 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMGuard: Safety Shortcuts and Where to Find Them as Guardrails for Audio-Language Models
Oct 30, 2025Recent advances in Audio-Language Models (ALMs) have significantly improved multimodal understanding capabilities. However, the introduction of the audio modality also brings new and unique vulnerability vectors. Previous studies have proposed jailbreak attacks that specifically target ALMs, revealing that defenses directly transferred from traditional audio adversarial attacks or text-based Large Language Model (LLM) jailbreaks are largely ineffective against these ALM-specific threats. To address this issue, we propose ALMGuard, the first defense framework tailored to ALMs. Based on the assumption that safety-aligned shortcuts naturally exist in ALMs, we design a method to identify universal Shortcut Activation Perturbations (SAPs) that serve as triggers that activate the safety shortcuts to safeguard ALMs at inference time. To better sift out effective triggers while preserving the model's utility on benign tasks, we further propose Mel-Gradient Sparse Mask (M-GSM), which restricts perturbations to Mel-frequency bins that are sensitive to jailbreaks but insensitive to speech understanding. Both theoretical analyses and empirical results demonstrate the robustness of our method against both seen and unseen attacks. Overall, \MethodName reduces the average success rate of advanced ALM-specific jailbreak attacks to 4.6% across four models, while maintaining comparable utility on benign benchmarks, establishing it as the new state of the art. Our code and data are available at https://github.com/WeifeiJin/ALMGuard.
A Comprehensive Survey in LLM(-Agent) Full Stack Safety: Data, Training and Deployment
Apr 22, 2025The remarkable success of Large Language Models (LLMs) has illuminated a promising pathway toward achieving Artificial General Intelligence for both academic and industrial communities, owing to their unprecedented performance across various applications. As LLMs continue to gain prominence in both research and commercial domains, their security and safety implications have become a growing concern, not only for researchers and corporations but also for every nation. Currently, existing surveys on LLM safety primarily focus on specific stages of the LLM lifecycle, e.g., deployment phase or fine-tuning phase, lacking a comprehensive understanding of the entire "lifechain" of LLMs. To address this gap, this paper introduces, for the first time, the concept of "full-stack" safety to systematically consider safety issues throughout the entire process of LLM training, deployment, and eventual commercialization. Compared to the off-the-shelf LLM safety surveys, our work demonstrates several distinctive advantages: (I) Comprehensive Perspective. We define the complete LLM lifecycle as encompassing data preparation, pre-training, post-training, deployment and final commercialization. To our knowledge, this represents the first safety survey to encompass the entire lifecycle of LLMs. (II) Extensive Literature Support. Our research is grounded in an exhaustive review of over 800+ papers, ensuring comprehensive coverage and systematic organization of security issues within a more holistic understanding. (III) Unique Insights. Through systematic literature analysis, we have developed reliable roadmaps and perspectives for each chapter. Our work identifies promising research directions, including safety in data generation, alignment techniques, model editing, and LLM-based agent systems. These insights provide valuable guidance for researchers pursuing future work in this field.
Whispering Under the Eaves: Protecting User Privacy Against Commercial and LLM-powered Automatic Speech Recognition Systems
Apr 01, 2025The widespread application of automatic speech recognition (ASR) supports large-scale voice surveillance, raising concerns about privacy among users. In this paper, we concentrate on using adversarial examples to mitigate unauthorized disclosure of speech privacy thwarted by potential eavesdroppers in speech communications. While audio adversarial examples have demonstrated the capability to mislead ASR models or evade ASR surveillance, they are typically constructed through time-intensive offline optimization, restricting their practicality in real-time voice communication. Recent work overcame this limitation by generating universal adversarial perturbations (UAPs) and enhancing their transferability for black-box scenarios. However, they introduced excessive noise that significantly degrades audio quality and affects human perception, thereby limiting their effectiveness in practical scenarios. To address this limitation and protect live users' speech against ASR systems, we propose a novel framework, AudioShield. Central to this framework is the concept of Transferable Universal Adversarial Perturbations in the Latent Space (LS-TUAP). By transferring the perturbations to the latent space, the audio quality is preserved to a large extent. Additionally, we propose target feature adaptation to enhance the transferability of UAPs by embedding target text features into the perturbations. Comprehensive evaluation on four commercial ASR APIs (Google, Amazon, iFlytek, and Alibaba), three voice assistants, two LLM-powered ASR and one NN-based ASR demonstrates the protection superiority of AudioShield over existing competitors, and both objective and subjective evaluations indicate that AudioShield significantly improves the audio quality. Moreover, AudioShield also shows high effectiveness in real-time end-to-end scenarios, and demonstrates strong resilience against adaptive countermeasures.
