 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrect Looks Better: Pairwise Comparisons Reveal Accuracy Rankings
Jun 08, 2026Pairwise comparisons combined with aggregation methods like Elo have become central to evaluating generative models, yet concerns remain that they reward superficial stylistic cues or display judge biases. In a more positive turn, we show that model rankings from pairwise comparisons strongly agree with ground-truth-based accuracy rankings when such ground truth is available for comparison. By converting five well-known benchmarks into free-form generative evaluations, we find that Elo rankings achieve a Spearman correlation above 0.9 with accuracy rankings and substantially outperform direct evaluation when the judge is weak. Furthermore, style and judge bias have only minor effects on model rankings, despite most judgments occurring on pairs where both candidate answers are correct (or incorrect). On such pairs, we find that repetition after the final answer (echo) is a causal driver of judge preference.
FutureSim: Replaying World Events to Evaluate Adaptive Agents
May 14, 2026AI agents are being increasingly deployed in dynamic, open-ended environments that require adapting to new information as it arrives. To efficiently measure this capability for realistic use-cases, we propose building grounded simulations that replay real-world events in the order they occurred. We build FutureSim, where agents forecast world events beyond their knowledge cutoff while interacting with a chronological replay of the world: real news articles arriving and questions resolving over the simulated period. We evaluate frontier agents in their native harness, testing their ability to predict world events over a three-month period from January to March 2026. FutureSim reveals a clear separation in their capabilities, with the best agent's accuracy being 25%, and many having worse Brier skill score than making no prediction at all. Through careful ablations, we show how FutureSim offers a realistic setting to study emerging research directions like long-horizon test-time adaptation, search, memory, and reasoning about uncertainty. Overall, we hope our benchmark design paves the way to measure AI progress on open-ended adaptation spanning long time-horizons in the real world.
Computational Arbitrage in AI Model Markets
Mar 23, 2026Consider a market of competing model providers selling query access to models with varying costs and capabilities. Customers submit problem instances and are willing to pay up to a budget for a verifiable solution. An arbitrageur efficiently allocates inference budget across providers to undercut the market, thus creating a competitive offering with no model-development risk. In this work, we initiate the study of arbitrage in AI model markets, empirically demonstrating the viability of arbitrage and illustrating its economic consequences. We conduct an in-depth case study of SWE-bench GitHub issue resolution using two representative models, GPT-5 mini and DeepSeek v3.2. In this verifiable domain, simple arbitrage strategies generate net profit margins of up to 40%. Robust arbitrage strategies that generalize across different domains remain profitable. Distillation further creates strong arbitrage opportunities, potentially at the expense of the teacher model's revenue. Multiple competing arbitrageurs drive down consumer prices, reducing the marginal revenue of model providers. At the same time, arbitrage reduces market segmentation and facilitates market entry for smaller model providers by enabling earlier revenue capture. Our results suggest that arbitrage can be a powerful force in AI model markets with implications for model development, distillation, and deployment.
Leaderboard Incentives: Model Rankings under Strategic Post-Training
Mar 09, 2026Influential benchmarks incentivize competing model developers to strategically allocate post-training resources toward improvements on the leaderboard, a phenomenon dubbed benchmaxxing or training on the test task. In this work, we initiate a principled study of the incentive structure that benchmarks induce. We model benchmarking as a Stackelberg game between a benchmark designer who chooses an evaluation protocol and multiple model developers who compete simultaneously in a subgame given by the designer's choice. Each competitor has a model of unknown latent quality and can inflate its observed score by allocating resources to benchmark-specific improvements. First, we prove that current benchmarks induce games for which no Nash equilibrium between model developers exists. This result suggests one explanation for why current practice leads to misaligned incentives, prompting model developers to strategize in opaque ways. However, we prove that under mild conditions, a recently proposed evaluation protocol, called tune-before-test, induces a benchmark with a unique Nash equilibrium that ranks models by latent quality. This positive result demonstrates that benchmarks need not set bad incentives, even if current evaluations do.
Good Allocations from Bad Estimates
Jan 09, 2026Conditional average treatment effect (CATE) estimation is the de facto gold standard for targeting a treatment to a heterogeneous population. The method estimates treatment effects up to an error $ε> 0$ in each of $M$ different strata of the population, targeting individuals in decreasing order of estimated treatment effect until the budget runs out. In general, this method requires $O(M/ε^2)$ samples. This is best possible if the goal is to estimate all treatment effects up to an $ε$ error. In this work, we show how to achieve the same total treatment effect as CATE with only $O(M/ε)$ samples for natural distributions of treatment effects. The key insight is that coarse estimates suffice for near-optimal treatment allocations. In addition, we show that budget flexibility can further reduce the sample complexity of allocation. Finally, we evaluate our algorithm on various real-world RCT datasets. In all cases, it finds nearly optimal treatment allocations with surprisingly few samples. Our work highlights the fundamental distinction between treatment effect estimation and treatment allocation: the latter requires far fewer samples.
