 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.
Whispering Under the Eaves: Protecting User Privacy Against Commercial and LLM-powered Automatic Speech Recognition Systems
Apr 01, 2025The widespread application of automatic speech recognition (ASR) supports large-scale voice surveillance, raising concerns about privacy among users. In this paper, we concentrate on using adversarial examples to mitigate unauthorized disclosure of speech privacy thwarted by potential eavesdroppers in speech communications. While audio adversarial examples have demonstrated the capability to mislead ASR models or evade ASR surveillance, they are typically constructed through time-intensive offline optimization, restricting their practicality in real-time voice communication. Recent work overcame this limitation by generating universal adversarial perturbations (UAPs) and enhancing their transferability for black-box scenarios. However, they introduced excessive noise that significantly degrades audio quality and affects human perception, thereby limiting their effectiveness in practical scenarios. To address this limitation and protect live users' speech against ASR systems, we propose a novel framework, AudioShield. Central to this framework is the concept of Transferable Universal Adversarial Perturbations in the Latent Space (LS-TUAP). By transferring the perturbations to the latent space, the audio quality is preserved to a large extent. Additionally, we propose target feature adaptation to enhance the transferability of UAPs by embedding target text features into the perturbations. Comprehensive evaluation on four commercial ASR APIs (Google, Amazon, iFlytek, and Alibaba), three voice assistants, two LLM-powered ASR and one NN-based ASR demonstrates the protection superiority of AudioShield over existing competitors, and both objective and subjective evaluations indicate that AudioShield significantly improves the audio quality. Moreover, AudioShield also shows high effectiveness in real-time end-to-end scenarios, and demonstrates strong resilience against adaptive countermeasures.
Boosting the Transferability of Audio Adversarial Examples with Acoustic Representation Optimization
Mar 25, 2025With the widespread application of automatic speech recognition (ASR) systems, their vulnerability to adversarial attacks has been extensively studied. However, most existing adversarial examples are generated on specific individual models, resulting in a lack of transferability. In real-world scenarios, attackers often cannot access detailed information about the target model, making query-based attacks unfeasible. To address this challenge, we propose a technique called Acoustic Representation Optimization that aligns adversarial perturbations with low-level acoustic characteristics derived from speech representation models. Rather than relying on model-specific, higher-layer abstractions, our approach leverages fundamental acoustic representations that remain consistent across diverse ASR architectures. By enforcing an acoustic representation loss to guide perturbations toward these robust, lower-level representations, we enhance the cross-model transferability of adversarial examples without degrading audio quality. Our method is plug-and-play and can be integrated with any existing attack methods. We evaluate our approach on three modern ASR models, and the experimental results demonstrate that our method significantly improves the transferability of adversarial examples generated by previous methods while preserving the audio quality.
Towards Evaluating the Robustness of Automatic Speech Recognition Systems via Audio Style Transfer
May 15, 2024



In light of the widespread application of Automatic Speech Recognition (ASR) systems, their security concerns have received much more attention than ever before, primarily due to the susceptibility of Deep Neural Networks. Previous studies have illustrated that surreptitiously crafting adversarial perturbations enables the manipulation of speech recognition systems, resulting in the production of malicious commands. These attack methods mostly require adding noise perturbations under $\ell_p$ norm constraints, inevitably leaving behind artifacts of manual modifications. Recent research has alleviated this limitation by manipulating style vectors to synthesize adversarial examples based on Text-to-Speech (TTS) synthesis audio. However, style modifications based on optimization objectives significantly reduce the controllability and editability of audio styles. In this paper, we propose an attack on ASR systems based on user-customized style transfer. We first test the effect of Style Transfer Attack (STA) which combines style transfer and adversarial attack in sequential order. And then, as an improvement, we propose an iterative Style Code Attack (SCA) to maintain audio quality. Experimental results show that our method can meet the need for user-customized styles and achieve a success rate of 82% in attacks, while keeping sound naturalness due to our user study.
