 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Inference from State Updates in Low-Latency Feature Engines via Probabilistic Thinning
Jun 15, 2026Streaming data systems increasingly underpin Machine Learning workflows that maintain large numbers of continuously updated aggregations. In production settings, each incoming event typically triggers read-modify-write operations to persistent storage, making high-frequency state updates a dominant source of latency, contention, and operational cost. In this work, we decouple inference from state persistence in streaming Machine Learning pipelines via probabilistic thinning: every event is scored, but durable state updates are selectively triggered by informative events. Unlike approaches that shed input or state, we show that persistence-path control is achievable without a high-frequency in-memory control plane or cross-worker coordination, relying exclusively on approximate statistics retrieved from disk-backed key-value stores. We model the resulting stochastic processes, derive bounds on filtering rates, and prove that common time-based aggregations remain unbiased under variance-aware formulations, preventing systemic error accumulation. We evaluate the approach in a controlled setting that isolates per-event costs, demonstrating substantial reductions in storage Input/Output and serialization overhead. Across experiments, up to 90% of events are excluded from the persistence path while preserving and in some cases improving downstream utility.
Rethinking XAI Evaluation: A Human-Centered Audit of Shapley Benchmarks in High-Stakes Settings
Apr 24, 2026Shapley values are a cornerstone of explainable AI, yet their proliferation into competing formulations has created a fragmented landscape with little consensus on practical deployment. While theoretical differences are well-documented, evaluation remains reliant on quantitative proxies whose alignment with human utility is unverified. In this work, we use a unified amortized framework to isolate semantic differences between eight Shapley variants under the low-latency constraints of operational risk workflows. We conduct a large-scale empirical evaluation across four risk datasets and a realistic fraud-detection environment involving professional analysts and 3,735 case reviews. Our results reveal a fundamental misalignment: standard quantitative metrics, such as sparsity and faithfulness, are decoupled from human-perceived clarity and decision utility. Furthermore, while no formulation improved objective analyst performance, explanations consistently increased decision confidence, signaling a critical risk of automation bias in high-stakes settings. These findings suggest that current evaluation proxies are insufficient for predicting downstream human impact, and we provide evidence-based guidance for selecting formulations and metrics in operational decision systems.
MUSE: Multi-Tenant Model Serving With Seamless Model Updates
Feb 12, 2026In binary classification systems, decision thresholds translate model scores into actions. Choosing suitable thresholds relies on the specific distribution of the underlying model scores but also on the specific business decisions of each client using that model. However, retraining models inevitably shifts score distributions, invalidating existing thresholds. In multi-tenant Score-as-a-Service environments, where decision boundaries reside in client-managed infrastructure, this creates a severe bottleneck: recalibration requires coordinating threshold updates across hundreds of clients, consuming excessive human hours and leading to model stagnation. We introduce MUSE, a model serving framework that enables seamless model updates by decoupling model scores from client decision boundaries. Designed for multi-tenancy, MUSE optimizes infrastructure re-use by sharing models via dynamic intent-based routing, combined with a two-level score transformation that maps model outputs to a stable, reference distribution. Deployed at scale by Feedzai, MUSE processes over a thousand events per second, and over 55 billion events in the last 12 months, across several dozens of tenants, while maintaining high-availability and low-latency guarantees. By reducing model lead time from weeks to minutes, MUSE promotes model resilience against shifting attacks, saving millions of dollars in fraud losses and operational costs.
Mind the truncation gap: challenges of learning on dynamic graphs with recurrent architectures
Dec 30, 2024



Systems characterized by evolving interactions, prevalent in social, financial, and biological domains, are effectively modeled as continuous-time dynamic graphs (CTDGs). To manage the scale and complexity of these graph datasets, machine learning (ML) approaches have become essential. However, CTDGs pose challenges for ML because traditional static graph methods do not naturally account for event timings. Newer approaches, such as graph recurrent neural networks (GRNNs), are inherently time-aware and offer advantages over static methods for CTDGs. However, GRNNs face another issue: the short truncation of backpropagation-through-time (BPTT), whose impact has not been properly examined until now. In this work, we demonstrate that this truncation can limit the learning of dependencies beyond a single hop, resulting in reduced performance. Through experiments on a novel synthetic task and real-world datasets, we reveal a performance gap between full backpropagation-through-time (F-BPTT) and the truncated backpropagation-through-time (T-BPTT) commonly used to train GRNN models. We term this gap the "truncation gap" and argue that understanding and addressing it is essential as the importance of CTDGs grows, discussing potential future directions for research in this area.
