 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking XAI Evaluation: A Human-Centered Audit of Shapley Benchmarks in High-Stakes Settings
Apr 24, 2026Shapley values are a cornerstone of explainable AI, yet their proliferation into competing formulations has created a fragmented landscape with little consensus on practical deployment. While theoretical differences are well-documented, evaluation remains reliant on quantitative proxies whose alignment with human utility is unverified. In this work, we use a unified amortized framework to isolate semantic differences between eight Shapley variants under the low-latency constraints of operational risk workflows. We conduct a large-scale empirical evaluation across four risk datasets and a realistic fraud-detection environment involving professional analysts and 3,735 case reviews. Our results reveal a fundamental misalignment: standard quantitative metrics, such as sparsity and faithfulness, are decoupled from human-perceived clarity and decision utility. Furthermore, while no formulation improved objective analyst performance, explanations consistently increased decision confidence, signaling a critical risk of automation bias in high-stakes settings. These findings suggest that current evaluation proxies are insufficient for predicting downstream human impact, and we provide evidence-based guidance for selecting formulations and metrics in operational decision systems.
Fair-OBNC: Correcting Label Noise for Fairer Datasets
Oct 08, 2024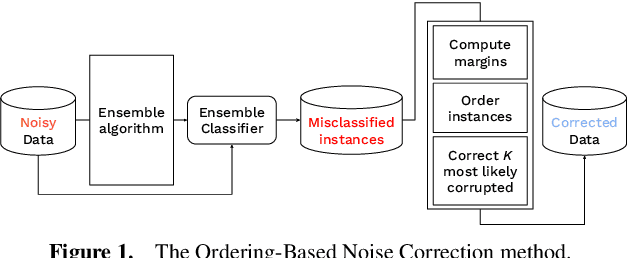
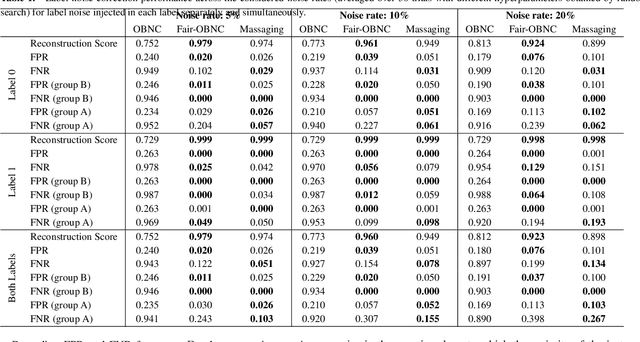
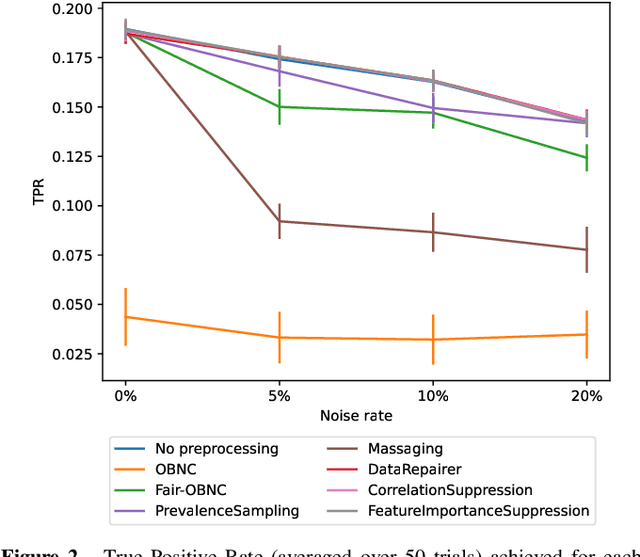
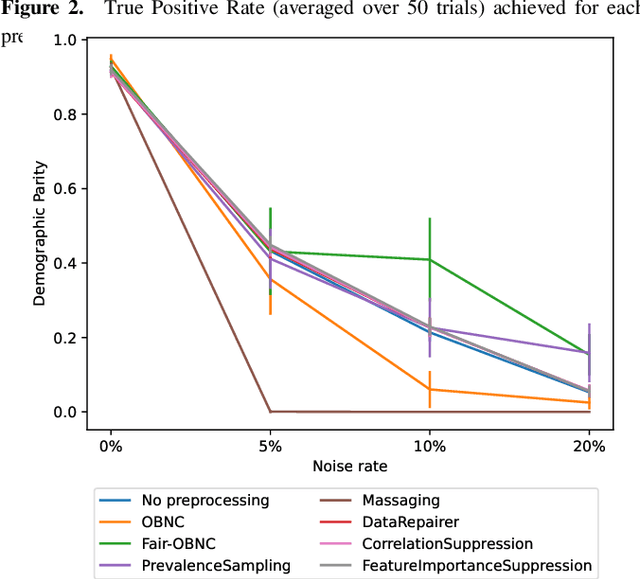
Data used by automated decision-making systems, such as Machine Learning models, often reflects discriminatory behavior that occurred in the past. These biases in the training data are sometimes related to label noise, such as in COMPAS, where more African-American offenders are wrongly labeled as having a higher risk of recidivism when compared to their White counterparts. Models trained on such biased data may perpetuate or even aggravate the biases with respect to sensitive information, such as gender, race, or age. However, while multiple label noise correction approaches are available in the literature, these focus on model performance exclusively. In this work, we propose Fair-OBNC, a label noise correction method with fairness considerations, to produce training datasets with measurable demographic parity. The presented method adapts Ordering-Based Noise Correction, with an adjusted criterion of ordering, based both on the margin of error of an ensemble, and the potential increase in the observed demographic parity of