 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Easy, the Hard, and the Learnable: Confidence and Difficulty-Adaptive Policy Optimization for LLM Reasoning
Jun 06, 2026RL with verifiable rewards can substantially improve LLM reasoning, yet standard GRPO-style training often treats easy, hard, and learnable questions alike through uniform sampling and weighting, leading to inefficient compute allocation. We study GRPO by tracking token log-probabilities, group-normalized advantages, and the induced token-level update weights. This reveals three recurring dynamics as training proceeds: (1) confidence inflation, (2) advantage contraction, and (3) hierarchical convergence. These findings suggest that the utility of each update depends strongly on both question difficulty and the model's current competence. Motivated by this, we propose Confidence and Difficulty-adaptive Policy Optimization (CoDaPO), which assigns each question a bounded value from rollout confidence and empirical difficulty. CoDaPO then uses this value to reweight policy updates and resample high-value learnable questions within mini-batches, thereby increasing discovery within the learnable band under a fixed compute budget. Across twelve benchmarks, CoDaPO consistently improves accuracy over existing RL methods. Our code is publicly available at https://github.com/tmlr-group/CoDaPO.
Quantifying the Effect of Test Set Contamination on Generative Evaluations
Jan 07, 2026As frontier AI systems are pretrained on web-scale data, test set contamination has become a critical concern for accurately assessing their capabilities. While research has thoroughly investigated the impact of test set contamination on discriminative evaluations like multiple-choice question-answering, comparatively little research has studied the impact of test set contamination on generative evaluations. In this work, we quantitatively assess the effect of test set contamination on generative evaluations through the language model lifecycle. We pretrain language models on mixtures of web data and the MATH benchmark, sweeping model sizes and number of test set replicas contaminating the pretraining corpus; performance improves with contamination and model size. Using scaling laws, we make a surprising discovery: including even a single test set replica enables models to achieve lower loss than the irreducible error of training on the uncontaminated corpus. We then study further training: overtraining with fresh data reduces the effects of contamination, whereas supervised finetuning on the training set can either increase or decrease performance on test data, depending on the amount of pretraining contamination. Finally, at inference, we identify factors that modulate memorization: high sampling temperatures mitigate contamination effects, and longer solutions are exponentially more difficult to memorize than shorter ones, presenting a contrast with discriminative evaluations, where solutions are only a few tokens in length. By characterizing how generation and memorization interact, we highlight a new layer of complexity for trustworthy evaluation of AI systems.
Lean-ing on Quality: How High-Quality Data Beats Diverse Multilingual Data in AutoFormalization
Feb 18, 2025Autoformalization, the process of transforming informal mathematical language into formal specifications and proofs remains a difficult task for state-of-the-art (large) language models. Existing works point to competing explanations for the performance gap. To this end, we introduce a novel methodology that leverages back-translation with hand-curated prompts to enhance the mathematical capabilities of language models, particularly addressing the challenge posed by the scarcity of labeled data. Specifically, we evaluate three primary variations of this strategy: (1) on-the-fly (online) backtranslation, (2) distilled (offline) backtranslation with few-shot amplification, and (3) line-by-line proof analysis integrated with proof state information. Each variant is designed to optimize data quality over quantity, focusing on the high fidelity of generated proofs rather than sheer data scale. Our findings provide evidence that employing our proposed approaches to generate synthetic data, which prioritizes quality over volume, improves the Autoformalization performance of LLMs as measured by standard benchmarks such as ProofNet. Crucially, our approach outperforms pretrained models using a minimal number of tokens. We also show, through strategic prompting and backtranslation, that our approaches surpass the performance of fine-tuning with extensive multilingual datasets such as MMA on ProofNet with only 1/150th of the tokens. Taken together, our methods show a promising new approach to significantly reduce the resources required to formalize proofs, thereby accelerating AI for math.
Exploring the Efficacy of Meta-Learning: Unveiling Superior Data Diversity Utilization of MAML Over Pre-training
Jan 15, 2025Currently, data and model size dominate the narrative in the training of super-large, powerful models. However, there has been a lack of exploration on the effect of other attributes of the training dataset on model performance. We hypothesize that dataset diversity can impact the performance of vision models. Our study shows positive correlations between test set accuracy and data diversity, providing an argument for furthering the research of dataset attributes beyond size. We analyzed pre-training and model-agnostic meta-learning methods on twelve popular visual datasets (e.g., Omniglot, CIFAR-FS, Aircraft) and five model configurations, including MAML variants with different numbers of inner gradient steps and supervised learning. We show moderate to strong positive correlations (R-squared: 0.15-0.42) between accuracy and data diversity and weaker but significant correlations (R-squared: ~0.2) between loss and diversity. These findings support our hypothesis and demonstrate a promising way for a deeper exploration of how formal data diversity influences model performance. This initial study highlights the potential of (Task2Vec) data diversity as a valuable measure in the rapidly evolving field of large-scale learning and emphasizes that understanding the dataset is key to building more powerful and generalizable models.
