 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe FABRIC Strategy for Verifying Neural Feedback Systems
Mar 09, 2026Forward reachability analysis is a dominant approach for verifying reach-avoid specifications in neural feedback systems, i.e., dynamical systems controlled by neural networks, and a number of directions have been proposed and studied. In contrast, far less attention has been given to backward reachability analysis for these systems, in part because of the limited scalability of known techniques. In this work, we begin to address this gap by introducing new algorithms for computing both over- and underapproximations of backward reachable sets for nonlinear neural feedback systems. We also describe and implement an integration of these backward reachability techniques with existing ones for forward analysis. We call the resulting algorithm Forward and Backward Reachability Integration for Certification (FaBRIC). We evaluate our algorithms on a representative set of benchmarks and show that they significantly outperform the prior state of the art.
Self-Supervised Bootstrapping of Action-Predictive Embodied Reasoning
Feb 09, 2026Embodied Chain-of-Thought (CoT) reasoning has significantly enhanced Vision-Language-Action (VLA) models, yet current methods rely on rigid templates to specify reasoning primitives (e.g., objects in the scene, high-level plans, structural affordances). These templates can force policies to process irrelevant information that distracts from critical action-prediction signals. This creates a bottleneck: without successful policies, we cannot verify reasoning quality; without quality reasoning, we cannot build robust policies. We introduce R&B-EnCoRe, which enables models to bootstrap embodied reasoning from internet-scale knowledge through self-supervised refinement. By treating reasoning as a latent variable within importance-weighted variational inference, models can generate and distill a refined reasoning training dataset of embodiment-specific strategies without external rewards, verifiers, or human annotation. We validate R&B-EnCoRe across manipulation (Franka Panda in simulation, WidowX in hardware), legged navigation (bipedal, wheeled, bicycle, quadruped), and autonomous driving embodiments using various VLA architectures with 1B, 4B, 7B, and 30B parameters. Our approach achieves 28% gains in manipulation success, 101% improvement in navigation scores, and 21% reduction in collision-rate metric over models that indiscriminately reason about all available primitives. R&B-EnCoRe enables models to distill reasoning that is predictive of successful control, bypassing manual annotation engineering while grounding internet-scale knowledge in physical execution.
A New Strategy for Verifying Reach-Avoid Specifications in Neural Feedback Systems
Jan 12, 2026Forward reachability analysis is the predominant approach for verifying reach-avoid properties in neural feedback systems (dynamical systems controlled by neural networks). This dominance stems from the limited scalability of existing backward reachability methods. In this work, we introduce new algorithms that compute both over- and under-approximations of backward reachable sets for such systems. We further integrate these backward algorithms with established forward analysis techniques to yield a unified verification framework for neural feedback systems.
Proof Minimization in Neural Network Verification
Nov 11, 2025The widespread adoption of deep neural networks (DNNs) requires efficient techniques for verifying their safety. DNN verifiers are complex tools, which might contain bugs that could compromise their soundness and undermine the reliability of the verification process. This concern can be mitigated using proofs: artifacts that are checkable by an external and reliable proof checker, and which attest to the correctness of the verification process. However, such proofs tend to be extremely large, limiting their use in many scenarios. In this work, we address this problem by minimizing proofs of unsatisfiability produced by DNN verifiers. We present algorithms that remove facts which were learned during the verification process, but which are unnecessary for the proof itself. Conceptually, our method analyzes the dependencies among facts used to deduce UNSAT, and removes facts that did not contribute. We then further minimize the proof by eliminating remaining unnecessary dependencies, using two alternative procedures. We implemented our algorithms on top of a proof producing DNN verifier, and evaluated them across several benchmarks. Our results show that our best-performing algorithm reduces proof size by 37%-82% and proof checking time by 30%-88%, while introducing a runtime overhead of 7%-20% to the verification process itself.
Proof-Driven Clause Learning in Neural Network Verification
Mar 15, 2025The widespread adoption of deep neural networks (DNNs) requires efficient techniques for safety verification. Existing methods struggle to scale to real-world DNNs, and tremendous efforts are being put into improving their scalability. In this work, we propose an approach for improving the scalability of DNN verifiers using Conflict-Driven Clause Learning (CDCL) -- an approach that has proven highly successful in SAT and SMT solving. We present a novel algorithm for deriving conflict clauses using UNSAT proofs, and propose several optimizations for expediting it. Our approach allows a modular integration of SAT solvers and DNN verifiers, and we implement it on top of an interface designed for this purpose. The evaluation of our implementation over several benchmarks suggests a 2X--3X improvement over a similar approach, with specific cases outperforming the state of the art.