the dataset. We evaluate Fair-OBNC against other different pre-processing techniques, under different scenarios of controlled label noise. Our results show that the proposed method is the overall better alternative within the pool of label correction methods, being capable of attaining better reconstructions of the original labels. Models trained in the corrected data have an increase, on average, of 150% in demographic parity, when compared to models trained in data with noisy labels, across the considered levels of label noise.
Aequitas Flow: Streamlining Fair ML Experimentation
May 09, 2024Aequitas Flow is an open-source framework for end-to-end Fair Machine Learning (ML) experimentation in Python. This package fills the existing integration gaps in other Fair ML packages of complete and accessible experimentation. It provides a pipeline for fairness-aware model training, hyperparameter optimization, and evaluation, enabling rapid and simple experiments and result analysis. Aimed at ML practitioners and researchers, the framework offers implementations of methods, datasets, metrics, and standard interfaces for these components to improve extensibility. By facilitating the development of fair ML practices, Aequitas Flow seeks to enhance the adoption of these concepts in AI technologies.
Cost-Sensitive Learning to Defer to Multiple Experts with Workload Constraints
Mar 21, 2024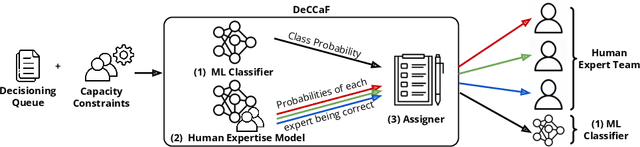
Learning to defer (L2D) aims to improve human-AI collaboration systems by learning how to defer decisions to humans when they are more likely to be correct than an ML classifier. Existing research in L2D overlooks key aspects of real-world systems that impede its practical adoption, namely: i) neglecting cost-sensitive scenarios, where type 1 and type 2 errors have different costs; ii) requiring concurrent human predictions for every instance of the training dataset and iii) not dealing with human work capacity constraints. To address these issues, we propose the deferral under cost and capacity constraints framework (DeCCaF). DeCCaF is a novel L2D approach, employing supervised learning to model the probability of human error under less restrictive data requirements (only one expert prediction per instance) and using constraint programming to globally minimize the error cost subject to workload limitations. We test DeCCaF in a series of cost-sensitive fraud detection scenarios with different teams of 9 synthetic fraud analysts, with individual work capacity constraints. The results demonstrate that our approach performs significantly better than the baselines in a wide array of scenarios, achieving an average 8.4% reduction in the misclassification cost.