An Analog Neural Network Computing Engine using CMOS-Compatible Charge-Trap-Transistor (CTT)
Aug 09, 2018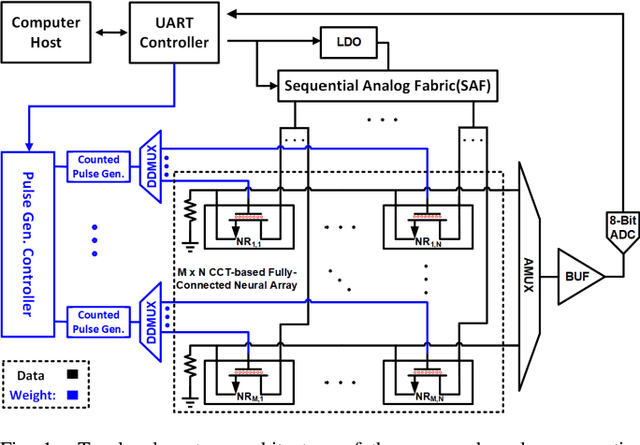
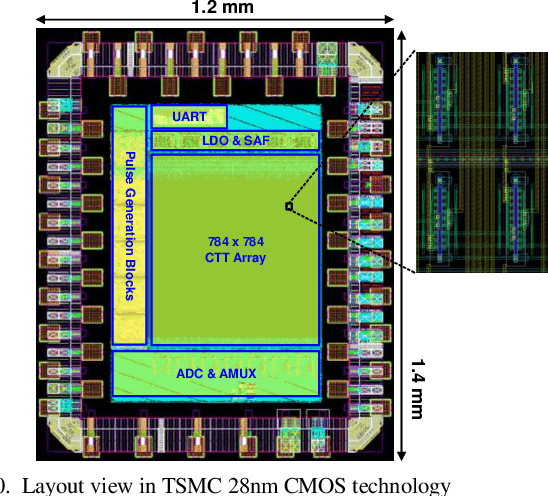
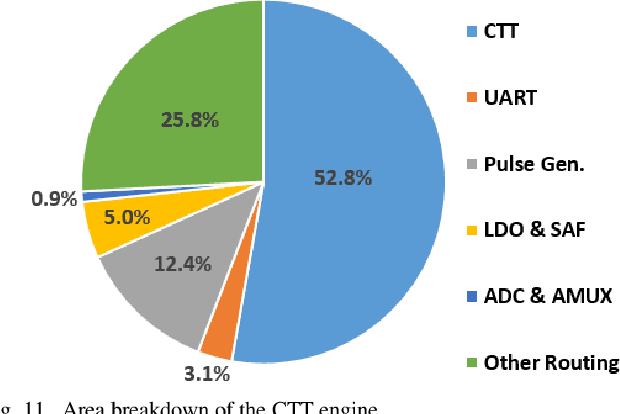
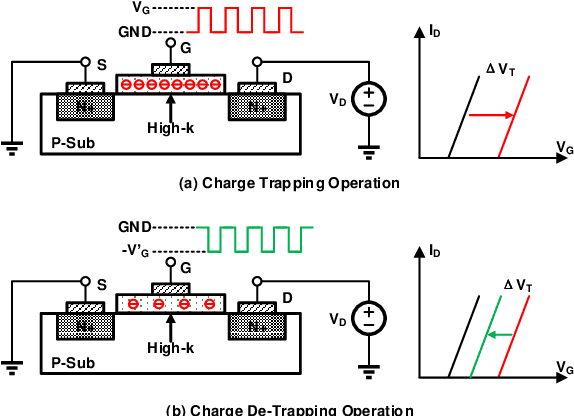
An analog neural network computing engine based on CMOS-compatible charge-trap transistor (CTT) is proposed in this paper. CTT devices are used as analog multipliers. Compared to digital multipliers, CTT-based analog multiplier shows significant area and power reduction. The proposed computing engine is composed of a scalable CTT multiplier array and energy efficient analog-digital interfaces. Through implementing the sequential analog fabric (SAF), the engine mixed-signal interfaces are simplified and hardware overhead remains constant regardless of the size of the array. A proof-of-concept 784 by 784 CTT computing engine is implemented using TSMC 28nm CMOS technology and occupied 0.68mm2. The simulated performance achieves 76.8 TOPS (8-bit) with 500 MHz clock frequency and consumes 14.8 mW. As an example, we utilize this computing engine to address a classic pattern recognition problem -- classifying handwritten digits on MNIST database and obtained a performance comparable to state-of-the-art fully connected neural networks using 8-bit fixed-point resolution.