Boosting the Transferability of Audio Adversarial Examples with Acoustic Representation Optimization
Mar 25, 2025With the widespread application of automatic speech recognition (ASR) systems, their vulnerability to adversarial attacks has been extensively studied. However, most existing adversarial examples are generated on specific individual models, resulting in a lack of transferability. In real-world scenarios, attackers often cannot access detailed information about the target model, making query-based attacks unfeasible. To address this challenge, we propose a technique called Acoustic Representation Optimization that aligns adversarial perturbations with low-level acoustic characteristics derived from speech representation models. Rather than relying on model-specific, higher-layer abstractions, our approach leverages fundamental acoustic representations that remain consistent across diverse ASR architectures. By enforcing an acoustic representation loss to guide perturbations toward these robust, lower-level representations, we enhance the cross-model transferability of adversarial examples without degrading audio quality. Our method is plug-and-play and can be integrated with any existing attack methods. We evaluate our approach on three modern ASR models, and the experimental results demonstrate that our method significantly improves the transferability of adversarial examples generated by previous methods while preserving the audio quality.
MALSIGHT: Exploring Malicious Source Code and Benign Pseudocode for Iterative Binary Malware Summarization
Jun 26, 2024
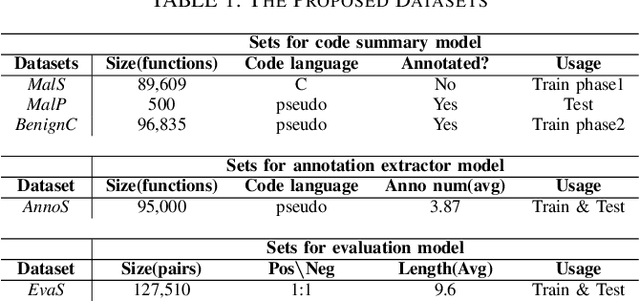
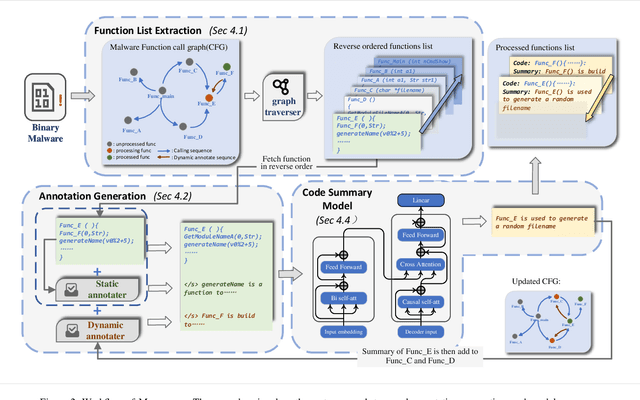

Binary malware summarization aims to automatically generate human-readable descriptions of malware behaviors from executable files, facilitating tasks like malware cracking and detection. Previous methods based on Large Language Models (LLMs) have shown great promise. However, they still face significant issues, including poor usability, inaccurate explanations, and incomplete summaries, primarily due to the obscure pseudocode structure and the lack of malware training summaries. Further, calling relationships between functions, which involve the rich interactions within a binary malware, remain largely underexplored. To this end, we propose MALSIGHT, a novel code summarization framework that can iteratively generate descriptions of binary malware by exploring malicious source code and benign pseudocode. Specifically, we construct the first malware summaries, MalS and MalP, using an LLM and manually refine this dataset with human effort. At the training stage, we tune our proposed MalT5, a novel LLM-based code model, on the MalS dataset and a benign pseudocode dataset. Then, at the test stage, we iteratively feed the pseudocode functions into MalT5 to obtain the summary. Such a procedure facilitates the understanding of pseudocode structure and captures the intricate interactions between functions, thereby benefiting the usability, accuracy, and completeness of summaries. Additionally, we propose a novel evaluation benchmark, BLEURT-sum, to measure the quality of summaries. Experiments on three datasets show the effectiveness of the proposed MALSIGHT. Notably, our proposed MalT5, with only 0.77B parameters, delivers comparable performance to much larger ChatGPT3.5.
Towards Evaluating the Robustness of Automatic Speech Recognition Systems via Audio Style Transfer
May 15, 2024



In light of the widespread application of Automatic Speech Recognition (ASR) systems, their security concerns have received much more attention than ever before, primarily due to the susceptibility of Deep Neural Networks. Previous studies have illustrated that surreptitiously crafting adversarial perturbations enables the manipulation of speech recognition systems, resulting in the production of malicious commands. These attack methods mostly require adding noise perturbations under $\ell_p$ norm constraints, inevitably leaving behind artifacts of manual modifications. Recent research has alleviated this limitation by manipulating style vectors to synthesize adversarial examples based on Text-to-Speech (TTS) synthesis audio. However, style modifications based on optimization objectives significantly reduce the controllability and editability of audio styles. In this paper, we propose an attack on ASR systems based on user-customized style transfer. We first test the effect of Style Transfer Attack (STA) which combines style transfer and adversarial attack in sequential order. And then, as an improvement, we propose an iterative Style Code Attack (SCA) to maintain audio quality. Experimental results show that our method can meet the need for user-customized styles and achieve a success rate of 82% in attacks, while keeping sound naturalness due to our user study.