 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Open-Ended Reasoning to Predict the Future
Dec 31, 2025High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.
Answer Matching Outperforms Multiple Choice for Language Model Evaluation
Jul 03, 2025Multiple choice benchmarks have long been the workhorse of language model evaluation because grading multiple choice is objective and easy to automate. However, we show multiple choice questions from popular benchmarks can often be answered without even seeing the question. These shortcuts arise from a fundamental limitation of discriminative evaluation not shared by evaluations of the model's free-form, generative answers. Until recently, there appeared to be no viable, scalable alternative to multiple choice--but, we show that this has changed. We consider generative evaluation via what we call answer matching: Give the candidate model the question without the options, have it generate a free-form response, then use a modern language model with the reference answer to determine if the response matches the reference. To compare the validity of different evaluation strategies, we annotate MMLU-Pro and GPQA-Diamond to obtain human grading data, and measure the agreement of each evaluation approach. We find answer matching using recent models--even small ones--achieves near-perfect agreement, in the range of inter-annotator agreement. In contrast, both multiple choice evaluation and using LLM-as-a-judge without reference answers aligns poorly with human grading. Improving evaluations via answer matching is not merely a conceptual concern: the rankings of several models change significantly when evaluating their free-form responses with answer matching. In light of these findings, we discuss how to move the evaluation ecosystem from multiple choice to answer matching.
Proportional Aggregation of Preferences for Sequential Decision Making
Jun 26, 2023
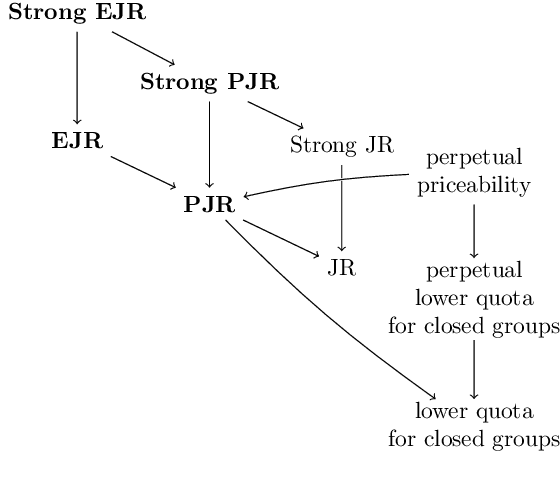
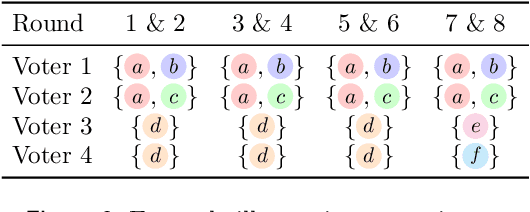
We study the problem of fair sequential decision making given voter preferences. In each round, a decision rule must choose a decision from a set of alternatives where each voter reports which of these alternatives they approve. Instead of going with the most popular choice in each round, we aim for proportional representation. We formalize this aim using axioms based on Proportional Justified Representation (PJR), which were proposed in the literature on multi-winner voting and were recently adapted to multi-issue decision making. The axioms require that every group of $\alpha\%$ of the voters, if it agrees in every round (i.e., approves a common alternative), then those voters must approve at least $\alpha\%$ of the decisions. A stronger version of the axioms requires that every group of $\alpha\%$ of the voters that agrees in a $\beta$ fraction of rounds must approve $\beta\cdot\alpha\%$ of the decisions. We show that three attractive voting rules satisfy axioms of this style. One of them (Sequential Phragm\'en) makes its decisions online, and the other two satisfy strengthened versions of the axioms but make decisions semi-online (Method of Equal Shares) or fully offline (Proportional Approval Voting). The first two are polynomial-time computable, and the latter is based on an NP-hard optimization, but it admits a polynomial-time local search algorithm that satisfies the same axiomatic properties. We present empirical results about the performance of these rules based on synthetic data and U.S. political elections. We also run experiments where votes are cast by preference models trained on user responses from the moral machine dataset about ethical dilemmas.
