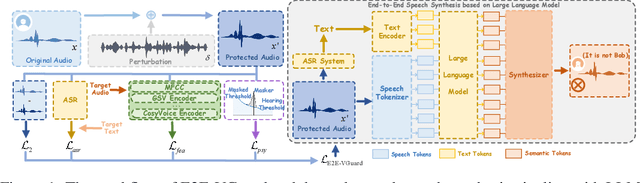
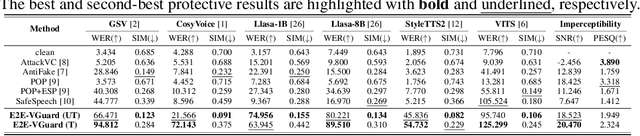

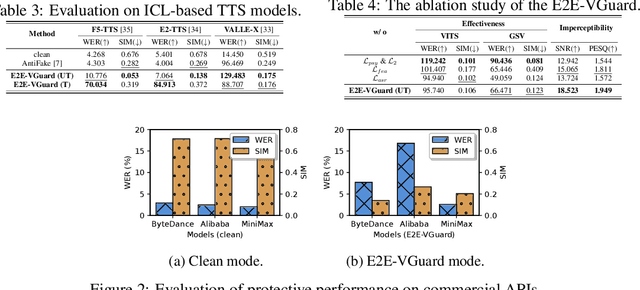
Recent advancements in speech synthesis technology have enriched our daily lives, with high-quality and human-like audio widely adopted across real-world applications. However, malicious exploitation like voice-cloning fraud poses severe security risks. Existing defense techniques struggle to address the production large language model (LLM)-based speech synthesis. While previous studies have considered the protection for fine-tuning synthesizers, they assume manually annotated transcripts. Given the labor intensity of manual annotation, end-to-end (E2E) systems leveraging automatic speech recognition (ASR) to generate transcripts are becoming increasingly prevalent, e.g., voice cloning via commercial APIs. Therefore, this E2E speech synthesis also requires new security mechanisms. To tackle these challenges, we propose E2E-VGuard, a proactive defense framework for two emerging threats: (1) production LLM-based speech synthesis, and (2) the novel attack arising from ASR-driven E2E scenarios. Specifically, we employ the encoder ensemble with a feature extractor to protect timbre, while ASR-targeted adversarial examples disrupt pronunciation. Moreover, we incorporate the psychoacoustic model to ensure perturbative imperceptibility. For a comprehensive evaluation, we test 16 open-source synthesizers and 3 commercial APIs across Chinese and English datasets, confirming E2E-VGuard's effectiveness in timbre and pronunciation protection. Real-world deployment validation is also conducted. Our code and demo page are available at https://wxzyd123.github.io/e2e-vguard/.
ALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.
Intriguing Frequency Interpretation of Adversarial Robustness for CNNs and ViTs
Jun 15, 2025Adversarial examples have attracted significant attention over the years, yet understanding their frequency-based characteristics remains insufficient. In this paper, we investigate the intriguing properties of adversarial examples in the frequency domain for the image classification task, with the following key findings. (1) As the high-frequency components increase, the performance gap between adversarial and natural examples becomes increasingly pronounced. (2) The model performance against filtered adversarial examples initially increases to a peak and declines to its inherent robustness. (3) In Convolutional Neural Networks, mid- and high-frequency components of adversarial examples exhibit their attack capabilities, while in Transformers, low- and mid-frequency components of adversarial examples are particularly effective. These results suggest that different network architectures have different frequency preferences and that differences in frequency components between adversarial and natural examples may directly influence model robustness. Based on our findings, we further conclude with three useful proposals that serve as a valuable reference to the AI model security community.
SafeSpeech: Robust and Universal Voice Protection Against Malicious Speech Synthesis
Apr 14, 2025



