 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFutureSim: Replaying World Events to Evaluate Adaptive Agents
May 14, 2026AI agents are being increasingly deployed in dynamic, open-ended environments that require adapting to new information as it arrives. To efficiently measure this capability for realistic use-cases, we propose building grounded simulations that replay real-world events in the order they occurred. We build FutureSim, where agents forecast world events beyond their knowledge cutoff while interacting with a chronological replay of the world: real news articles arriving and questions resolving over the simulated period. We evaluate frontier agents in their native harness, testing their ability to predict world events over a three-month period from January to March 2026. FutureSim reveals a clear separation in their capabilities, with the best agent's accuracy being 25%, and many having worse Brier skill score than making no prediction at all. Through careful ablations, we show how FutureSim offers a realistic setting to study emerging research directions like long-horizon test-time adaptation, search, memory, and reasoning about uncertainty. Overall, we hope our benchmark design paves the way to measure AI progress on open-ended adaptation spanning long time-horizons in the real world.
Intrinsic Credit Assignment for Long Horizon Interaction
Feb 12, 2026How can we train agents to navigate uncertainty over long horizons? In this work, we propose ΔBelief-RL, which leverages a language model's own intrinsic beliefs to reward intermediate progress. Our method utilizes the change in the probability an agent assigns to the target solution for credit assignment. By training on synthetic interaction data, ΔBelief-RL teaches information-seeking capabilities that consistently outperform purely outcome-based rewards for Reinforcement Learning, with improvements generalizing to out-of-distribution applications ranging from customer service to personalization. Notably, the performance continues to improve as we scale test-time interactions beyond the training horizon, with interaction-efficiency increasing even on Pass@k metrics. Overall, our work introduces a scalable training strategy for navigating uncertainty over a long-horizon, by enabling credit assignment to intermediate actions via intrinsic ΔBelief rewards.
Rethinking Rubric Generation for Improving LLM Judge and Reward Modeling for Open-ended Tasks
Feb 04, 2026Recently, rubrics have been used to guide LLM judges in capturing subjective, nuanced, multi-dimensional human preferences, and have been extended from evaluation to reward signals for reinforcement fine-tuning (RFT). However, rubric generation remains hard to control: rubrics often lack coverage, conflate dimensions, misalign preference direction, and contain redundant or highly correlated criteria, degrading judge accuracy and producing suboptimal rewards during RFT. We propose RRD, a principled framework for rubric refinement built on a recursive decompose-filter cycle. RRD decomposes coarse rubrics into fine-grained, discriminative criteria, expanding coverage while sharpening separation between responses. A complementary filtering mechanism removes misaligned and redundant rubrics, and a correlation-aware weighting scheme prevents over-representing highly correlated criteria, yielding rubric sets that are informative, comprehensive, and non-redundant. Empirically, RRD delivers large, consistent gains across both evaluation and training: it improves preference-judgment accuracy on JudgeBench and PPE for both GPT-4o and Llama3.1-405B judges, achieving top performance in all settings with up to +17.7 points on JudgeBench. When used as the reward source for RFT on WildChat, it yields substantially stronger and more stable learning signals, boosting reward by up to 160% (Qwen3-4B) and 60% (Llama3.1-8B) versus 10-20% for prior rubric baselines, with gains that transfer to HealthBench-Hard and BiGGen Bench. Overall, RRD establishes recursive rubric refinement as a scalable and interpretable foundation for LLM judging and reward modeling in open-ended domains.
Scaling Open-Ended Reasoning to Predict the Future
Dec 31, 2025High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.
Training AI Co-Scientists Using Rubric Rewards
Dec 29, 2025AI co-scientists are emerging as a tool to assist human researchers in achieving their research goals. A crucial feature of these AI co-scientists is the ability to generate a research plan given a set of aims and constraints. The plan may be used by researchers for brainstorming, or may even be implemented after further refinement. However, language models currently struggle to generate research plans that follow all constraints and implicit requirements. In this work, we study how to leverage the vast corpus of existing research papers to train language models that generate better research plans. We build a scalable, diverse training corpus by automatically extracting research goals and goal-specific grading rubrics from papers across several domains. We then train models for research plan generation via reinforcement learning with self-grading. A frozen copy of the initial policy acts as the grader during training, with the rubrics creating a generator-verifier gap that enables improvements without external human supervision. To validate this approach, we conduct a study with human experts for machine learning research goals, spanning 225 hours. The experts prefer plans generated by our finetuned Qwen3-30B-A3B model over the initial model for 70% of research goals, and approve 84% of the automatically extracted goal-specific grading rubrics. To assess generality, we also extend our approach to research goals from medical papers, and new arXiv preprints, evaluating with a jury of frontier models. Our finetuning yields 12-22% relative improvements and significant cross-domain generalization, proving effective even in problem settings like medical research where execution feedback is infeasible. Together, these findings demonstrate the potential of a scalable, automated training recipe as a step towards improving general AI co-scientists.
