 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-R1: Incentivizing Reasoning Capability in Vision Foundation Models
May 29, 2025



The recent explosive interest in the reasoning capabilities of large language models, such as DeepSeek-R1, has demonstrated remarkable success through reinforcement learning-based fine-tuning frameworks, exemplified by methods like Group Relative Policy Optimization (GRPO). However, such reasoning abilities remain underexplored and notably absent in vision foundation models, including representation models like the DINO series. In this work, we propose \textbf{DINO-R1}, the first such attempt to incentivize visual in-context reasoning capabilities of vision foundation models using reinforcement learning. Specifically, DINO-R1 introduces \textbf{Group Relative Query Optimization (GRQO)}, a novel reinforcement-style training strategy explicitly designed for query-based representation models, which computes query-level rewards based on group-normalized alignment quality. We also apply KL-regularization to stabilize the objectness distribution to reduce the training instability. This joint optimization enables dense and expressive supervision across queries while mitigating overfitting and distributional drift. Building upon Grounding-DINO, we train a series of DINO-R1 family models that integrate a visual prompt encoder and a visual-guided query selection mechanism. Extensive experiments on COCO, LVIS, and ODinW demonstrate that DINO-R1 significantly outperforms supervised fine-tuning baselines, achieving strong generalization in both open-vocabulary and closed-set visual prompting scenarios.
InterChat: Enhancing Generative Visual Analytics using Multimodal Interactions
Mar 06, 2025



The rise of Large Language Models (LLMs) and generative visual analytics systems has transformed data-driven insights, yet significant challenges persist in accurately interpreting users' analytical and interaction intents. While language inputs offer flexibility, they often lack precision, making the expression of complex intents inefficient, error-prone, and time-intensive. To address these limitations, we investigate the design space of multimodal interactions for generative visual analytics through a literature review and pilot brainstorming sessions. Building on these insights, we introduce a highly extensible workflow that integrates multiple LLM agents for intent inference and visualization generation. We develop InterChat, a generative visual analytics system that combines direct manipulation of visual elements with natural language inputs. This integration enables precise intent communication and supports progressive, visually driven exploratory data analyses. By employing effective prompt engineering, and contextual interaction linking, alongside intuitive visualization and interaction designs, InterChat bridges the gap between user interactions and LLM-driven visualizations, enhancing both interpretability and usability. Extensive evaluations, including two usage scenarios, a user study, and expert feedback, demonstrate the effectiveness of InterChat. Results show significant improvements in the accuracy and efficiency of handling complex visual analytics tasks, highlighting the potential of multimodal interactions to redefine user engagement and analytical depth in generative visual analytics.
InFiConD: Interactive No-code Fine-tuning with Concept-based Knowledge Distillation
Jun 25, 2024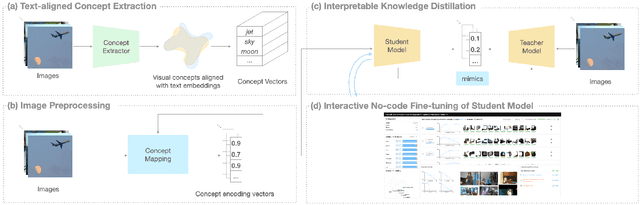
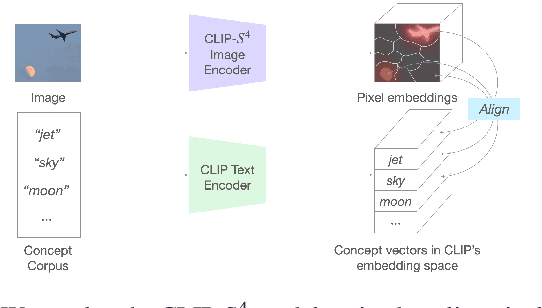
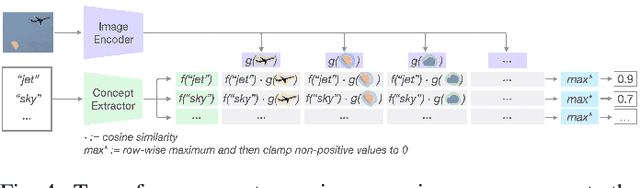
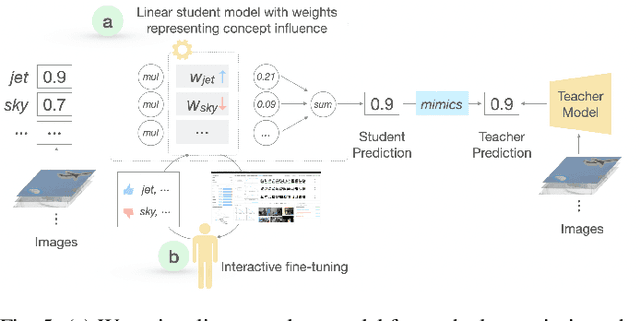
The emergence of large-scale pre-trained models has heightened their application in various downstream tasks, yet deployment is a challenge in environments with limited computational resources. Knowledge distillation has emerged as a solution in such scenarios, whereby knowledge from large teacher models is transferred into smaller student' models, but this is a non-trivial process that traditionally requires technical expertise in AI/ML. To address these challenges, this paper presents InFiConD, a novel framework that leverages visual concepts to implement the knowledge distillation process and enable subsequent no-code fine-tuning of student models. We develop a novel knowledge distillation pipeline based on extracting text-aligned visual concepts from a concept corpus using multimodal models, and construct highly interpretable linear student models based on visual concepts that mimic a teacher model in a response-based manner. InFiConD's interface allows users to interactively fine-tune the student model by manipulating concept influences directly in the user interface. We validate InFiConD via a robust usage scenario and user study. Our findings indicate that InFiConD's human-in-the-loop and visualization-driven approach enables users to effectively create and analyze student models, understand how knowledge is transferred, and efficiently perform fine-tuning operations. We discuss how this work highlights the potential of interactive and visual methods in making knowledge distillation and subsequent no-code fine-tuning more accessible and adaptable to a wider range of users with domain-specific demands.
USE: Universal Segment Embeddings for Open-Vocabulary Image Segmentation
Jun 07, 2024

