 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Semantic Segmentation Grounded in Visual Concepts
Mar 25, 2022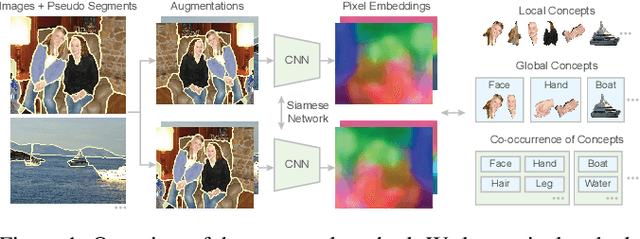
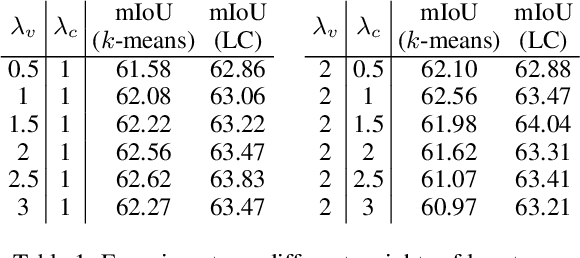
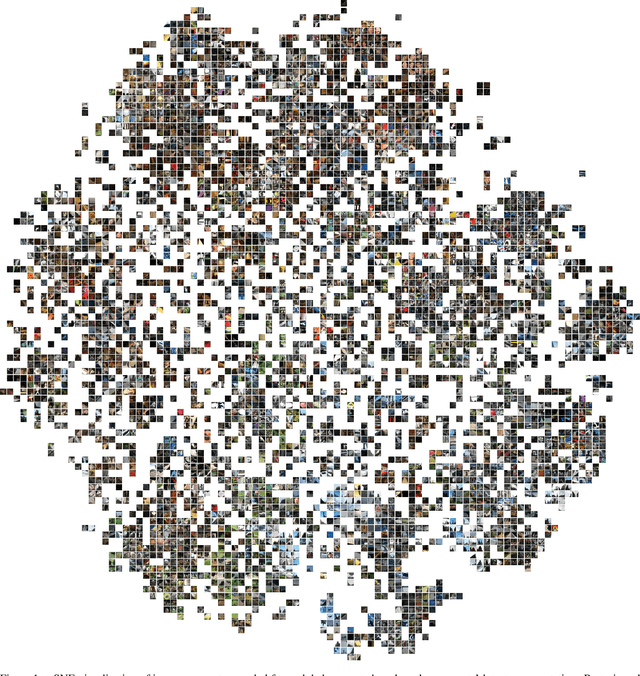
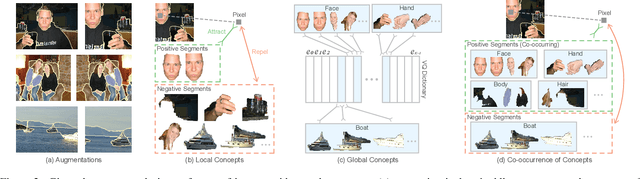
Unsupervised semantic segmentation requires assigning a label to every pixel without any human annotations. Despite recent advances in self-supervised representation learning for individual images, unsupervised semantic segmentation with pixel-level representations is still a challenging task and remains underexplored. In this work, we propose a self-supervised pixel representation learning method for semantic segmentation by using visual concepts (i.e., groups of pixels with semantic meanings, such as parts, objects, and scenes) extracted from images. To guide self-supervised learning, we leverage three types of relationships between pixels and concepts, including the relationships between pixels and local concepts, local and global concepts, as well as the co-occurrence of concepts. We evaluate the learned pixel embeddings and visual concepts on three datasets, including PASCAL VOC 2012, COCO 2017, and DAVIS 2017. Our results show that the proposed method gains consistent and substantial improvements over recent unsupervised semantic segmentation approaches, and also demonstrate that visual concepts can reveal insights into image datasets.
