 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-enabled Applications Require System-Level Threat Monitoring
Feb 23, 2026LLM-enabled applications are rapidly reshaping the software ecosystem by using large language models as core reasoning components for complex task execution. This paradigm shift, however, introduces fundamentally new reliability challenges and significantly expands the security attack surface, due to the non-deterministic, learning-driven, and difficult-to-verify nature of LLM behavior. In light of these emerging and unavoidable safety challenges, we argue that such risks should be treated as expected operational conditions rather than exceptional events, necessitating a dedicated incident-response perspective. Consequently, the primary barrier to trustworthy deployment is not further improving model capability but establishing system-level threat monitoring mechanisms that can detect and contextualize security-relevant anomalies after deployment -- an aspect largely underexplored beyond testing or guardrail-based defenses. Accordingly, this position paper advocates systematic and comprehensive monitoring of security threats in LLM-enabled applications as a prerequisite for reliable operation and a foundation for dedicated incident-response frameworks.
Saddle-to-Saddle Dynamics Explains A Simplicity Bias Across Neural Network Architectures
Dec 23, 2025Neural networks trained with gradient descent often learn solutions of increasing complexity over time, a phenomenon known as simplicity bias. Despite being widely observed across architectures, existing theoretical treatments lack a unifying framework. We present a theoretical framework that explains a simplicity bias arising from saddle-to-saddle learning dynamics for a general class of neural networks, incorporating fully-connected, convolutional, and attention-based architectures. Here, simple means expressible with few hidden units, i.e., hidden neurons, convolutional kernels, or attention heads. Specifically, we show that linear networks learn solutions of increasing rank, ReLU networks learn solutions with an increasing number of kinks, convolutional networks learn solutions with an increasing number of convolutional kernels, and self-attention models learn solutions with an increasing number of attention heads. By analyzing fixed points, invariant manifolds, and dynamics of gradient descent learning, we show that saddle-to-saddle dynamics operates by iteratively evolving near an invariant manifold, approaching a saddle, and switching to another invariant manifold. Our analysis also illuminates the effects of data distribution and weight initialization on the duration and number of plateaus in learning, dissociating previously confounding factors. Overall, our theory offers a framework for understanding when and why gradient descent progressively learns increasingly complex solutions.
RvLLM: LLM Runtime Verification with Domain Knowledge
May 24, 2025Large language models (LLMs) have emerged as a dominant AI paradigm due to their exceptional text understanding and generation capabilities. However, their tendency to generate inconsistent or erroneous outputs challenges their reliability, especially in high-stakes domains requiring accuracy and trustworthiness. Existing research primarily focuses on detecting and mitigating model misbehavior in general-purpose scenarios, often overlooking the potential of integrating domain-specific knowledge. In this work, we advance misbehavior detection by incorporating domain knowledge. The core idea is to design a general specification language that enables domain experts to customize domain-specific predicates in a lightweight and intuitive manner, supporting later runtime verification of LLM outputs. To achieve this, we design a novel specification language, ESL, and introduce a runtime verification framework, RvLLM, to validate LLM output against domain-specific constraints defined in ESL. We evaluate RvLLM on three representative tasks: violation detection against Singapore Rapid Transit Systems Act, numerical comparison, and inequality solving. Experimental results demonstrate that RvLLM effectively detects erroneous outputs across various LLMs in a lightweight and flexible manner. The results reveal that despite their impressive capabilities, LLMs remain prone to low-level errors due to limited interpretability and a lack of formal guarantees during inference, and our framework offers a potential long-term solution by leveraging expert domain knowledge to rigorously and efficiently verify LLM outputs.
Whispering Under the Eaves: Protecting User Privacy Against Commercial and LLM-powered Automatic Speech Recognition Systems
Apr 01, 2025The widespread application of automatic speech recognition (ASR) supports large-scale voice surveillance, raising concerns about privacy among users. In this paper, we concentrate on using adversarial examples to mitigate unauthorized disclosure of speech privacy thwarted by potential eavesdroppers in speech communications. While audio adversarial examples have demonstrated the capability to mislead ASR models or evade ASR surveillance, they are typically constructed through time-intensive offline optimization, restricting their practicality in real-time voice communication. Recent work overcame this limitation by generating universal adversarial perturbations (UAPs) and enhancing their transferability for black-box scenarios. However, they introduced excessive noise that significantly degrades audio quality and affects human perception, thereby limiting their effectiveness in practical scenarios. To address this limitation and protect live users' speech against ASR systems, we propose a novel framework, AudioShield. Central to this framework is the concept of Transferable Universal Adversarial Perturbations in the Latent Space (LS-TUAP). By transferring the perturbations to the latent space, the audio quality is preserved to a large extent. Additionally, we propose target feature adaptation to enhance the transferability of UAPs by embedding target text features into the perturbations. Comprehensive evaluation on four commercial ASR APIs (Google, Amazon, iFlytek, and Alibaba), three voice assistants, two LLM-powered ASR and one NN-based ASR demonstrates the protection superiority of AudioShield over existing competitors, and both objective and subjective evaluations indicate that AudioShield significantly improves the audio quality. Moreover, AudioShield also shows high effectiveness in real-time end-to-end scenarios, and demonstrates strong resilience against adaptive countermeasures.
