 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROC-n-reroll: How verifier imperfection affects test-time scaling
Jul 16, 2025Test-time scaling aims to improve language model performance by leveraging additional compute during inference. While many works have empirically studied techniques like Best-of-N (BoN) and rejection sampling that make use of a verifier to enable test-time scaling, there is little theoretical understanding of how verifier imperfection affects performance. In this work, we address this gap. Specifically, we prove how instance-level accuracy of these methods is precisely characterized by the geometry of the verifier's ROC curve. Interestingly, while scaling is determined by the local geometry of the ROC curve for rejection sampling, it depends on global properties of the ROC curve for BoN. As a consequence when the ROC curve is unknown, it is impossible to extrapolate the performance of rejection sampling based on the low-compute regime. Furthermore, while rejection sampling outperforms BoN for fixed compute, in the infinite-compute limit both methods converge to the same level of accuracy, determined by the slope of the ROC curve near the origin. Our theoretical results are confirmed by experiments on GSM8K using different versions of Llama and Qwen to generate and verify solutions.
Evaluating language models as risk scores
Jul 19, 2024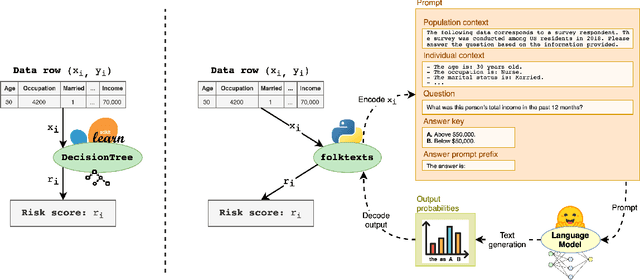
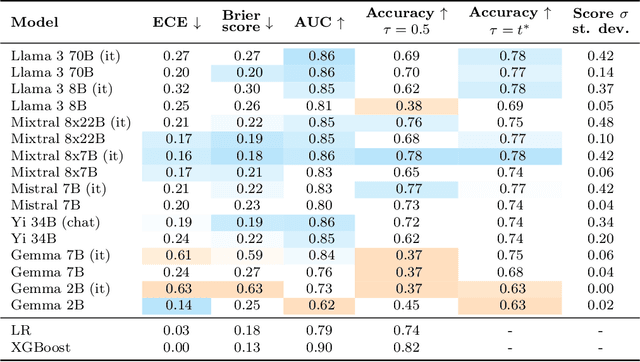
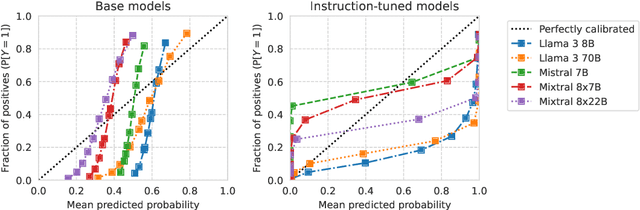
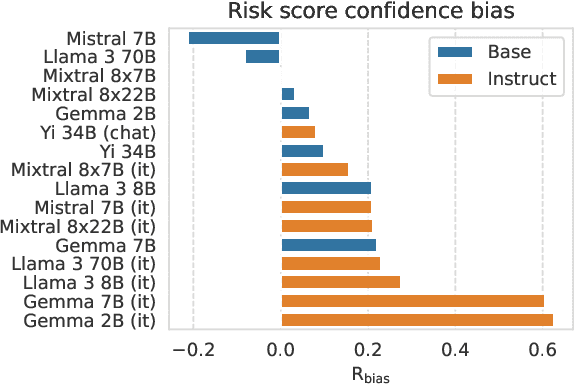
Current question-answering benchmarks predominantly focus on accuracy in realizable prediction tasks. Conditioned on a question and answer-key, does the most likely token match the ground truth? Such benchmarks necessarily fail to evaluate language models' ability to quantify outcome uncertainty. In this work, we focus on the use of language models as risk scores for unrealizable prediction tasks. We introduce folktexts, a software package to systematically generate risk scores using large language models, and evaluate them against benchmark prediction tasks. Specifically, the package derives natural language tasks from US Census data products, inspired by popular tabular data benchmarks. A flexible API allows for any task to be constructed out of 28 census features whose values are mapped to prompt-completion pairs. We demonstrate the utility of folktexts through a sweep of empirical insights on 16 recent large language models, inspecting risk scores, calibration curves, and diverse evaluation metrics. We find that zero-shot risk sores have high predictive signal while being widely miscalibrated: base models overestimate outcome uncertainty, while instruction-tuned models underestimate uncertainty and generate over-confident risk scores.