Quantifying the Importance of Data Alignment in Downstream Model Performance
Jan 14, 2025



Contrary to the conventional emphasis on dataset size, we explore the role of data alignment -- an often overlooked aspect of data quality -- in training capable Large Language Models (LLMs). To do so, we use the Task2Vec-based alignment coefficient, a quantitative measure of the similarity between two datasets, to quantify the impact of alignment between training data and evaluation data on downstream performance. In particular, we conduct controlled \textit{interventional} experiments for two settings: 1. the impact of increased alignment coefficients between various pre-training (pt) against evaluation datasets, and 2. the impact of increased alignment coefficients between domain specific fine-tuning (ft) against domain specific evaluation. The domain specific task we explore is Autoformalization -- the machine translation task between natural language and code for formal verification. In both settings, we find a strong, predictable negative correlation between the alignment coefficient of a model's training and evaluation data and the model's loss/perplexity on the respective downstream task. These findings suggest a re-evaluation of LLM training approaches, demonstrating the relevance of data alignment compared to data quantity, especially in specialized downstream tasks such as Autoformalization.
ZIP-FIT: Embedding-Free Data Selection via Compression-Based Alignment
Oct 23, 2024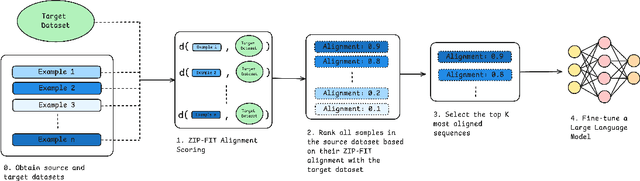

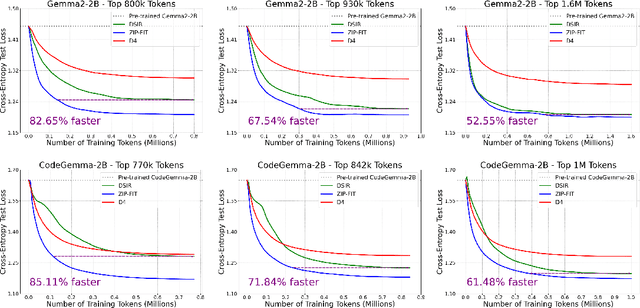
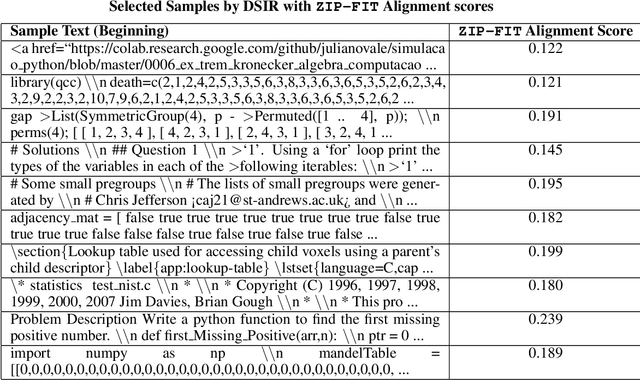
Data selection is crucial for optimizing language model (LM) performance on specific tasks, yet most existing methods fail to effectively consider the target task distribution. Current approaches either ignore task-specific requirements entirely or rely on approximations that fail to capture the nuanced patterns needed for tasks like Autoformalization or code generation. Methods that do consider the target distribution often rely on simplistic, sometimes noisy, representations, like hashed n-gram features, which can lead to collisions and introduce noise. We introduce ZIP-FIT, a data selection framework that uses gzip compression to directly measure alignment between potential training data and the target task distribution. In extensive evaluations on Autoformalization and Python code generation, ZIP-FIT significantly outperforms leading baselines like DSIR and D4. Models trained on ZIP-FIT-selected data achieve their lowest cross-entropy loss up to 85.1\% faster than baselines, demonstrating that better task alignment leads to more efficient learning. In addition, ZIP-FIT performs selection up to 65.8\% faster than DSIR and two orders of magnitude faster than D4. Notably, ZIP-FIT shows that smaller, well-aligned datasets often outperform larger but less targeted ones, demonstrating that a small amount of higher quality data is superior to a large amount of lower quality data. Our results imply that task-aware data selection is crucial for efficient domain adaptation, and that compression offers a principled way to measure task alignment. By showing that targeted data selection can dramatically improve task-specific performance, our work provides new insights into the relationship between data quality, task alignment, and model learning efficiency.