Scaling Open-Ended Reasoning to Predict the Future
Dec 31, 2025High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train language models to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on language model forecasting broadly accessible.
Learning on the Job: Test-Time Curricula for Targeted Reinforcement Learning
Oct 06, 2025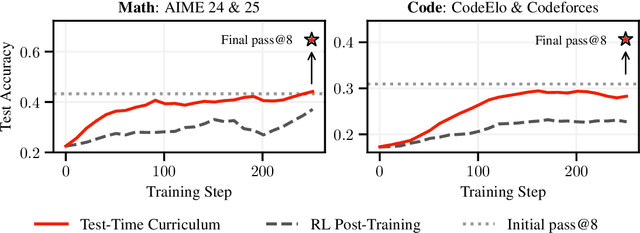
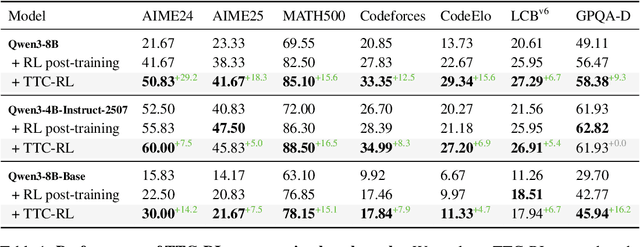
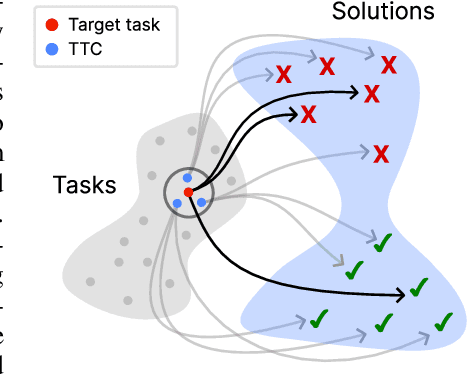
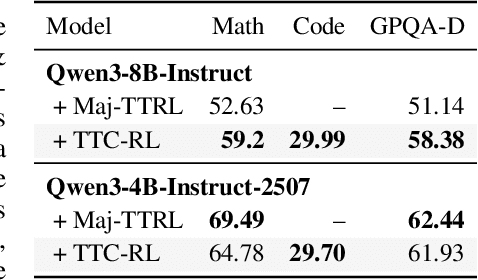
Humans are good at learning on the job: We learn how to solve the tasks we face as we go along. Can a model do the same? We propose an agent that assembles a task-specific curriculum, called test-time curriculum (TTC-RL), and applies reinforcement learning to continue training the model for its target task. The test-time curriculum avoids time-consuming human curation of datasets by automatically selecting the most task-relevant data from a large pool of available training data. Our experiments demonstrate that reinforcement learning on a test-time curriculum consistently improves the model on its target tasks, across a variety of evaluations and models. Notably, on challenging math and coding benchmarks, TTC-RL improves the pass@1 of Qwen3-8B by approximately 1.8x on AIME25 and 2.1x on CodeElo. Moreover, we find that TTC-RL significantly raises the performance ceiling compared to the initial model, increasing pass@8 on AIME25 from 40% to 62% and on CodeElo from 28% to 43%. Our findings show the potential of test-time curricula in extending the test-time scaling paradigm to continual training on thousands of task-relevant experiences during test-time.
Answer Matching Outperforms Multiple Choice for Language Model Evaluation
Jul 03, 2025Multiple choice benchmarks have long been the workhorse of language model evaluation because grading multiple choice is objective and easy to automate. However, we show multiple choice questions from popular benchmarks can often be answered without even seeing the question. These shortcuts arise from a fundamental limitation of discriminative evaluation not shared by evaluations of the model's free-form, generative answers. Until recently, there appeared to be no viable, scalable alternative to multiple choice--but, we show that this has changed. We consider generative evaluation via what we call answer matching: Give the candidate model the question without the options, have it generate a free-form response, then use a modern language model with the reference answer to determine if the response matches the reference. To compare the validity of different evaluation strategies, we annotate MMLU-Pro and GPQA-Diamond to obtain human grading data, and measure the agreement of each evaluation approach. We find answer matching using recent models--even small ones--achieves near-perfect agreement, in the range of inter-annotator agreement. In contrast, both multiple choice evaluation and using LLM-as-a-judge without reference answers aligns poorly with human grading. Improving evaluations via answer matching is not merely a conceptual concern: the rankings of several models change significantly when evaluating their free-form responses with answer matching. In light of these findings, we discuss how to move the evaluation ecosystem from multiple choice to answer matching.