Unprocessing Seven Years of Algorithmic Fairness
Jun 15, 2023



Seven years ago, researchers proposed a postprocessing method to equalize the error rates of a model across different demographic groups. The work launched hundreds of papers purporting to improve over the postprocessing baseline. We empirically evaluate these claims through thousands of model evaluations on several tabular datasets. We find that the fairness-accuracy Pareto frontier achieved by postprocessing contains all other methods we were feasibly able to evaluate. In doing so, we address two common methodological errors that have confounded previous observations. One relates to the comparison of methods with different unconstrained base models. The other concerns methods achieving different levels of constraint relaxation. At the heart of our study is a simple idea we call unprocessing that roughly corresponds to the inverse of postprocessing. Unprocessing allows for a direct comparison of methods using different underlying models and levels of relaxation. Interpreting our findings, we recall a widely overlooked theoretical argument, present seven years ago, that accurately predicted what we observe.
Understanding Unfairness in Fraud Detection through Model and Data Bias Interactions
Jul 13, 2022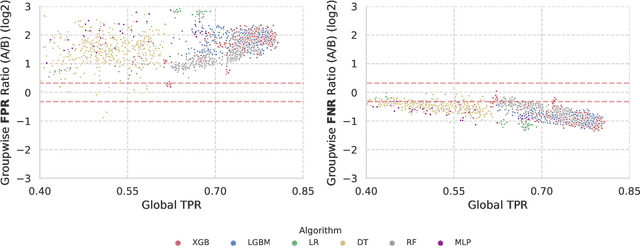
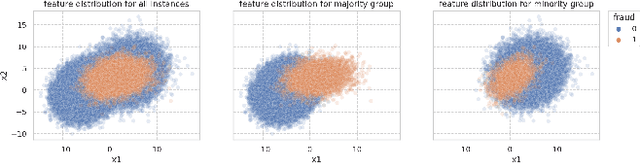
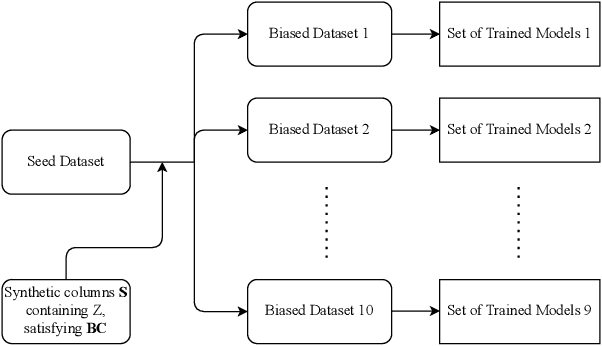
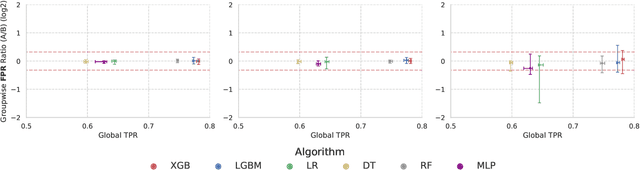
In recent years, machine learning algorithms have become ubiquitous in a multitude of high-stakes decision-making applications. The unparalleled ability of machine learning algorithms to learn patterns from data also enables them to incorporate biases embedded within. A biased model can then make decisions that disproportionately harm certain groups in society -- limiting their access to financial services, for example. The awareness of this problem has given rise to the field of Fair ML, which focuses on studying, measuring, and mitigating unfairness in algorithmic prediction, with respect to a set of protected groups (e.g., race or gender). However, the underlying causes for algorithmic unfairness still remain elusive, with researchers divided between blaming either the ML algorithms or the data they are trained on. In this work, we maintain that algorithmic unfairness stems from interactions between models and biases in the data, rather than from isolated contributions of either of them. To this end, we propose a taxonomy to characterize data bias and we study a set of hypotheses regarding the fairness-accuracy trade-offs that fairness-blind ML algorithms exhibit under different data bias settings. On our real-world account-opening fraud use case, we find that each setting entails specific trade-offs, affecting fairness in expected value and variance -- the latter often going unnoticed. Moreover, we show how algorithms compare differently in terms of accuracy and fairness, depending on the biases affecting the data. Finally, we note that under specific data bias conditions, simple pre-processing interventions can successfully balance group-wise error rates, while the same techniques fail in more complex settings.