Speech synthesis technology has brought great convenience, while the widespread usage of realistic deepfake audio has triggered hazards. Malicious adversaries may unauthorizedly collect victims' speeches and clone a similar voice for illegal exploitation (\textit{e.g.}, telecom fraud). However, the existing defense methods cannot effectively prevent deepfake exploitation and are vulnerable to robust training techniques. Therefore, a more effective and robust data protection method is urgently needed. In response, we propose a defensive framework, \textit{\textbf{SafeSpeech}}, which protects the users' audio before uploading by embedding imperceptible perturbations on original speeches to prevent high-quality synthetic speech. In SafeSpeech, we devise a robust and universal proactive protection technique, \textbf{S}peech \textbf{PE}rturbative \textbf{C}oncealment (\textbf{SPEC}), that leverages a surrogate model to generate universally applicable perturbation for generative synthetic models. Moreover, we optimize the human perception of embedded perturbation in terms of time and frequency domains. To evaluate our method comprehensively, we conduct extensive experiments across advanced models and datasets, both subjectively and objectively. Our experimental results demonstrate that SafeSpeech achieves state-of-the-art (SOTA) voice protection effectiveness and transferability and is highly robust against advanced adaptive adversaries. Moreover, SafeSpeech has real-time capability in real-world tests. The source code is available at \href{https://github.com/wxzyd123/SafeSpeech}{https://github.com/wxzyd123/SafeSpeech}.
Whispering Under the Eaves: Protecting User Privacy Against Commercial and LLM-powered Automatic Speech Recognition Systems
Apr 01, 2025The widespread application of automatic speech recognition (ASR) supports large-scale voice surveillance, raising concerns about privacy among users. In this paper, we concentrate on using adversarial examples to mitigate unauthorized disclosure of speech privacy thwarted by potential eavesdroppers in speech communications. While audio adversarial examples have demonstrated the capability to mislead ASR models or evade ASR surveillance, they are typically constructed through time-intensive offline optimization, restricting their practicality in real-time voice communication. Recent work overcame this limitation by generating universal adversarial perturbations (UAPs) and enhancing their transferability for black-box scenarios. However, they introduced excessive noise that significantly degrades audio quality and affects human perception, thereby limiting their effectiveness in practical scenarios. To address this limitation and protect live users' speech against ASR systems, we propose a novel framework, AudioShield. Central to this framework is the concept of Transferable Universal Adversarial Perturbations in the Latent Space (LS-TUAP). By transferring the perturbations to the latent space, the audio quality is preserved to a large extent. Additionally, we propose target feature adaptation to enhance the transferability of UAPs by embedding target text features into the perturbations. Comprehensive evaluation on four commercial ASR APIs (Google, Amazon, iFlytek, and Alibaba), three voice assistants, two LLM-powered ASR and one NN-based ASR demonstrates the protection superiority of AudioShield over existing competitors, and both objective and subjective evaluations indicate that AudioShield significantly improves the audio quality. Moreover, AudioShield also shows high effectiveness in real-time end-to-end scenarios, and demonstrates strong resilience against adaptive countermeasures.
Mitigating Unauthorized Speech Synthesis for Voice Protection
Oct 28, 2024

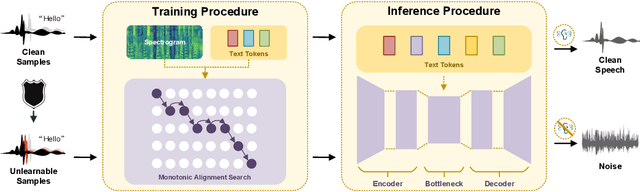

With just a few speech samples, it is possible to perfectly replicate a speaker's voice in recent years, while malicious voice exploitation (e.g., telecom fraud for illegal financial gain) has brought huge hazards in our daily lives. Therefore, it is crucial to protect publicly accessible speech data that contains sensitive information, such as personal voiceprints. Most previous defense methods have focused on spoofing speaker verification systems in timbre similarity but the synthesized deepfake speech is still of high quality. In response to the rising hazards, we devise an effective, transferable, and robust proactive protection technology named Pivotal Objective Perturbation (POP) that applies imperceptible error-minimizing noises on original speech samples to prevent them from being effectively learned for text-to-speech (TTS) synthesis models so that high-quality deepfake speeches cannot be generated. We conduct extensive experiments on state-of-the-art (SOTA) TTS models utilizing objective and subjective metrics to comprehensively evaluate our proposed method. The experimental results demonstrate outstanding effectiveness and transferability across various models. Compared to the speech unclarity score of 21.94% from voice synthesizers trained on samples without protection, POP-protected samples significantly increase it to 127.31%. Moreover, our method shows robustness against noise reduction and data augmentation techniques, thereby greatly reducing potential hazards.
Query-Efficient Video Adversarial Attack with Stylized Logo
Aug 22, 2024Video classification systems based on Deep Neural Networks (DNNs) have demonstrated excellent performance in accurately verifying video content. However, recent studies have shown that DNNs are highly vulnerable to adversarial examples. Therefore, a deep understanding of adversarial attacks can better respond to emergency situations. In order to improve attack performance, many style-transfer-based attacks and patch-based attacks have been proposed. However, the global perturbation of the former will bring unnatural global color, while the latter is difficult to achieve success in targeted attacks due to the limited perturbation space. Moreover, compared to a plethora of methods targeting image classifiers, video adversarial attacks are still not that popular. Therefore, to generate adversarial examples with a low budget and to provide them with a higher verisimilitude, we propose a novel black-box video attack framework, called Stylized Logo Attack (SLA). SLA is conducted through three steps. The first step involves building a style references set for logos, which can not only make the generated examples more natural, but also carry more target class features in the targeted attacks. Then, reinforcement learning (RL) is employed to determine the style reference and position parameters of the logo within the video, which ensures that the stylized logo is placed in the video with optimal attributes. Finally, perturbation optimization is designed to optimize perturbations to improve the fooling rate in a step-by-step manner. Sufficient experimental results indicate that, SLA can achieve better performance than state-of-the-art methods and still maintain good deception effects when facing various defense methods.
GRFormer: Grouped Residual Self-Attention for Lightweight Single Image Super-Resolution
Aug 14, 2024


