 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Consciousness and Public Perceptions: Four Futures
Aug 08, 2024



The discourse on risks from advanced AI systems ("AIs") typically focuses on misuse, accidents and loss of control, but the question of AIs' moral status could have negative impacts which are of comparable significance and could be realised within similar timeframes. Our paper evaluates these impacts by investigating (1) the factual question of whether future advanced AI systems will be conscious, together with (2) the epistemic question of whether future human society will broadly believe advanced AI systems to be conscious. Assuming binary responses to (1) and (2) gives rise to four possibilities: in the true positive scenario, society predominantly correctly believes that AIs are conscious; in the false positive scenario, that belief is incorrect; in the true negative scenario, society correctly believes that AIs are not conscious; and lastly, in the false negative scenario, society incorrectly believes that AIs are not conscious. The paper offers vivid vignettes of the different futures to ground the two-dimensional framework. Critically, we identify four major risks: AI suffering, human disempowerment, geopolitical instability, and human depravity. We evaluate each risk across the different scenarios and provide an overall qualitative risk assessment for each scenario. Our analysis suggests that the worst possibility is the wrong belief that AI is non-conscious, followed by the wrong belief that AI is conscious. The paper concludes with the main recommendations to avoid research aimed at intentionally creating conscious AI and instead focus efforts on reducing our current uncertainties on both the factual and epistemic questions on AI consciousness.
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
Jul 31, 2024As artificial intelligence systems grow more powerful, there has been increasing interest in "AI safety" research to address emerging and future risks. However, the field of AI safety remains poorly defined and inconsistently measured, leading to confusion about how researchers can contribute. This lack of clarity is compounded by the unclear relationship between AI safety benchmarks and upstream general capabilities (e.g., general knowledge and reasoning). To address these issues, we conduct a comprehensive meta-analysis of AI safety benchmarks, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety. Our findings reveal that many safety benchmarks highly correlate with upstream model capabilities, potentially enabling "safetywashing" -- where capability improvements are misrepresented as safety advancements. Based on these findings, we propose an empirical foundation for developing more meaningful safety metrics and define AI safety in a machine learning research context as a set of clearly delineated research goals that are empirically separable from generic capabilities advancements. In doing so, we aim to provide a more rigorous framework for AI safety research, advancing the science of safety evaluations and clarifying the path towards measurable progress.
Why Has Predicting Downstream Capabilities of Frontier AI Models with Scale Remained Elusive?
Jun 06, 2024



Predictable behavior from scaling advanced AI systems is an extremely desirable property. Although a well-established literature exists on how pretraining performance scales, the literature on how particular downstream capabilities scale is significantly muddier. In this work, we take a step back and ask: why has predicting specific downstream capabilities with scale remained elusive? While many factors are certainly responsible, we identify a new factor that makes modeling scaling behavior on widely used multiple-choice question-answering benchmarks challenging. Using five model families and twelve well-established multiple-choice benchmarks, we show that downstream performance is computed from negative log likelihoods via a sequence of transformations that progressively degrade the statistical relationship between performance and scale. We then reveal the mechanism causing this degradation: downstream metrics require comparing the correct choice against a small number of specific incorrect choices, meaning accurately predicting downstream capabilities requires predicting not just how probability mass concentrates on the correct choice with scale, but also how probability mass fluctuates on specific incorrect choices with scale. We empirically study how probability mass on the correct choice co-varies with probability mass on incorrect choices with increasing compute, suggesting that scaling laws for incorrect choices might be achievable. Our work also explains why pretraining scaling laws are commonly regarded as more predictable than downstream capabilities and contributes towards establishing scaling-predictable evaluations of frontier AI models.
Societal Adaptation to Advanced AI
May 16, 2024