Fair-OBNC: Correcting Label Noise for Fairer Datasets
Oct 08, 2024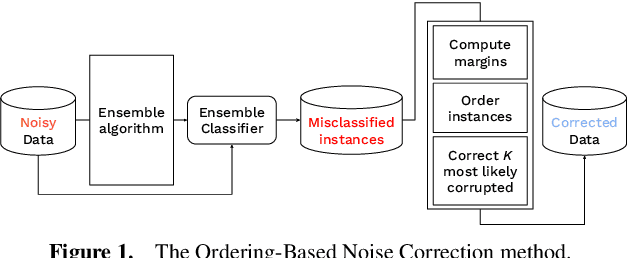
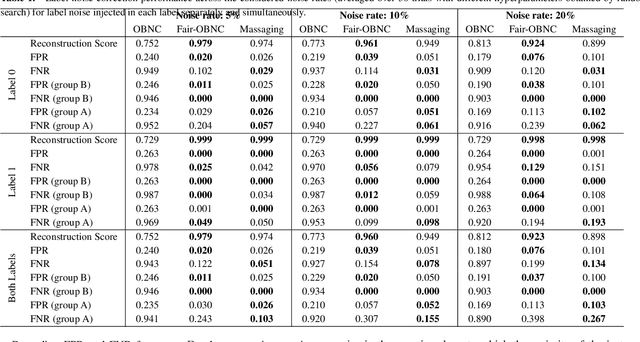
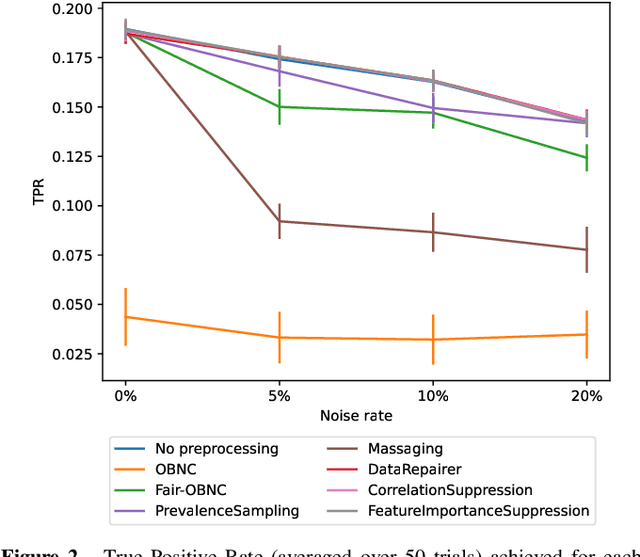
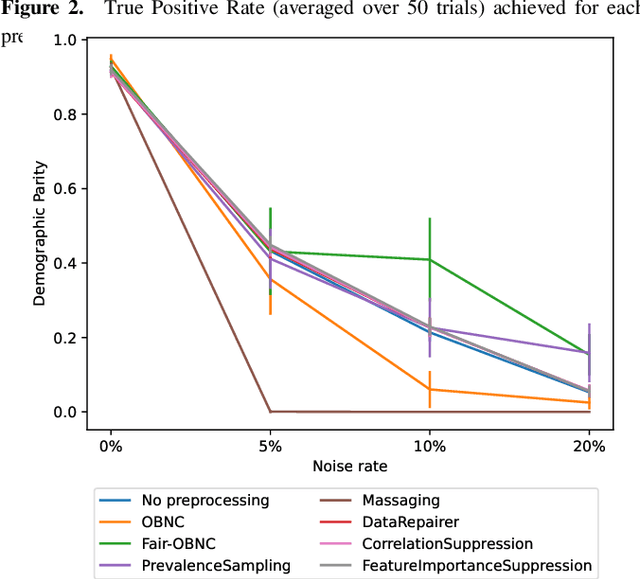
Data used by automated decision-making systems, such as Machine Learning models, often reflects discriminatory behavior that occurred in the past. These biases in the training data are sometimes related to label noise, such as in COMPAS, where more African-American offenders are wrongly labeled as having a higher risk of recidivism when compared to their White counterparts. Models trained on such biased data may perpetuate or even aggravate the biases with respect to sensitive information, such as gender, race, or age. However, while multiple label noise correction approaches are available in the literature, these focus on model performance exclusively. In this work, we propose Fair-OBNC, a label noise correction method with fairness considerations, to produce training datasets with measurable demographic parity. The presented method adapts Ordering-Based Noise Correction, with an adjusted criterion of ordering, based both on the margin of error of an ensemble, and the potential increase in the observed demographic parity of the dataset. We evaluate Fair-OBNC against other different pre-processing techniques, under different scenarios of controlled label noise. Our results show that the proposed method is the overall better alternative within the pool of label correction methods, being capable of attaining better reconstructions of the original labels. Models trained in the corrected data have an increase, on average, of 150% in demographic parity, when compared to models trained in data with noisy labels, across the considered levels of label noise.