Previous works have shown that reducing parameter overhead and computations for transformer-based single image super-resolution (SISR) models (e.g., SwinIR) usually leads to a reduction of performance. In this paper, we present GRFormer, an efficient and lightweight method, which not only reduces the parameter overhead and computations, but also greatly improves performance. The core of GRFormer is Grouped Residual Self-Attention (GRSA), which is specifically oriented towards two fundamental components. Firstly, it introduces a novel grouped residual layer (GRL) to replace the Query, Key, Value (QKV) linear layer in self-attention, aimed at efficiently reducing parameter overhead, computations, and performance loss at the same time. Secondly, it integrates a compact Exponential-Space Relative Position Bias (ES-RPB) as a substitute for the original relative position bias to improve the ability to represent position information while further minimizing the parameter count. Extensive experimental results demonstrate that GRFormer outperforms state-of-the-art transformer-based methods for $\times$2, $\times$3 and $\times$4 SISR tasks, notably outperforming SOTA by a maximum PSNR of 0.23dB when trained on the DIV2K dataset, while reducing the number of parameter and MACs by about \textbf{60\%} and \textbf{49\% } in only self-attention module respectively. We hope that our simple and effective method that can easily applied to SR models based on window-division self-attention can serve as a useful tool for further research in image super-resolution. The code is available at \url{https://github.com/sisrformer/GRFormer}.
Rethinking the Threat and Accessibility of Adversarial Attacks against Face Recognition Systems
Jul 11, 2024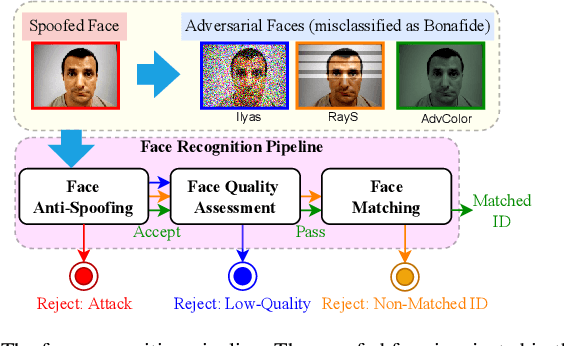
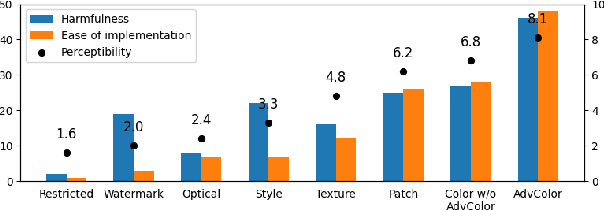
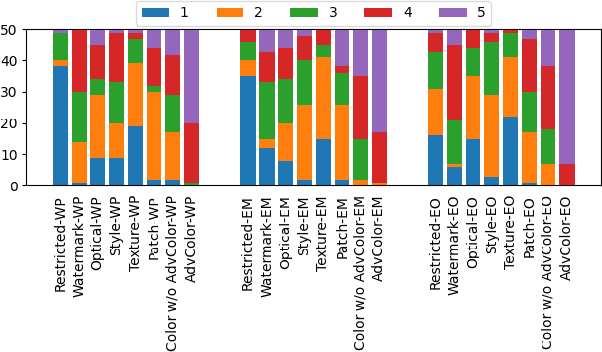

Face recognition pipelines have been widely deployed in various mission-critical systems in trust, equitable and responsible AI applications. However, the emergence of adversarial attacks has threatened the security of the entire recognition pipeline. Despite the sheer number of attack methods proposed for crafting adversarial examples in both digital and physical forms, it is never an easy task to assess the real threat level of different attacks and obtain useful insight into the key risks confronted by face recognition systems. Traditional attacks view imperceptibility as the most important measurement to keep perturbations stealthy, while we suspect that industry professionals may possess a different opinion. In this paper, we delve into measuring the threat brought about by adversarial attacks from the perspectives of the industry and the applications of face recognition. In contrast to widely studied sophisticated attacks in the field, we propose an effective yet easy-to-launch physical adversarial attack, named AdvColor, against black-box face recognition pipelines in the physical world. AdvColor fools models in the recognition pipeline via directly supplying printed photos of human faces to the system under adversarial illuminations. Experimental results show that physical AdvColor examples can achieve a fooling rate of more than 96% against the anti-spoofing model and an overall attack success rate of 88% against the face recognition pipeline. We also conduct a survey on the threats of prevailing adversarial attacks, including AdvColor, to understand the gap between the machine-measured and human-assessed threat levels of different forms of adversarial attacks. The survey results surprisingly indicate that, compared to deliberately launched imperceptible attacks, perceptible but accessible attacks pose more lethal threats to real-world commercial systems of face recognition.