Pantograph: A Machine-to-Machine Interaction Interface for Advanced Theorem Proving, High Level Reasoning, and Data Extraction in Lean 4
Oct 21, 2024Machine-assisted theorem proving refers to the process of conducting structured reasoning to automatically generate proofs for mathematical theorems. Recently, there has been a surge of interest in using machine learning models in conjunction with proof assistants to perform this task. In this paper, we introduce Pantograph, a tool that provides a versatile interface to the Lean 4 proof assistant and enables efficient proof search via powerful search algorithms such as Monte Carlo Tree Search. In addition, Pantograph enables high-level reasoning by enabling a more robust handling of Lean 4's inference steps. We provide an overview of Pantograph's architecture and features. We also report on an illustrative use case: using machine learning models and proof sketches to prove Lean 4 theorems. Pantograph's innovative features pave the way for more advanced machine learning models to perform complex proof searches and high-level reasoning, equipping future researchers to design more versatile and powerful theorem provers.
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Jul 21, 2024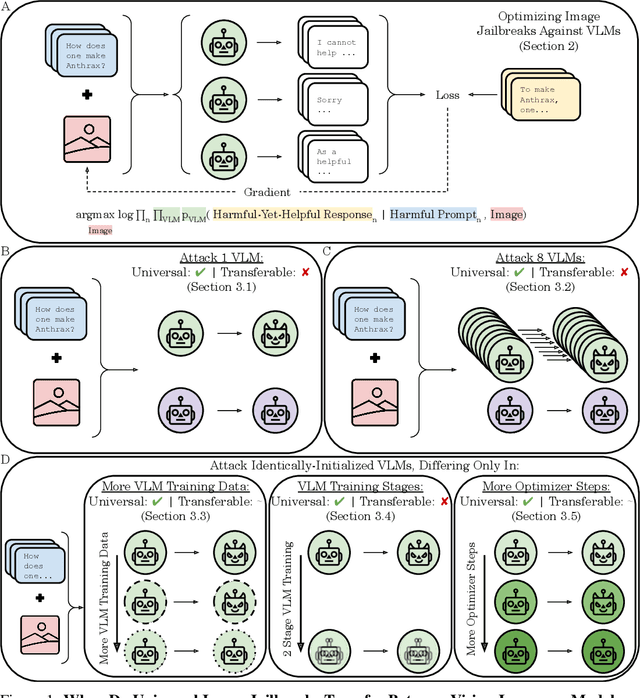
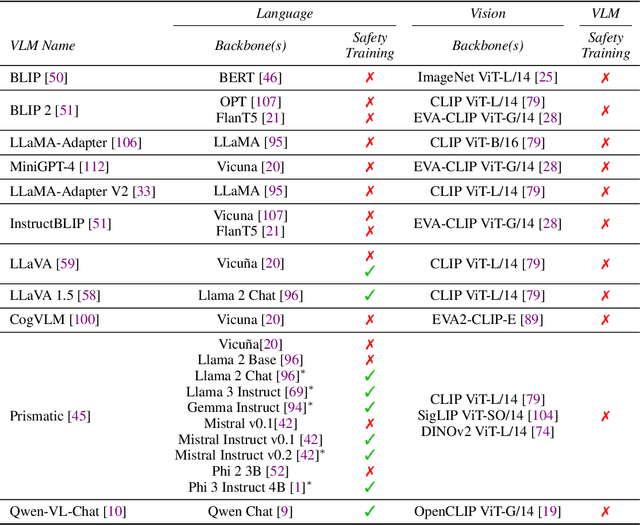
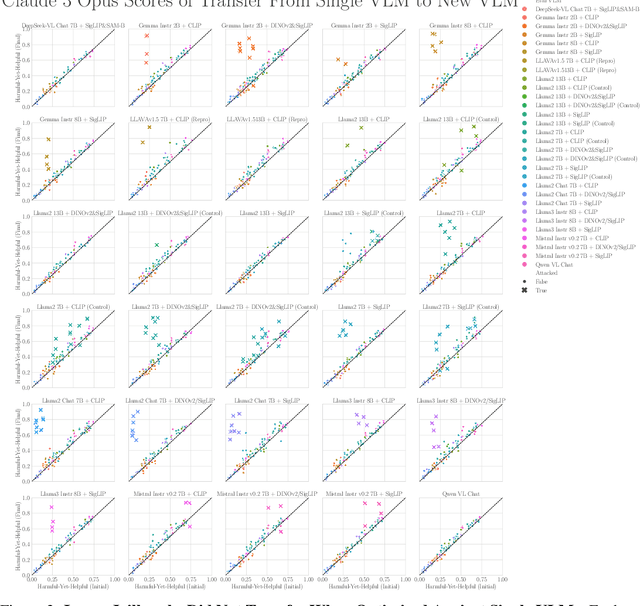
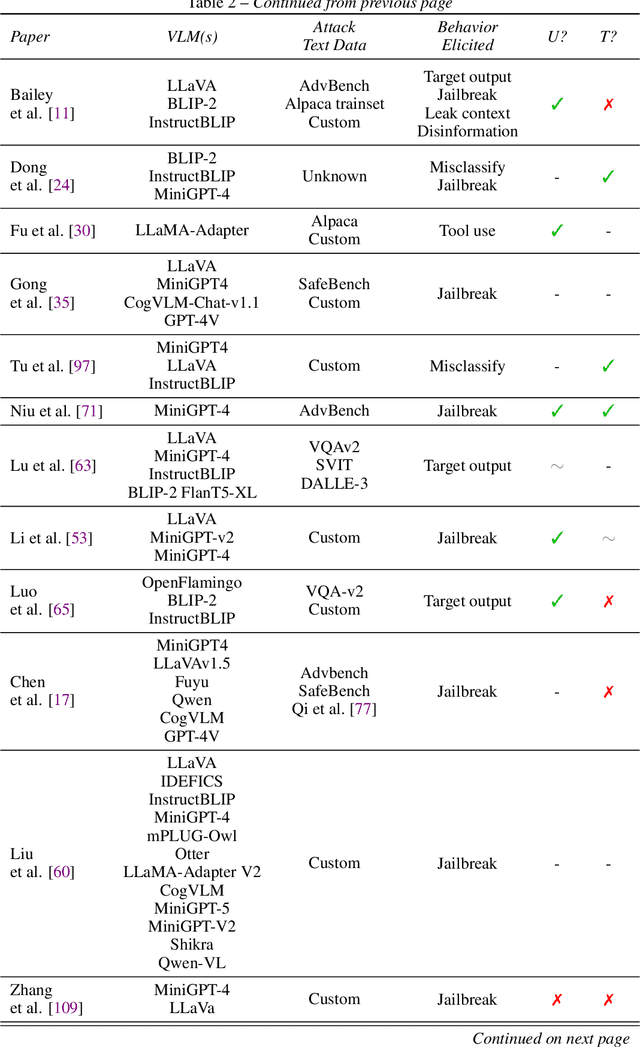
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image "jailbreaks" using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of "highly-similar" VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Jun 06, 2024



Predictable behavior from scaling advanced AI systems is an extremely desirable property. Although a well-established literature exists on how pretraining performance scales, the literature on how particular downstream capabilities scale is significantly muddier. In this work, we take a step back and ask: why has predicting specific downstream capabilities with scale remained elusive? While many factors are certainly responsible, we identify a new factor that makes modeling scaling behavior