Promoting Fairness through Hyperparameter Optimization
Mar 23, 2021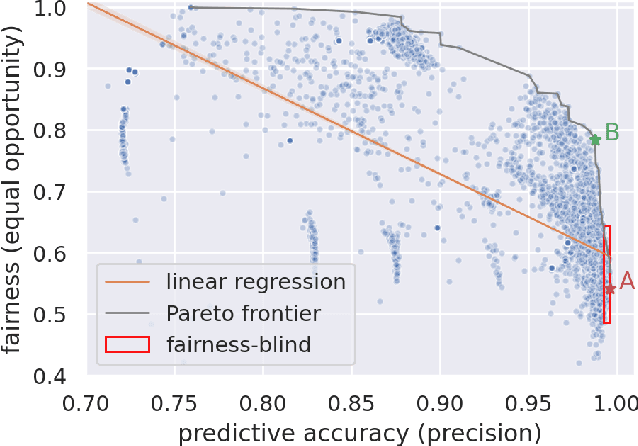

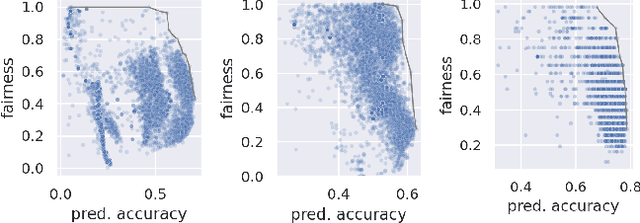
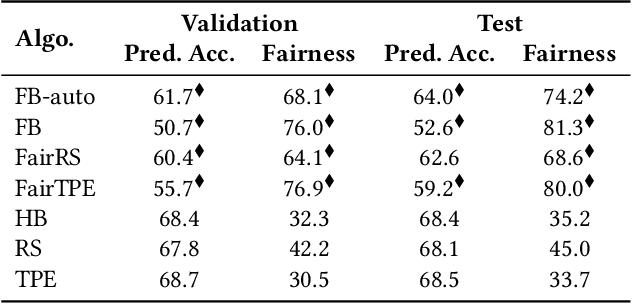
Considerable research effort has been guided towards algorithmic fairness but real-world adoption of bias reduction techniques is still scarce. Existing methods are either metric- or model-specific, require access to sensitive attributes at inference time, or carry high development and deployment costs. This work explores, in the context of a real-world fraud detection application, the unfairness that emerges from traditional ML model development, and how to mitigate it with a simple and easily deployed intervention: fairness-aware hyperparameter optimization (HO). We propose and evaluate fairness-aware variants of three popular HO algorithms: Fair Random Search, Fair TPE, and Fairband. Our method enables practitioners to adapt pre-existing business operations to accommodate fairness objectives in a frictionless way and with controllable fairness-accuracy trade-offs. Additionally, it can be coupled with existing bias reduction techniques to tune their hyperparameters. We validate our approach on a real-world bank account opening fraud use case, as well as on three datasets from the fairness literature. Results show that, without extra training cost, it is feasible to find models with 111% average fairness increase and just 6% decrease in predictive accuracy, when compared to standard fairness-blind HO.