Pantograph: A Machine-to-Machine Interaction Interface for Advanced Theorem Proving, High Level Reasoning, and Data Extraction in Lean 4
Oct 21, 2024Machine-assisted theorem proving refers to the process of conducting structured reasoning to automatically generate proofs for mathematical theorems. Recently, there has been a surge of interest in using machine learning models in conjunction with proof assistants to perform this task. In this paper, we introduce Pantograph, a tool that provides a versatile interface to the Lean 4 proof assistant and enables efficient proof search via powerful search algorithms such as Monte Carlo Tree Search. In addition, Pantograph enables high-level reasoning by enabling a more robust handling of Lean 4's inference steps. We provide an overview of Pantograph's architecture and features. We also report on an illustrative use case: using machine learning models and proof sketches to prove Lean 4 theorems. Pantograph's innovative features pave the way for more advanced machine learning models to perform complex proof searches and high-level reasoning, equipping future researchers to design more versatile and powerful theorem provers.
Better Verified Explanations with Applications to Incorrectness and Out-of-Distribution Detection
Sep 04, 2024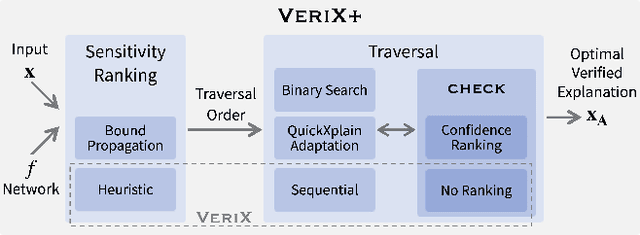
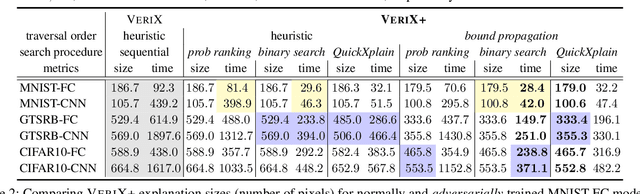


Building on VeriX (Verified eXplainability, arXiv:2212.01051), a system for producing optimal verified explanations for machine learning model outputs, we present VeriX+, which significantly improves both the size and the generation time of verified explanations. We introduce a bound propagation-based sensitivity technique to improve the size, and a binary search-based traversal with confidence ranking for improving time -- the two techniques are orthogonal and can be used independently or together. We also show how to adapt the QuickXplain (Junker 2004) algorithm to our setting to provide a trade-off between size and time. Experimental evaluations on standard benchmarks demonstrate significant improvements on both metrics, e.g., a size reduction of 38% on the GTSRB dataset and a time reduction of 90% on MNIST. We also explore applications of our verified explanations and show that explanation size is a useful proxy for both incorrectness detection and out-of-distribution detection.
Safe and Reliable Training of Learning-Based Aerospace Controllers
Jul 09, 2024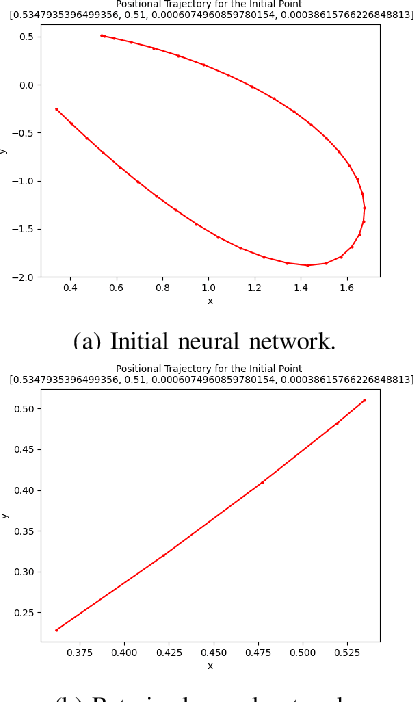


In recent years, deep reinforcement learning (DRL) approaches have generated highly successful controllers for a myriad of complex domains. However, the opaque nature of these models limits their applicability in aerospace systems and safety-critical domains, in which a single mistake can have dire consequences. In this paper, we present novel advancements in both the training and verification of DRL controllers, which can help ensure their safe behavior. We showcase a design-for-verification approach utilizing k-induction and demonstrate its use in verifying liveness properties. In addition, we also give a brief overview of neural Lyapunov Barrier certificates and summarize their capabilities on a case study. Finally, we describe several other novel reachability-based approaches which, despite failing to provide guarantees of interest, could be effective for verification of other DRL systems, and could be of further interest to the community.