Novelty-based Generalization Evaluation for Traffic Light Detection
Jan 03, 2022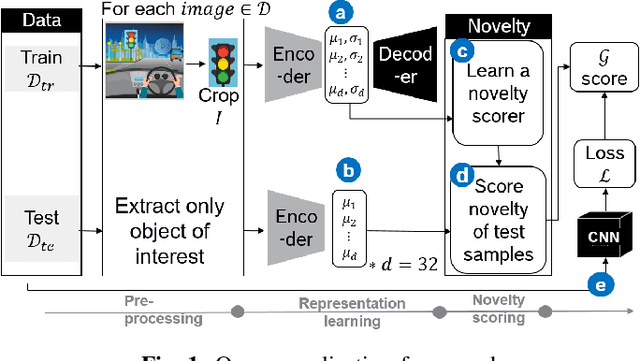
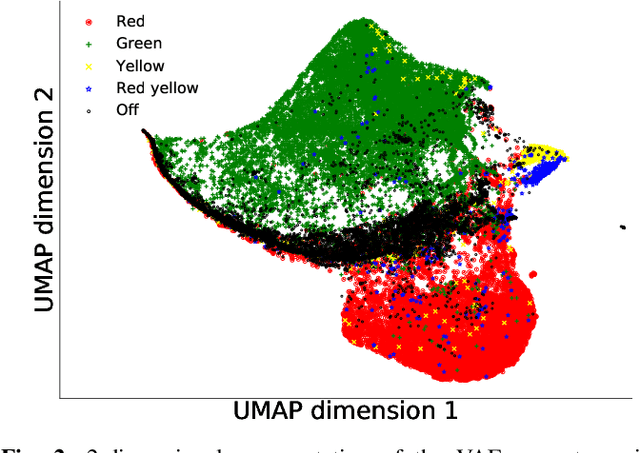
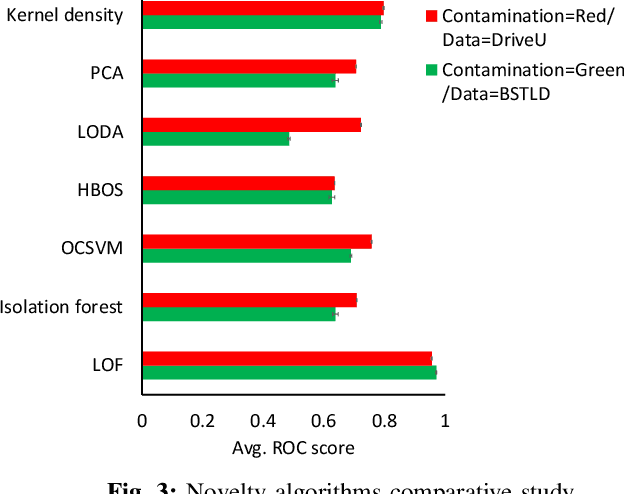
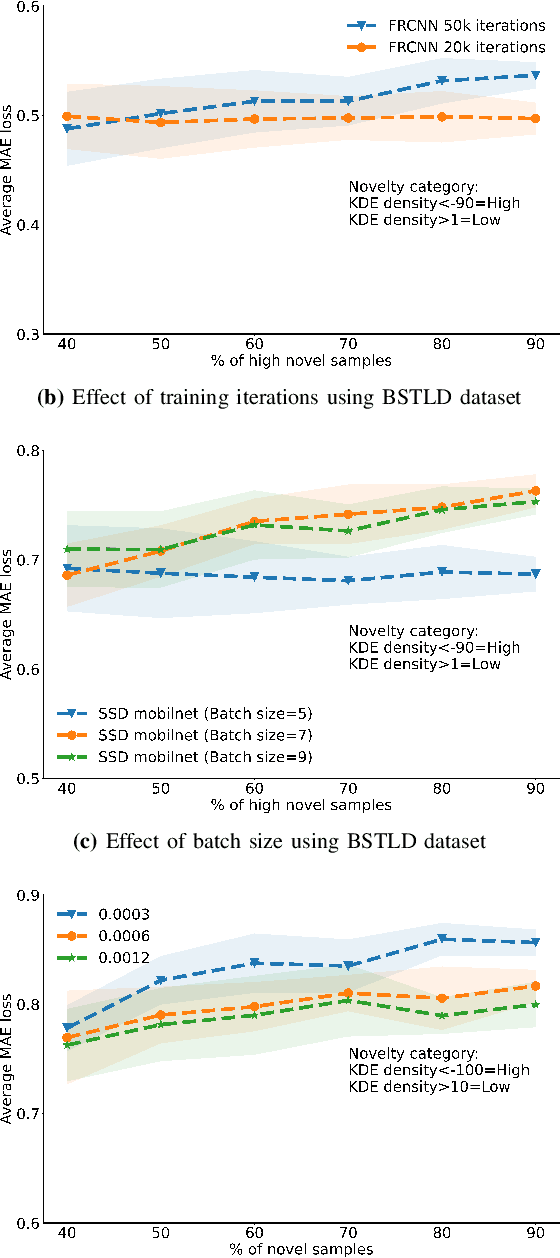
The advent of Convolutional Neural Networks (CNNs) has led to their application in several domains. One noteworthy application is the perception system for autonomous driving that relies on the predictions from CNNs. Practitioners evaluate the generalization ability of such CNNs by calculating various metrics on an independent test dataset. A test dataset is often chosen based on only one precondition, i.e., its elements are not a part of the training data. Such a dataset may contain objects that are both similar and novel w.r.t. the training dataset. Nevertheless, existing works do not reckon the novelty of the test samples and treat them all equally for evaluating generalization. Such novelty-based evaluations are of significance to validate the fitness of a CNN in autonomous driving applications. Hence, we propose a CNN generalization scoring framework that considers novelty of objects in the test dataset. We begin with the representation learning technique to reduce the image data into a low-dimensional space. It is on this space we estimate the novelty of the test samples. Finally, we calculate the generalization score as a combination of the test data prediction performance and novelty. We perform an experimental study of the same for our traffic light detection application. In addition, we systematically visualize the results for an interpretable notion of novelty.