Verification of Bit-Flip Attacks against Quantized Neural Networks
Feb 22, 2025



In the rapidly evolving landscape of neural network security, the resilience of neural networks against bit-flip attacks (i.e., an attacker maliciously flips an extremely small amount of bits within its parameter storage memory system to induce harmful behavior), has emerged as a relevant area of research. Existing studies suggest that quantization may serve as a viable defense against such attacks. Recognizing the documented susceptibility of real-valued neural networks to such attacks and the comparative robustness of quantized neural networks (QNNs), in this work, we introduce BFAVerifier, the first verification framework designed to formally verify the absence of bit-flip attacks or to identify all vulnerable parameters in a sound and rigorous manner. BFAVerifier comprises two integral components: an abstraction-based method and an MILP-based method. Specifically, we first conduct a reachability analysis with respect to symbolic parameters that represent the potential bit-flip attacks, based on a novel abstract domain with a sound guarantee. If the reachability analysis fails to prove the resilience of such attacks, then we encode this verification problem into an equivalent MILP problem which can be solved by off-the-shelf solvers. Therefore, BFAVerifier is sound, complete, and reasonably efficient. We conduct extensive experiments, which demonstrate its effectiveness and efficiency across various network architectures, quantization bit-widths, and adversary capabilities.
Training Dynamics of In-Context Learning in Linear Attention
Jan 27, 2025While attention-based models have demonstrated the remarkable ability of in-context learning, the theoretical understanding of how these models acquired this ability through gradient descent training is still preliminary. Towards answering this question, we study the gradient descent dynamics of multi-head linear self-attention trained for in-context linear regression. We examine two parametrizations of linear self-attention: one with the key and query weights merged as a single matrix (common in theoretical studies), and one with separate key and query matrices (closer to practical settings). For the merged parametrization, we show the training dynamics has two fixed points and the loss trajectory exhibits a single, abrupt drop. We derive an analytical time-course solution for a certain class of datasets and initialization. For the separate parametrization, we show the training dynamics has exponentially many fixed points and the loss exhibits saddle-to-saddle dynamics, which we reduce to scalar ordinary differential equations. During training, the model implements principal component regression in context with the number of principal components increasing over training time. Overall, we characterize how in-context learning abilities evolve during gradient descent training of linear attention, revealing dynamics of abrupt acquisition versus progressive improvements in models with different parametrizations.
The Fusion of Large Language Models and Formal Methods for Trustworthy AI Agents: A Roadmap
Dec 09, 2024


Large Language Models (LLMs) have emerged as a transformative AI paradigm, profoundly influencing daily life through their exceptional language understanding and contextual generation capabilities. Despite their remarkable performance, LLMs face a critical challenge: the propensity to produce unreliable outputs due to the inherent limitations of their learning-based nature. Formal methods (FMs), on the other hand, are a well-established computation paradigm that provides mathematically rigorous techniques for modeling, specifying, and verifying the correctness of systems. FMs have been extensively applied in mission-critical software engineering, embedded systems, and cybersecurity. However, the primary challenge impeding the deployment of FMs in real-world settings lies in their steep learning curves, the absence of user-friendly interfaces, and issues with efficiency and adaptability. This position paper outlines a roadmap for advancing the next generation of trustworthy AI systems by leveraging the mutual enhancement of LLMs and FMs. First, we illustrate how FMs, including reasoning and certification techniques, can help LLMs generate more reliable and formally certified outputs. Subsequently, we highlight how the advanced learning capabilities and adaptability of LLMs can significantly enhance the usability, efficiency, and scalability of existing FM tools. Finally, we show that unifying these two computation paradigms -- integrating the flexibility and intelligence of LLMs with the rigorous reasoning abilities of FMs -- has transformative potential for the development of trustworthy AI software systems. We acknowledge that this integration has the potential to enhance both the trustworthiness and efficiency of software engineering practices while fostering the development of intelligent FM tools capable of addressing complex yet real-world challenges.
When Are Bias-Free ReLU Networks Like Linear Networks?