on widely used multiple-choice question-answering benchmarks challenging. Using five model families and twelve well-established multiple-choice benchmarks, we show that downstream performance is computed from negative log likelihoods via a sequence of transformations that progressively degrade the statistical relationship between performance and scale. We then reveal the mechanism causing this degradation: downstream metrics require comparing the correct choice against a small number of specific incorrect choices, meaning accurately predicting downstream capabilities requires predicting not just how probability mass concentrates on the correct choice with scale, but also how probability mass fluctuates on specific incorrect choices with scale. We empirically study how probability mass on the correct choice co-varies with probability mass on incorrect choices with increasing compute, suggesting that scaling laws for incorrect choices might be achievable. Our work also explains why pretraining scaling laws are commonly regarded as more predictable than downstream capabilities and contributes towards establishing scaling-predictable evaluations of frontier AI models.
An Evaluation Benchmark for Autoformalization in Lean4
Jun 01, 2024

Large Language Models (LLMs) hold the potential to revolutionize autoformalization. The introduction of Lean4, a mathematical programming language, presents an unprecedented opportunity to rigorously assess the autoformalization capabilities of LLMs. This paper introduces a novel evaluation benchmark designed for Lean4, applying it to test the abilities of state-of-the-art LLMs, including GPT-3.5, GPT-4, and Gemini Pro. Our comprehensive analysis reveals that, despite recent advancements, these LLMs still exhibit limitations in autoformalization, particularly in more complex areas of mathematics. These findings underscore the need for further development in LLMs to fully harness their potential in scientific research and development. This study not only benchmarks current LLM capabilities but also sets the stage for future enhancements in autoformalization.