VATLD: A Visual Analytics System to Assess, Understand and Improve Traffic Light Detection
Sep 27, 2020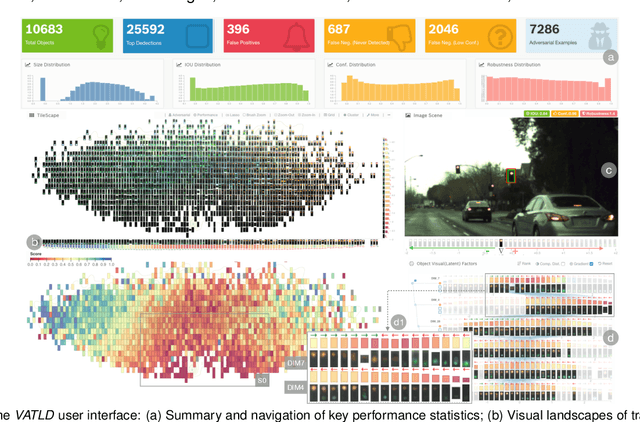
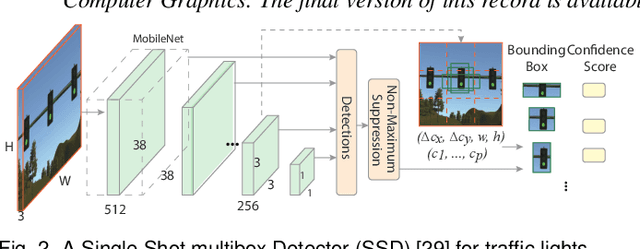

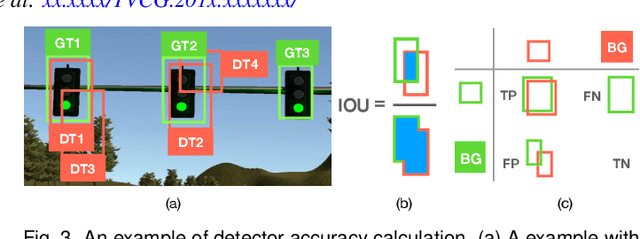
Traffic light detection is crucial for environment perception and decision-making in autonomous driving. State-of-the-art detectors are built upon deep Convolutional Neural Networks (CNNs) and have exhibited promising performance. However, one looming concern with CNN based detectors is how to thoroughly evaluate the performance of accuracy and robustness before they can be deployed to autonomous vehicles. In this work, we propose a visual analytics system, VATLD, equipped with a disentangled representation learning and semantic adversarial learning, to assess, understand, and improve the accuracy and robustness of traffic light detectors in autonomous driving applications. The disentangled representation learning extracts data semantics to augment human cognition with human-friendly visual summarization, and the semantic adversarial learning efficiently exposes interpretable robustness risks and enables minimal human interaction for actionable insights. We also demonstrate the effectiveness of various performance improvement strategies derived from actionable insights with our visual analytics system, VATLD, and illustrate some practical implications for safety-critical applications in autonomous driving.