TimeSHAP: Explaining Recurrent Models through Sequence Perturbations
Nov 30, 2020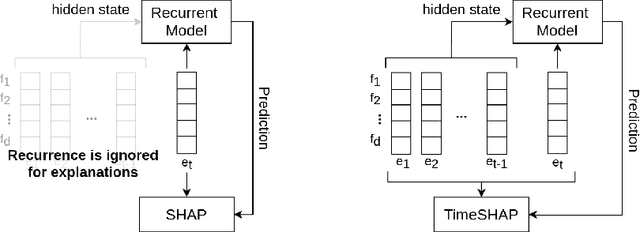
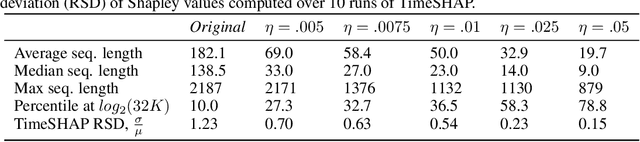
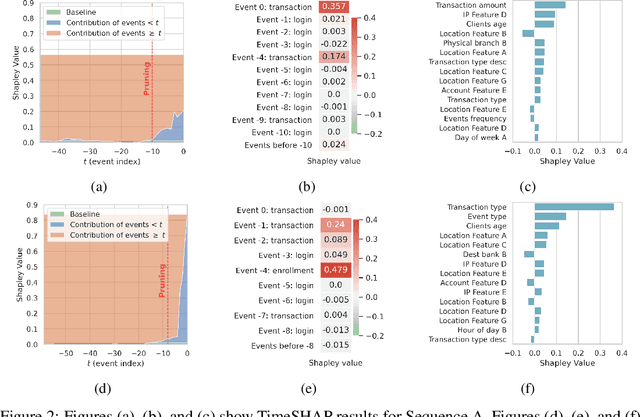
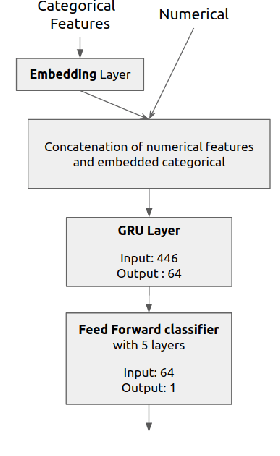
Recurrent neural networks are a standard building block in numerous machine learning domains, from natural language processing to time-series classification. While their application has grown ubiquitous, understanding of their inner workings is still lacking. In practice, the complex decision-making in these models is seen as a black-box, creating a tension between accuracy and interpretability. Moreover, the ability to understand the reasoning process of a model is important in order to debug it and, even more so, to build trust in its decisions. Although considerable research effort has been guided towards explaining black-box models in recent years, recurrent models have received relatively little attention. Any method that aims to explain decisions from a sequence of instances should assess, not only feature importance, but also event importance, an ability that is missing from state-of-the-art explainers. In this work, we contribute to filling these gaps by presenting TimeSHAP, a model-agnostic recurrent explainer that leverages KernelSHAP's sound theoretical footing and strong empirical results. As the input sequence may be arbitrarily long, we further propose a pruning method that is shown to dramatically improve its efficiency in practice.
A Bandit-Based Algorithm for Fairness-Aware Hyperparameter Optimization
Oct 22, 2020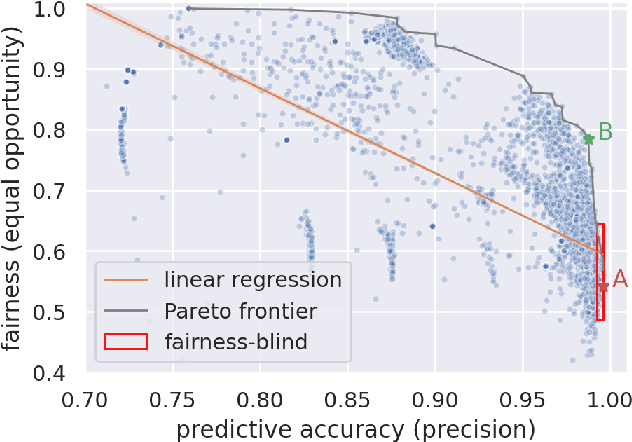

Considerable research effort has been guided towards algorithmic fairness but there is still no major breakthrough. In practice, an exhaustive search over all possible techniques and hyperparameters is needed to find optimal fairness-accuracy trade-offs. Hence, coupled with the lack of tools for ML practitioners, real-world adoption of bias reduction methods is still scarce. To address this, we present Fairband, a bandit-based fairness-aware hyperparameter optimization (HO) algorithm. Fairband is conceptually simple, resource-efficient, easy to implement, and agnostic to both the objective metrics, model types and the hyperparameter space being explored. Moreover, by introducing fairness notions into HO, we enable seamless and efficient integration of fairness objectives into real-world ML pipelines. We compare Fairband with popular HO methods on four real-world decision-making datasets. We show that Fairband can efficiently navigate the fairness-accuracy trade-off through hyperparameter optimization. Furthermore, without extra training cost, it consistently finds configurations attaining substantially improved fairness at a comparatively small decrease in predictive accuracy.