Deep-Graph-Sprints: Accelerated Representation Learning in Continuous-Time Dynamic Graphs
Jul 10, 2024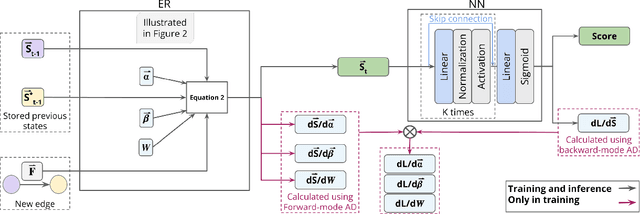



Continuous-time dynamic graphs (CTDGs) are essential for modeling interconnected, evolving systems. Traditional methods for extracting knowledge from these graphs often depend on feature engineering or deep learning. Feature engineering is limited by the manual and time-intensive nature of crafting features, while deep learning approaches suffer from high inference latency, making them impractical for real-time applications. This paper introduces Deep-Graph-Sprints (DGS), a novel deep learning architecture designed for efficient representation learning on CTDGs with low-latency inference requirements. We benchmark DGS against state-of-the-art feature engineering and graph neural network methods using five diverse datasets. The results indicate that DGS achieves competitive performance while improving inference speed up to 12x compared to other deep learning approaches on our tested benchmarks. Our method effectively bridges the gap between deep representation learning and low-latency application requirements for CTDGs.
Adversarial training for tabular data with attack propagation
Jul 28, 2023Adversarial attacks are a major concern in security-centered applications, where malicious actors continuously try to mislead Machine Learning (ML) models into wrongly classifying fraudulent activity as legitimate, whereas system maintainers try to stop them. Adversarially training ML models that are robust against such attacks can prevent business losses and reduce the work load of system maintainers. In such applications data is often tabular and the space available for attackers to manipulate undergoes complex feature engineering transformations, to provide useful signals for model training, to a space attackers cannot access. Thus, we propose a new form of adversarial training where attacks are propagated between the two spaces in the training loop. We then test this method empirically on a real world dataset in the domain of credit card fraud detection. We show that our method can prevent about 30% performance drops under moderate attacks and is essential under very aggressive attacks, with a trade-off loss in performance under no attacks smaller than 7%.