Building robust prediction models for defective sensor data using Artificial Neural Networks
Apr 16, 2018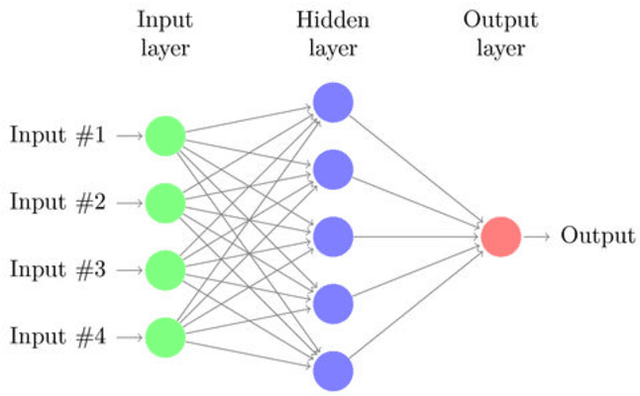
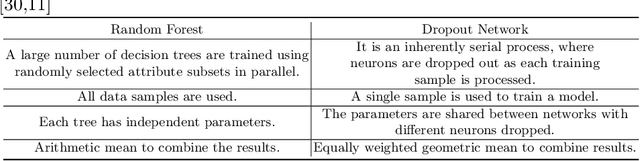
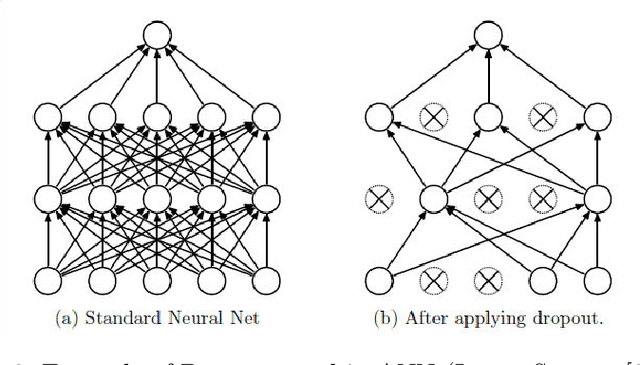
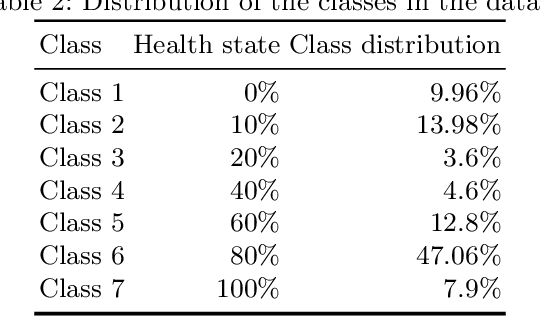
Predicting the health of components in complex dynamic systems such as an automobile poses numerous challenges. The primary aim of such predictive systems is to use the high-dimensional data acquired from different sensors and predict the state-of-health of a particular component, e.g., brake pad. The classical approach involves selecting a smaller set of relevant sensor signals using feature selection and using them to train a machine learning algorithm. However, this fails to address two prominent problems: (1) sensors are susceptible to failure when exposed to extreme conditions over a long periods of time; (2) sensors are electrical devices that can be affected by noise or electrical interference. Using the failed and noisy sensor signals as inputs largely reduce the prediction accuracy. To tackle this problem, it is advantageous to use the information from all sensor signals, so that the failure of one sensor can be compensated by another. In this work, we propose an Artificial Neural Network (ANN) based framework to exploit the information from a large number of signals. Secondly, our framework introduces a data augmentation approach to perform accurate predictions in spite of noisy signals. The plausibility of our framework is validated on real life industrial application from Robert Bosch GmbH.