FiFAR: A Fraud Detection Dataset for Learning to Defer
Dec 20, 2023Public dataset limitations have significantly hindered the development and benchmarking of learning to defer (L2D) algorithms, which aim to optimally combine human and AI capabilities in hybrid decision-making systems. In such systems, human availability and domain-specific concerns introduce difficulties, while obtaining human predictions for training and evaluation is costly. Financial fraud detection is a high-stakes setting where algorithms and human experts often work in tandem; however, there are no publicly available datasets for L2D concerning this important application of human-AI teaming. To fill this gap in L2D research, we introduce the Financial Fraud Alert Review Dataset (FiFAR), a synthetic bank account fraud detection dataset, containing the predictions of a team of 50 highly complex and varied synthetic fraud analysts, with varied bias and feature dependence. We also provide a realistic definition of human work capacity constraints, an aspect of L2D systems that is often overlooked, allowing for extensive testing of assignment systems under real-world conditions. We use our dataset to develop a capacity-aware L2D method and rejection learning approach under realistic data availability conditions, and benchmark these baselines under an array of 300 distinct testing scenarios. We believe that this dataset will serve as a pivotal instrument in facilitating a systematic, rigorous, reproducible, and transparent evaluation and comparison of L2D methods, thereby fostering the development of more synergistic human-AI collaboration in decision-making systems. The public dataset and detailed synthetic expert information are available at: https://github.com/feedzai/fifar-dataset
A Case Study on Designing Evaluations of ML Explanations with Simulated User Studies
Feb 15, 2023When conducting user studies to ascertain the usefulness of model explanations in aiding human decision-making, it is important to use real-world use cases, data, and users. However, this process can be resource-intensive, allowing only a limited number of explanation methods to be evaluated. Simulated user evaluations (SimEvals), which use machine learning models as a proxy for human users, have been proposed as an intermediate step to select promising explanation methods. In this work, we conduct the first SimEvals on a real-world use case to evaluate whether explanations can better support ML-assisted decision-making in e-commerce fraud detection. We study whether SimEvals can corroborate findings from a user study conducted in this fraud detection context. In particular, we find that SimEvals suggest that all considered explainers are equally performant, and none beat a baseline without explanations -- this matches the conclusions of the original user study. Such correspondences between our results and the original user study provide initial evidence in favor of using SimEvals before running user studies. We also explore the use of SimEvals as a cheap proxy to explore an alternative user study set-up. We hope that this work motivates further study of when and how SimEvals should be used to aid in the design of real-world evaluations.
Turning the Tables: Biased, Imbalanced, Dynamic Tabular Datasets for ML Evaluation
Nov 28, 2022Evaluating new techniques on realistic datasets plays a crucial role in the development of ML research and its broader adoption by practitioners. In recent years, there has been a significant increase of publicly available unstructured data resources for computer vision and NLP tasks. However, tabular data -- which is prevalent in many high-stakes domains -- has been lagging behind. To bridge this gap, we present Bank Account Fraud (BAF), the first publicly available privacy-preserving, large-scale, realistic suite of tabular datasets. The suite was generated by applying state-of-the-art tabular data generation techniques on an anonymized,real-world bank account opening fraud detection dataset. This setting carries a set of challenges that are commonplace in real-world applications, including temporal dynamics and significant class imbalance. Additionally, to allow practitioners to stress test both performance and fairness of ML methods, each dataset variant of BAF contains specific types of data bias. With this resource, we aim to provide the research community with a more realistic, complete, and robust test bed to evaluate novel and existing methods.
On the Importance of Application-Grounded Experimental Design for Evaluating Explainable ML Methods
Jun 30, 2022

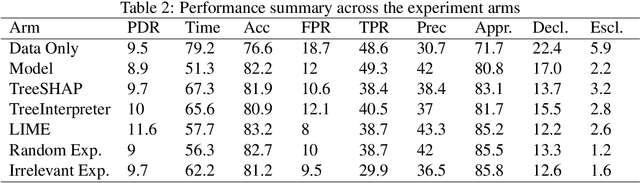
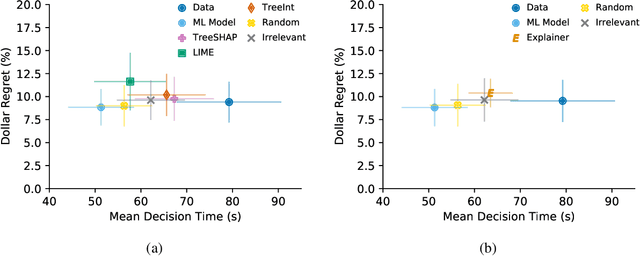
Machine Learning (ML) models now inform a wide range of human decisions, but using ``black box'' models carries risks such as relying on spurious correlations or errant data. To address this, researchers have proposed methods for supplementing models with explanations of their predictions. However, robust evaluations of these methods' usefulness in real-world contexts have remained elusive, with experiments tending to rely on simplified settings or proxy tasks. We present an experimental study extending a prior explainable ML evaluation experiment and bringing the setup closer to the deployment setting by relaxing its simplifying assumptions. Our empirical study draws dramatically different conclusions than the prior work, highlighting how seemingly trivial experimental design choices can yield misleading results. Beyond the present experiment, we believe this work holds lessons about the necessity of situating the evaluation of any ML method and choosing appropriate tasks, data, users, and metrics to match the intended deployment contexts.