From random-walks to graph-sprints: a low-latency node embedding framework on continuous-time dynamic graphs
Jul 18, 2023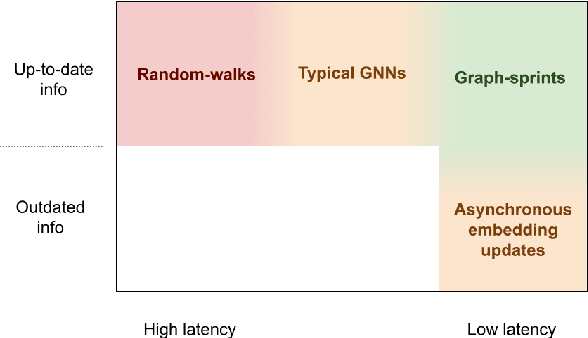

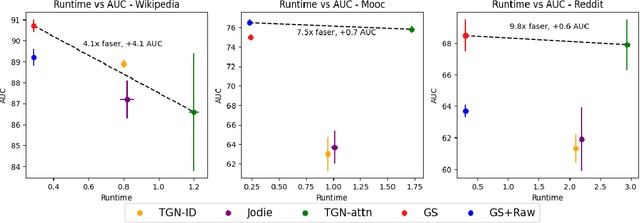

Many real-world datasets have an underlying dynamic graph structure, where entities and their interactions evolve over time. Machine learning models should consider these dynamics in order to harness their full potential in downstream tasks. Previous approaches for graph representation learning have focused on either sampling k-hop neighborhoods, akin to breadth-first search, or random walks, akin to depth-first search. However, these methods are computationally expensive and unsuitable for real-time, low-latency inference on dynamic graphs. To overcome these limitations, we propose graph-sprints a general purpose feature extraction framework for continuous-time-dynamic-graphs (CTDGs) that has low latency and is competitive with state-of-the-art, higher latency models. To achieve this, a streaming, low latency approximation to the random-walk based features is proposed. In our framework, time-aware node embeddings summarizing multi-hop information are computed using only single-hop operations on the incoming edges. We evaluate our proposed approach on three open-source datasets and two in-house datasets, and compare with three state-of-the-art algorithms (TGN-attn, TGN-ID, Jodie). We demonstrate that our graph-sprints features, combined with a machine learning classifier, achieve competitive performance (outperforming all baselines for the node classification tasks in five datasets). Simultaneously, graph-sprints significantly reduce inference latencies, achieving close to an order of magnitude speed-up in our experimental setting.
Building robust prediction models for defective sensor data using Artificial Neural Networks
Apr 16, 2018
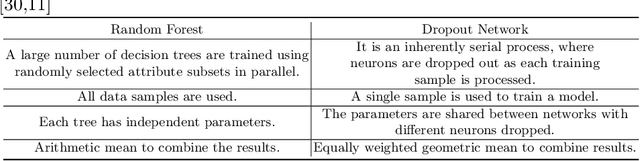
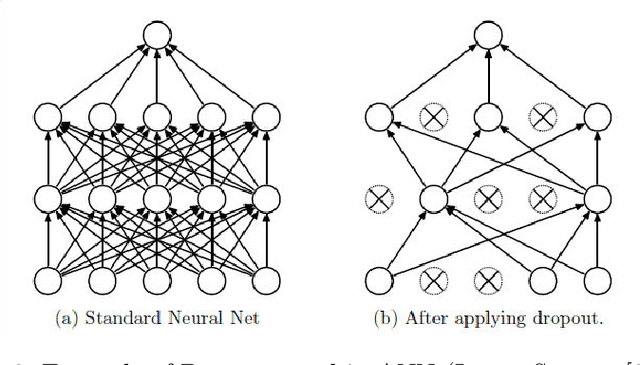
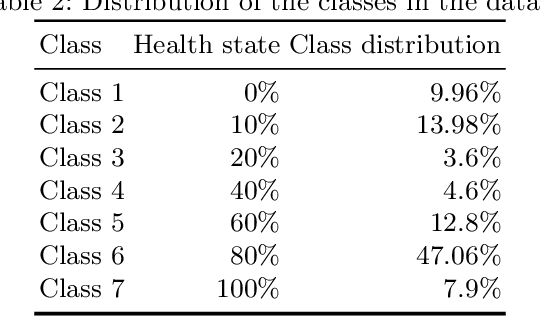
Predicting the health of components in complex dynamic systems such as an automobile poses numerous challenges. The primary aim of such predictive systems is to use the high-dimensional data acquired from different sensors and predict the state-of-health of a particular component, e.g., brake pad. The classical approach involves selecting a smaller set of relevant sensor signals using feature selection and using them to train a machine learning algorithm. However, this fails to address two prominent problems: (1) sensors are susceptible to failure when exposed to extreme conditions over a long periods of time; (2) sensors are electrical devices that can be affected by noise or electrical interference. Using the failed and noisy sensor signals as inputs largely reduce the prediction accuracy. To tackle this problem, it is advantageous to use the information from all sensor signals, so that the failure of one sensor can be compensated by another. In this work, we propose an Artificial Neural Network (ANN) based framework to exploit the information from a large number of signals. Secondly, our framework introduces a data augmentation approach to perform accurate predictions in spite of noisy signals. The plausibility of our framework is validated on real life industrial application from Robert Bosch GmbH.