Informed Steiner Trees: Sampling and Pruning for Multi-Goal Path Finding in High Dimensions
May 09, 2022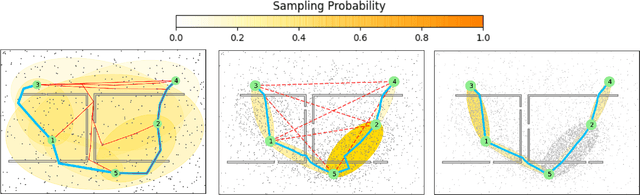
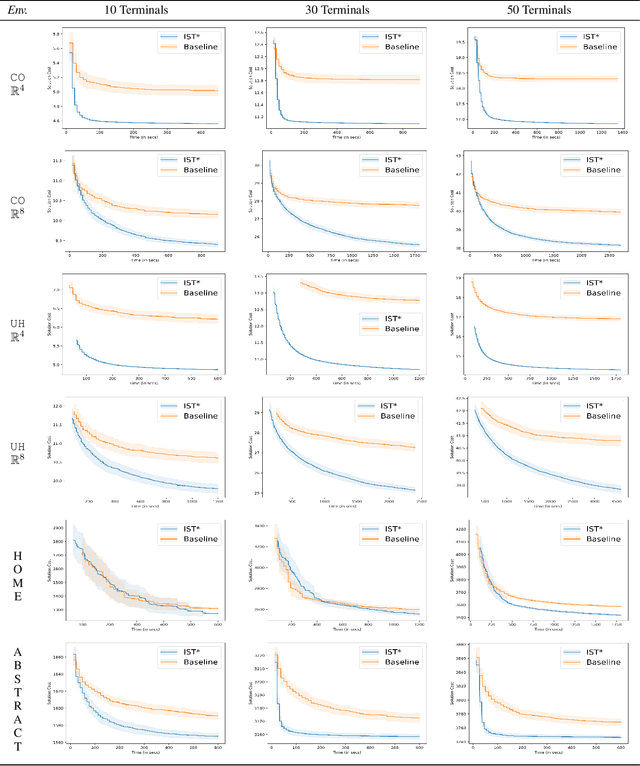
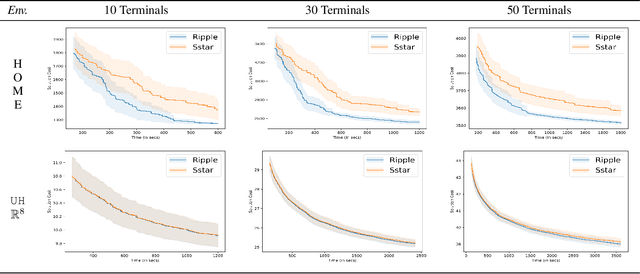
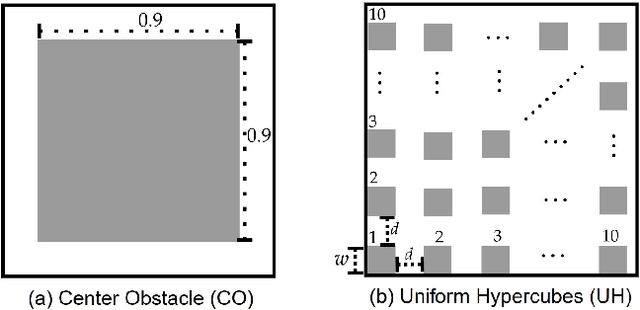
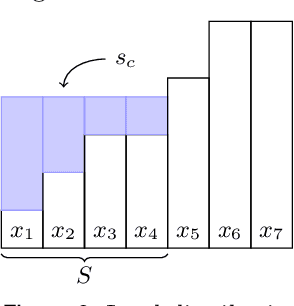
We interleave sampling based motion planning methods with pruning ideas from minimum spanning tree algorithms to develop a new approach for solving a Multi-Goal Path Finding (MGPF) problem in high dimensional spaces. The approach alternates between sampling points from selected regions in the search space and de-emphasizing regions that may not lead to good solutions for MGPF. Our approach provides an asymptotic, 2-approximation guarantee for MGPF. We also present extensive numerical results to illustrate the advantages of our proposed approach over uniform sampling in terms of the quality of the solutions found and computation speed.