How can I choose an explainer? An Application-grounded Evaluation of Post-hoc Explanations
Jan 22, 2021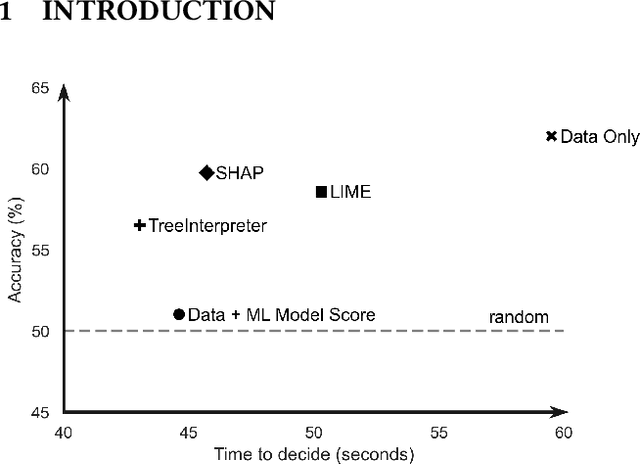
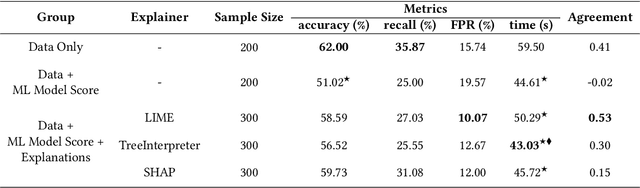
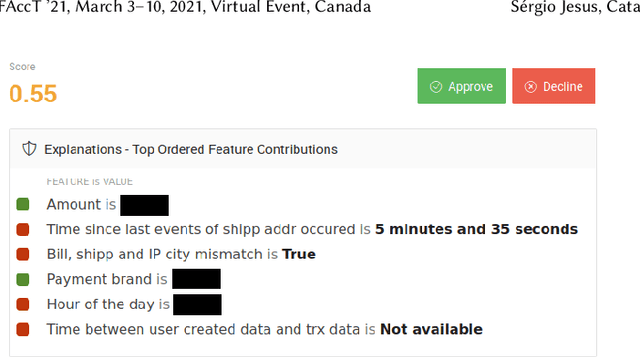
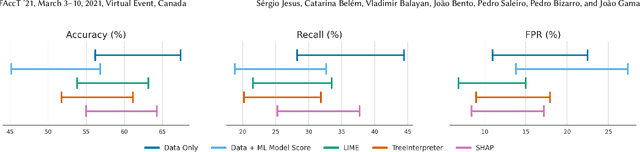
There have been several research works proposing new Explainable AI (XAI) methods designed to generate model explanations having specific properties, or desiderata, such as fidelity, robustness, or human-interpretability. However, explanations are seldom evaluated based on their true practical impact on decision-making tasks. Without that assessment, explanations might be chosen that, in fact, hurt the overall performance of the combined system of ML model + end-users. This study aims to bridge this gap by proposing XAI Test, an application-grounded evaluation methodology tailored to isolate the impact of providing the end-user with different levels of information. We conducted an experiment following XAI Test to evaluate three popular post-hoc explanation methods -- LIME, SHAP, and TreeInterpreter -- on a real-world fraud detection task, with real data, a deployed ML model, and fraud analysts. During the experiment, we gradually increased the information provided to the fraud analysts in three stages: Data Only, i.e., just transaction data without access to model score nor explanations, Data + ML Model Score, and Data + ML Model Score + Explanations. Using strong statistical analysis, we show that, in general, these popular explainers have a worse impact than desired. Some of the conclusion highlights include: i) showing Data Only results in the highest decision accuracy and the slowest decision time among all variants tested, ii) all the explainers improve accuracy over the Data + ML Model Score variant but still result in lower accuracy when compared with Data Only; iii) LIME was the least preferred by users, probably due to its substantially lower variability of explanations from case to case.