Compute as Teacher: Turning Inference Compute Into Reference-Free Supervision
Sep 17, 2025Where do learning signals come from when there is no ground truth in post-training? We propose turning exploration into supervision through Compute as Teacher (CaT), which converts the model's own exploration at inference-time into reference-free supervision by synthesizing a single reference from a group of parallel rollouts and then optimizing toward it. Concretely, the current policy produces a group of rollouts; a frozen anchor (the initial policy) reconciles omissions and contradictions to estimate a reference, turning extra inference-time compute into a teacher signal. We turn this into rewards in two regimes: (i) verifiable tasks use programmatic equivalence on final answers; (ii) non-verifiable tasks use self-proposed rubrics-binary, auditable criteria scored by an independent LLM judge, with reward given by the fraction satisfied. Unlike selection methods (best-of-N, majority, perplexity, or judge scores), synthesis may disagree with the majority and be correct even when all rollouts are wrong; performance scales with the number of rollouts. As a test-time procedure, CaT improves Gemma 3 4B, Qwen 3 4B, and Llama 3.1 8B (up to +27% on MATH-500; +12% on HealthBench). With reinforcement learning (CaT-RL), we obtain further gains (up to +33% and +30%), with the trained policy surpassing the initial teacher signal.
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs
Sep 11, 2025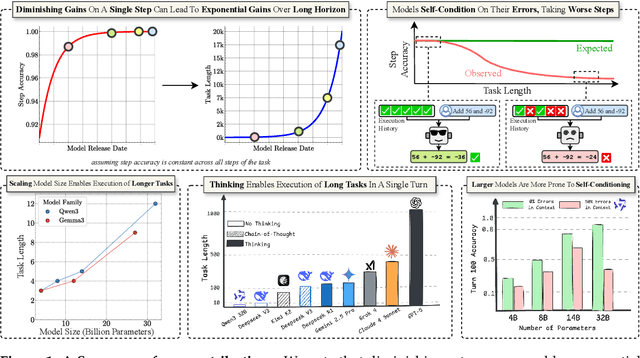
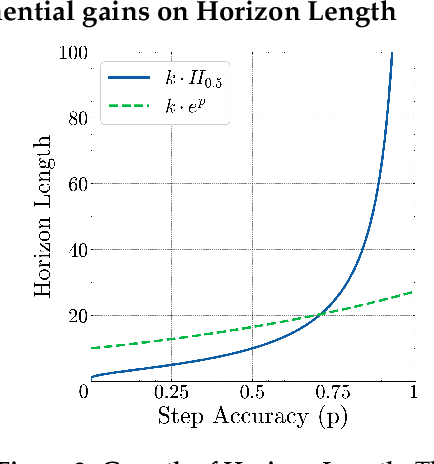
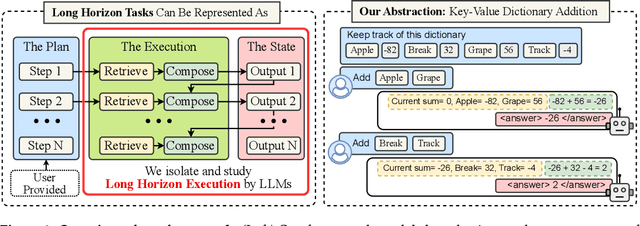
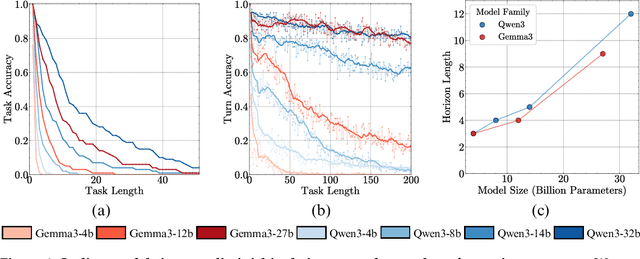
Does continued scaling of large language models (LLMs) yield diminishing returns? Real-world value often stems from the length of task an agent can complete. We start this work by observing the simple but counterintuitive fact that marginal gains in single-step accuracy can compound into exponential improvements in the length of a task a model can successfully complete. Then, we argue that failures of LLMs when simple tasks are made longer arise from mistakes in execution, rather than an inability to reason. We propose isolating execution capability, by explicitly providing the knowledge and plan needed to solve a long-horizon task. We find that larger models can correctly execute significantly more turns even when small models have 100\% single-turn accuracy. We observe that the per-step accuracy of models degrades as the number of steps increases. This is not just due to long-context limitations -- curiously, we observe a self-conditioning effect -- models become more likely to make mistakes when the context contains their errors from prior turns. Self-conditioning does not reduce by just scaling the model size. In contrast, recent thinking models do not self-condition, and can also execute much longer tasks in a single turn. We conclude by benchmarking frontier thinking models on the length of task they can execute in a single turn. Overall, by focusing on the ability to execute, we hope to reconcile debates on how LLMs can solve complex reasoning problems yet fail at simple tasks when made longer, and highlight the massive benefits of scaling model size and sequential test-time compute for long-horizon tasks.
