 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations
Jan 22, 2021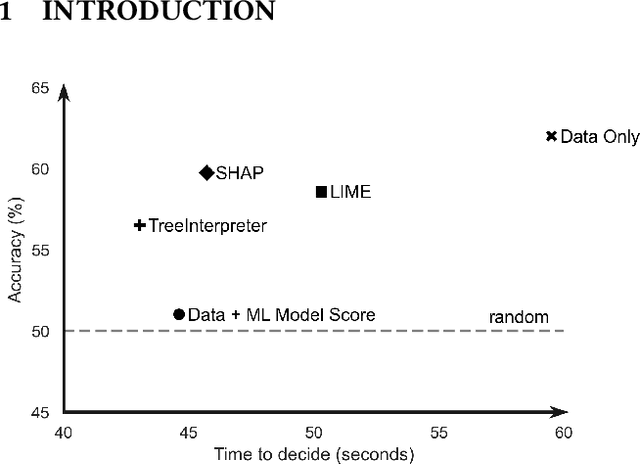
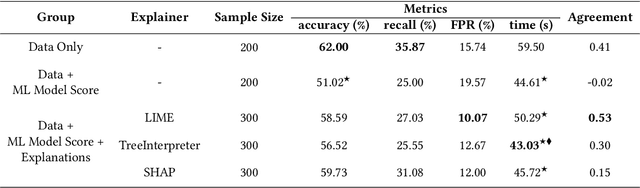
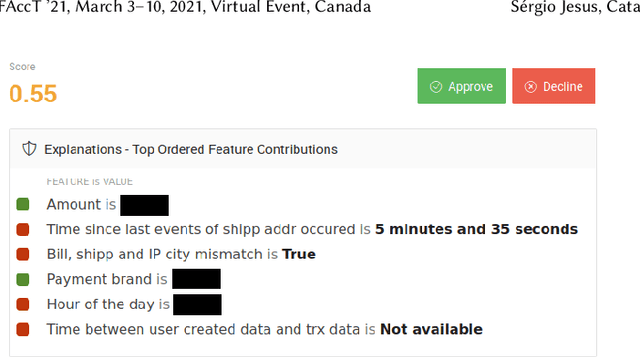
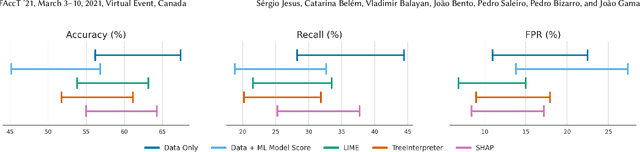
There have been several research works proposing new Explainable AI (XAI) methods designed to generate model explanations having specific properties, or desiderata, such as fidelity, robustness, or human-interpretability. However, explanations are seldom evaluated based on their true practical impact on decision-making tasks. Without that assessment, explanations might be chosen that, in fact, hurt the overall performance of the combined system of ML model + end-users. This study aims to bridge this gap by proposing XAI Test, an application-grounded evaluation methodology tailored to isolate the impact of providing the end-user with different levels of information. We conducted an experiment following XAI Test to evaluate three popular post-hoc explanation methods -- LIME, SHAP, and TreeInterpreter -- on a real-world fraud detection task, with real data, a deployed ML model, and fraud analysts. During the experiment, we gradually increased the information provided to the fraud analysts in three stages: Data Only, i.e., just transaction data without access to model score nor explanations, Data + ML Model Score, and Data + ML Model Score + Explanations. Using strong statistical analysis, we show that, in general, these popular explainers have a worse impact than desired. Some of the conclusion highlights include: i) showing Data Only results in the highest decision accuracy and the slowest decision time among all variants tested, ii) all the explainers improve accuracy over the Data + ML Model Score variant but still result in lower accuracy when compared with Data Only; iii) LIME was the least preferred by users, probably due to its substantially lower variability of explanations from case to case.
TimeSHAP: Explaining Recurrent Models through Sequence Perturbations
Nov 30, 2020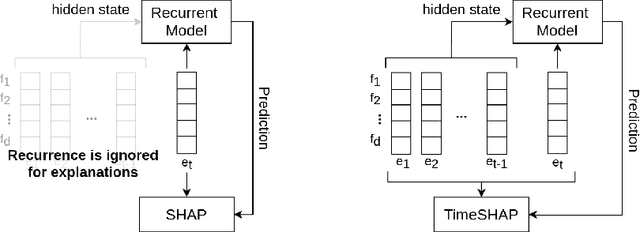
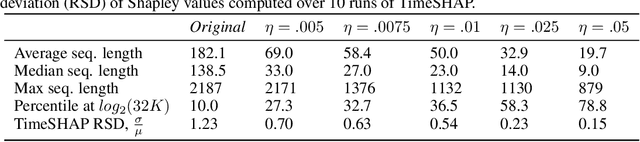
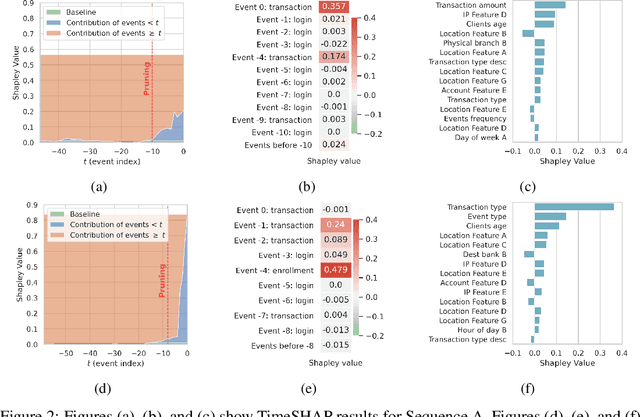
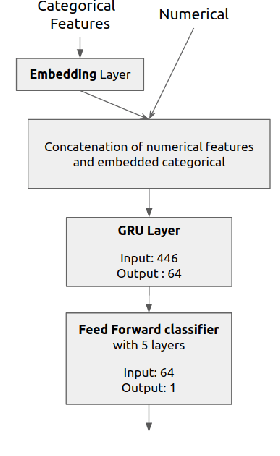
Recurrent neural networks are a standard building block in numerous machine learning domains, from natural language processing to time-series classification. While their application has grown ubiquitous, understanding of their inner workings is still lacking. In practice, the complex decision-making in these models is seen as a black-box, creating a tension between accuracy and interpretability. Moreover, the ability to understand the reasoning process of a model is important in order to debug it and, even more so, to build trust in its decisions. Although considerable research effort has been guided towards explaining black-box models in recent years, recurrent models have received relatively little attention. Any method that aims to explain decisions from a sequence of instances should assess, not only feature importance, but also event importance, an ability that is missing from state-of-the-art explainers. In this work, we contribute to filling these gaps by presenting TimeSHAP, a model-agnostic recurrent explainer that leverages KernelSHAP's sound theoretical footing and strong empirical results. As the input sequence may be arbitrarily long, we further propose a pruning method that is shown to dramatically improve its efficiency in practice.