Formally Verifying Deep Reinforcement Learning Controllers with Lyapunov Barrier Certificates
May 22, 2024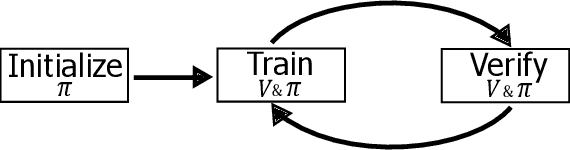
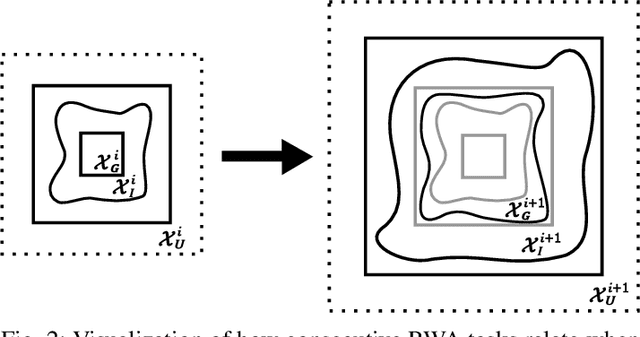
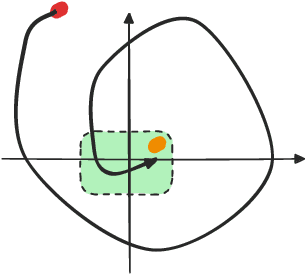
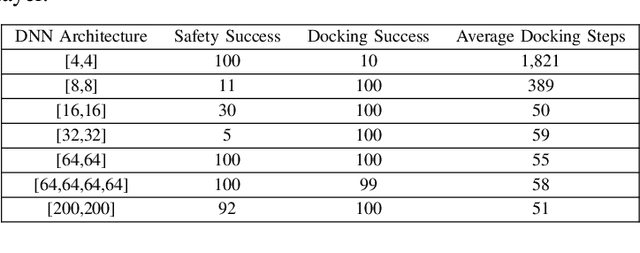
Deep reinforcement learning (DRL) is a powerful machine learning paradigm for generating agents that control autonomous systems. However, the "black box" nature of DRL agents limits their deployment in real-world safety-critical applications. A promising approach for providing strong guarantees on an agent's behavior is to use Neural Lyapunov Barrier (NLB) certificates, which are learned functions over the system whose properties indirectly imply that an agent behaves as desired. However, NLB-based certificates are typically difficult to learn and even more difficult to verify, especially for complex systems. In this work, we present a novel method for training and verifying NLB-based certificates for discrete-time systems. Specifically, we introduce a technique for certificate composition, which simplifies the verification of highly-complex systems by strategically designing a sequence of certificates. When jointly verified with neural network verification engines, these certificates provide a formal guarantee that a DRL agent both achieves its goals and avoids unsafe behavior. Furthermore, we introduce a technique for certificate filtering, which significantly simplifies the process of producing formally verified certificates. We demonstrate the merits of our approach with a case study on providing safety and liveness guarantees for a DRL-controlled spacecraft.
Towards Guaranteed Safe AI: A Framework for Ensuring Robust and Reliable AI Systems
May 10, 2024



Ensuring that AI systems reliably and robustly avoid harmful or dangerous behaviours is a crucial challenge, especially for AI systems with a high degree of autonomy and general intelligence, or systems used in safety-critical contexts. In this paper, we will introduce and define a family of approaches to AI safety, which we will refer to as guaranteed safe (GS) AI. The core feature of these approaches is that they aim to produce AI systems which are equipped with high-assurance quantitative safety guarantees. This is achieved by the interplay of three core components: a world model (which provides a mathematical description of how the AI system affects the outside world), a safety specification (which is a mathematical description of what effects are acceptable), and a verifier (which provides an auditable proof certificate that the AI satisfies the safety specification relative to the world model). We outline a number of approaches for creating each of these three core components, describe the main technical challenges, and suggest a number of potential solutions to them. We also argue for the necessity of this approach to AI safety, and for the inadequacy of the main alternative approaches.