A Streaming Accelerator for Deep Convolutional Neural Networks with Image and Feature Decomposition for Resource-limited System Applications
Sep 15, 2017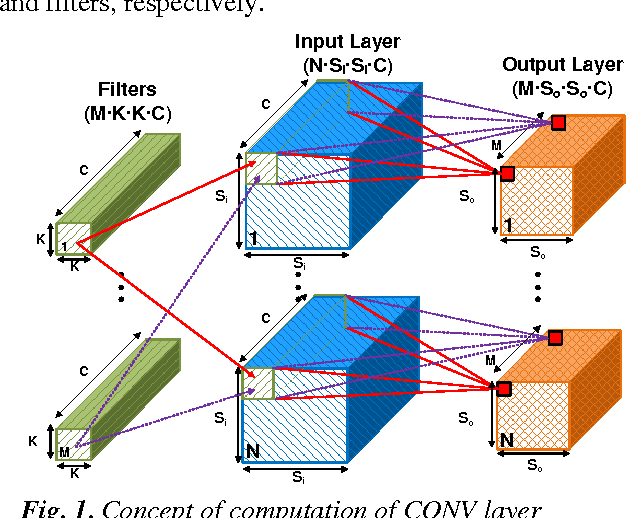
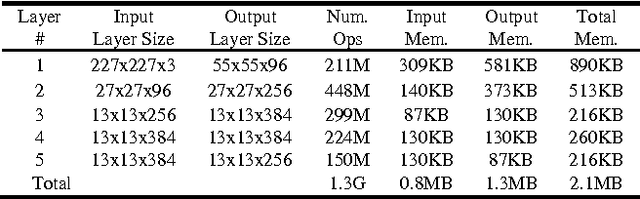
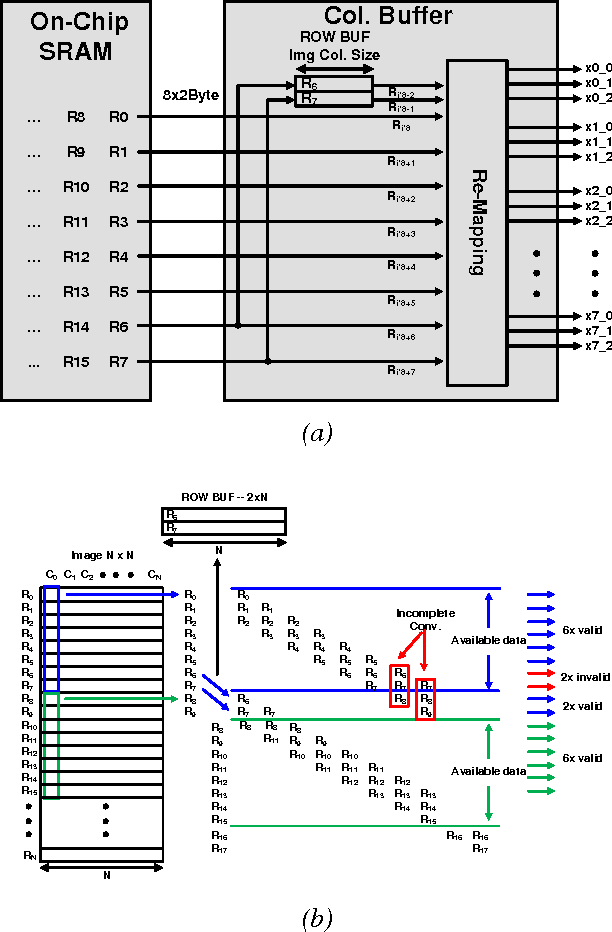
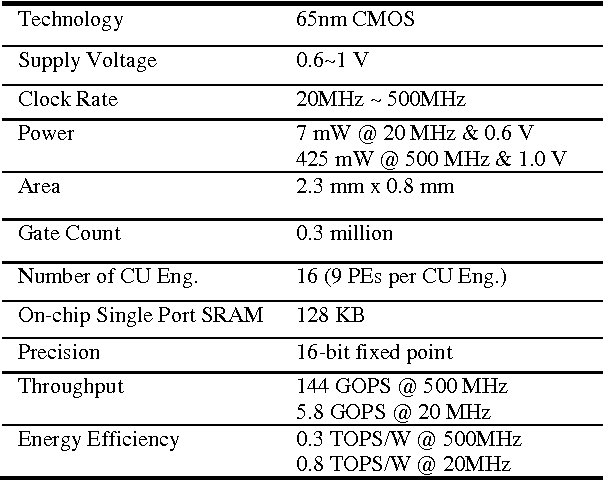
Deep convolutional neural networks (CNN) are widely used in modern artificial intelligence (AI) and smart vision systems but also limited by computation latency, throughput, and energy efficiency on a resource-limited scenario, such as mobile devices, internet of things (IoT), unmanned aerial vehicles (UAV), and so on. A hardware streaming architecture is proposed to accelerate convolution and pooling computations for state-of-the-art deep CNNs. It is optimized for energy efficiency by maximizing local data reuse to reduce off-chip DRAM data access. In addition, image and feature decomposition techniques are introduced to optimize memory access pattern for an arbitrary size of image and number of features within limited on-chip SRAM capacity. A prototype accelerator was implemented in TSMC 65 nm CMOS technology with 2.3 mm x 0.8 mm core area, which achieves 144 GOPS peak throughput and 0.8 TOPS/W peak energy efficiency.