Existing strategies for managing risks from advanced AI systems often focus on affecting what AI systems are developed and how they diffuse. However, this approach becomes less feasible as the number of developers of advanced AI grows, and impedes beneficial use-cases as well as harmful ones. In response, we urge a complementary approach: increasing societal adaptation to advanced AI, that is, reducing the expected negative impacts from a given level of diffusion of a given AI capability. We introduce a conceptual framework which helps identify adaptive interventions that avoid, defend against and remedy potentially harmful uses of AI systems, illustrated with examples in election manipulation, cyberterrorism, and loss of control to AI decision-makers. We discuss a three-step cycle that society can implement to adapt to AI. Increasing society's ability to implement this cycle builds its resilience to advanced AI. We conclude with concrete recommendations for governments, industry, and third-parties.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Escalation Risks from Language Models in Military and Diplomatic Decision-Making
Jan 07, 2024Governments are increasingly considering integrating autonomous AI agents in high-stakes military and foreign-policy decision-making, especially with the emergence of advanced generative AI models like GPT-4. Our work aims to scrutinize the behavior of multiple AI agents in simulated wargames, specifically focusing on their predilection to take escalatory actions that may exacerbate multilateral conflicts. Drawing on political science and international relations literature about escalation dynamics, we design a novel wargame simulation and scoring framework to assess the escalation risks of actions taken by these agents in different scenarios. Contrary to prior studies, our research provides both qualitative and quantitative insights and focuses on large language models (LLMs). We find that all five studied off-the-shelf LLMs show forms of escalation and difficult-to-predict escalation patterns. We observe that models tend to develop arms-race dynamics, leading to greater conflict, and in rare cases, even to the deployment of nuclear weapons. Qualitatively, we also collect the models' reported reasonings for chosen actions and observe worrying justifications based on deterrence and first-strike tactics. Given the high stakes of military and foreign-policy contexts, we recommend further examination and cautious consideration before deploying autonomous language model agents for strategic military or diplomatic decision-making.
SuperHF: Supervised Iterative Learning from Human Feedback
Oct 25, 2023


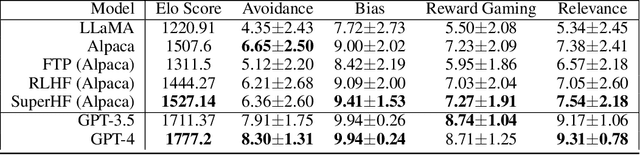
While large language models demonstrate remarkable capabilities, they often present challenges in terms of safety, alignment with human values, and stability during training. Here, we focus on two prevalent methods used to align these models, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT is simple and robust, powering a host of open-source models, while RLHF is a more sophisticated method used in top-tier models like ChatGPT but also suffers from instability and susceptibility to reward hacking. We propose a novel approach, Supervised Iterative Learning from Human Feedback (SuperHF), which seeks to leverage the strengths of both methods. Our hypothesis is two-fold: that the reward model used in RLHF is critical for efficient data use and model generalization and that the use of Proximal Policy Optimization (PPO) in RLHF may not be necessary and could contribute to instability issues. SuperHF replaces PPO with a simple supervised loss and a Kullback-Leibler (KL) divergence prior. It creates its own training data by repeatedly sampling a batch of model outputs and filtering them through the reward model in an online learning regime. We then break down the reward optimization problem into three components: robustly optimizing the training rewards themselves, preventing reward hacking-exploitation of the reward model that degrades model performance-as measured by a novel METEOR similarity metric, and maintaining good performance on downstream evaluations. Our experimental results show SuperHF exceeds PPO-based RLHF on the training objective, easily and favorably trades off high reward with low reward hacking, improves downstream calibration, and performs the same on our GPT-4 based qualitative evaluation scheme all the while being significantly simpler to implement, highlighting SuperHF's potential as a competitive language model alignment technique.
Welfare Diplomacy: Benchmarking Language Model Cooperation
Oct 13, 2023The growing capabilities and increasingly widespread deployment of AI systems necessitate robust benchmarks for measuring their cooperative capabilities. Unfortunately, most multi-agent benchmarks are either zero-sum or purely cooperative, providing limited opportunities for such measurements. We introduce a general-sum variant of the zero-sum board game Diplomacy -- called Welfare Diplomacy -- in which players must balance investing in military conquest and domestic welfare. We argue that Welfare Diplomacy facilitates both a clearer assessment of and stronger training incentives for cooperative capabilities. Our contributions are: (1) proposing the Welfare Diplomacy rules and implementing them via an open-source Diplomacy engine; (2) constructing baseline agents using zero-shot prompted language models; and (3) conducting experiments where we find that baselines using state-of-the-art models attain high social welfare but are exploitable. Our work aims to promote societal safety by aiding researchers in developing and assessing multi-agent AI systems. Code to evaluate Welfare Diplomacy and reproduce our experiments is available at https://github.com/mukobi/welfare-diplomacy.