Jun 18, 2024We investigate the expressivity and learning dynamics of bias-free ReLU networks. We firstly show that two-layer bias-free ReLU networks have limited expressivity: the only odd function two-layer bias-free ReLU networks can express is a linear one. We then show that, under symmetry conditions on the data, these networks have the same learning dynamics as linear networks. This allows us to give closed-form time-course solutions to certain two-layer bias-free ReLU networks, which has not been done for nonlinear networks outside the lazy learning regime. While deep bias-free ReLU networks are more expressive than their two-layer counterparts, they still share a number of similarities with deep linear networks. These similarities enable us to leverage insights from linear networks, leading to a novel understanding of bias-free ReLU networks. Overall, our results show that some properties established for bias-free ReLU networks arise due to equivalence to linear networks, and suggest that including bias or considering asymmetric data are avenues to engage with nonlinear behaviors.
A Proactive and Dual Prevention Mechanism against Illegal Song Covers empowered by Singing Voice Conversion
Jan 30, 2024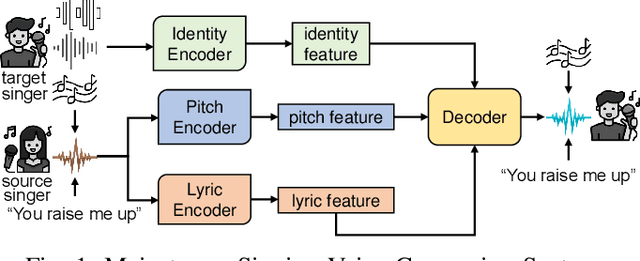
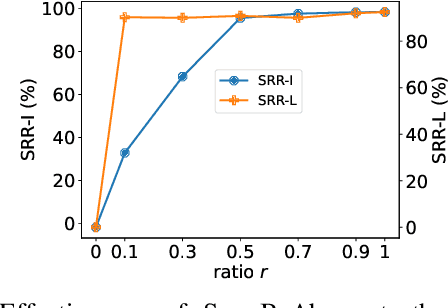
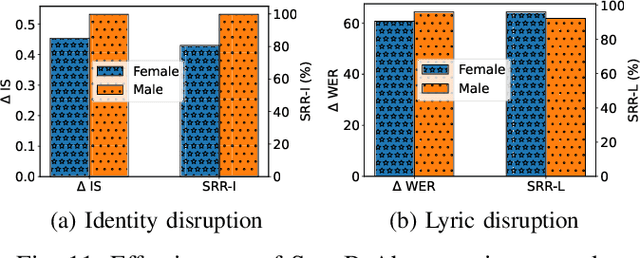
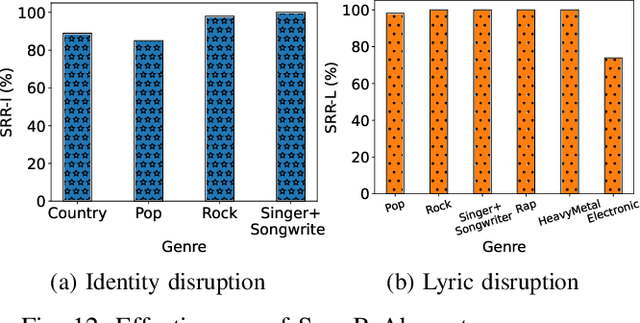
Singing voice conversion (SVC) automates song covers by converting one singer's singing voice into another target singer's singing voice with the original lyrics and melody. However, it raises serious concerns about copyright and civil right infringements to multiple entities. This work proposes SongBsAb, the first proactive approach to mitigate unauthorized SVC-based illegal song covers. SongBsAb introduces human-imperceptible perturbations to singing voices before releasing them, so that when they are used, the generation process of SVC will be interfered, resulting in unexpected singing voices. SongBsAb features a dual prevention effect by causing both (singer) identity disruption and lyric disruption, namely, the SVC-covered singing voice neither imitates the target singer nor preserves the original lyrics. To improve the imperceptibility of perturbations, we refine a psychoacoustic model-based loss with the backing track as an additional masker, a unique accompanying element for singing voices compared to ordinary speech voices. To enhance the transferability, we propose to utilize a frame-level interaction reduction-based loss. We demonstrate the prevention effectiveness, utility, and robustness of SongBsAb on three SVC models and two datasets using both objective and human study-based subjective metrics. Our work fosters an emerging research direction for mitigating illegal automated song covers.
Towards Efficient Verification of Quantized Neural Networks
Dec 27, 2023



Quantization replaces floating point arithmetic with integer arithmetic in deep neural network models, providing more efficient on-device inference with less power and memory. In this work, we propose a framework for formally verifying properties of quantized neural networks. Our baseline technique is based on integer linear programming which guarantees both soundness and completeness. We then show how efficiency can be improved by utilizing gradient-based heuristic search methods and also bound-propagation techniques. We evaluate our approach on perception networks quantized with PyTorch. Our results show that we can verify quantized networks with better scalability and efficiency than the previous state of the art.