What if I ask in \textit{alia lingua}? Measuring Functional Similarity Across Languages
Sep 04, 2025How similar are model outputs across languages? In this work, we study this question using a recently proposed model similarity metric $\kappa_p$ applied to 20 languages and 47 subjects in GlobalMMLU. Our analysis reveals that a model's responses become increasingly consistent across languages as its size and capability grow. Interestingly, models exhibit greater cross-lingual consistency within themselves than agreement with other models prompted in the same language. These results highlight not only the value of $\kappa_p$ as a practical tool for evaluating multilingual reliability, but also its potential to guide the development of more consistent multilingual systems.
Answer Matching Outperforms Multiple Choice for Language Model Evaluation
Jul 03, 2025Multiple choice benchmarks have long been the workhorse of language model evaluation because grading multiple choice is objective and easy to automate. However, we show multiple choice questions from popular benchmarks can often be answered without even seeing the question. These shortcuts arise from a fundamental limitation of discriminative evaluation not shared by evaluations of the model's free-form, generative answers. Until recently, there appeared to be no viable, scalable alternative to multiple choice--but, we show that this has changed. We consider generative evaluation via what we call answer matching: Give the candidate model the question without the options, have it generate a free-form response, then use a modern language model with the reference answer to determine if the response matches the reference. To compare the validity of different evaluation strategies, we annotate MMLU-Pro and GPQA-Diamond to obtain human grading data, and measure the agreement of each evaluation approach. We find answer matching using recent models--even small ones--achieves near-perfect agreement, in the range of inter-annotator agreement. In contrast, both multiple choice evaluation and using LLM-as-a-judge without reference answers aligns poorly with human grading. Improving evaluations via answer matching is not merely a conceptual concern: the rankings of several models change significantly when evaluating their free-form responses with answer matching. In light of these findings, we discuss how to move the evaluation ecosystem from multiple choice to answer matching.
Can Language Models Falsify? Evaluating Algorithmic Reasoning with Counterexample Creation
Feb 26, 2025There is growing excitement about the potential of Language Models (LMs) to accelerate scientific discovery. Falsifying hypotheses is key to scientific progress, as it allows claims to be iteratively refined over time. This process requires significant researcher effort, reasoning, and ingenuity. Yet current benchmarks for LMs predominantly assess their ability to generate solutions rather than challenge them. We advocate for developing benchmarks that evaluate this inverse capability - creating counterexamples for subtly incorrect solutions. To demonstrate this approach, we start with the domain of algorithmic problem solving, where counterexamples can be evaluated automatically using code execution. Specifically, we introduce REFUTE, a dynamically updating benchmark that includes recent problems and incorrect submissions from programming competitions, where human experts successfully identified counterexamples. Our analysis finds that the best reasoning agents, even OpenAI o3-mini (high) with code execution feedback, can create counterexamples for only <9% of incorrect solutions in REFUTE, even though ratings indicate its ability to solve up to 48% of these problems from scratch. We hope our work spurs progress in evaluating and enhancing LMs' ability to falsify incorrect solutions - a capability that is crucial for both accelerating research and making models self-improve through reliable reflective reasoning.