How Benchmark Prediction from Fewer Data Misses the Mark
Jun 09, 2025



Large language model (LLM) evaluation is increasingly costly, prompting interest in methods that speed up evaluation by shrinking benchmark datasets. Benchmark prediction (also called efficient LLM evaluation) aims to select a small subset of evaluation points and predict overall benchmark performance from that subset. In this paper, we systematically assess the strengths and limitations of 11 benchmark prediction methods across 19 diverse benchmarks. First, we identify a highly competitive baseline: Take a random sample and fit a regression model on the sample to predict missing entries. Outperforming most existing methods, this baseline challenges the assumption that careful subset selection is necessary for benchmark prediction. Second, we discover that all existing methods crucially depend on model similarity. They work best when interpolating scores among similar models. The effectiveness of benchmark prediction sharply declines when new models have higher accuracy than previously seen models. In this setting of extrapolation, none of the previous methods consistently beat a simple average over random samples. To improve over the sample average, we introduce a new method inspired by augmented inverse propensity weighting. This method consistently outperforms the random sample average even for extrapolation. However, its performance still relies on model similarity and the gains are modest in general. This shows that benchmark prediction fails just when it is most needed: at the evaluation frontier, where the goal is to evaluate new models of unknown capabilities.
Limits to scalable evaluation at the frontier: LLM as Judge won't beat twice the data
Oct 17, 2024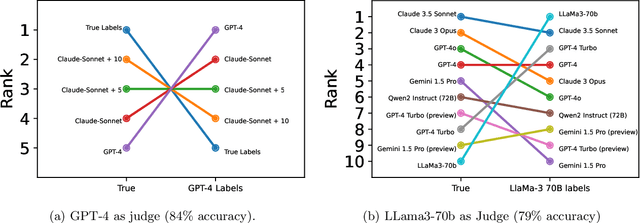
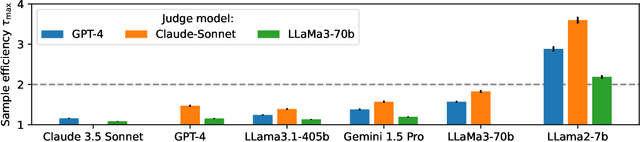
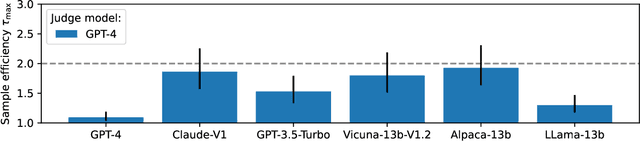
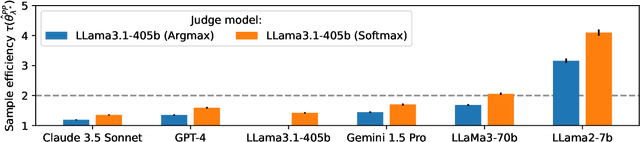
High quality annotations are increasingly a bottleneck in the explosively growing machine learning ecosystem. Scalable evaluation methods that avoid costly annotation have therefore become an important research ambition. Many hope to use strong existing models in lieu of costly labels to provide cheap model evaluations. Unfortunately, this method of using models as judges introduces biases, such as self-preferencing, that can distort model comparisons. An emerging family of debiasing tools promises to fix these issues by using a few high quality labels to debias a large number of model judgments. In this paper, we study how far such debiasing methods, in principle, can go. Our main result shows that when the judge is no more accurate than the evaluated model, no debiasing method can decrease the required amount of ground truth labels by more than half. Our result speaks to the severe limitations of the LLM-as-a-judge paradigm at the evaluation frontier where the goal is to assess newly released models that are possibly better than the judge. Through an empirical evaluation, we demonstrate that the sample size savings achievable in practice are even more modest than what our theoretical limit suggests. Along the way, our work provides new observations about debiasing methods for model evaluation, and points out promising avenues for future work.