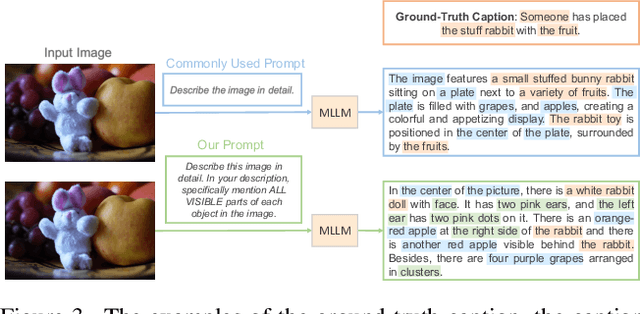
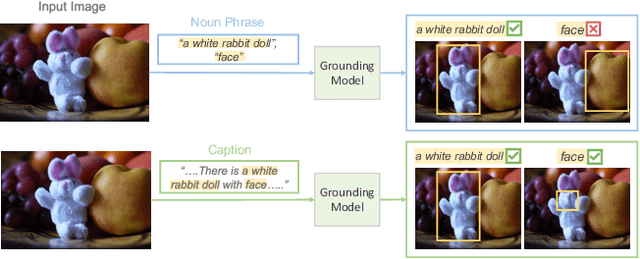
The open-vocabulary image segmentation task involves partitioning images into semantically meaningful segments and classifying them with flexible text-defined categories. The recent vision-based foundation models such as the Segment Anything Model (SAM) have shown superior performance in generating class-agnostic image segments. The main challenge in open-vocabulary image segmentation now lies in accurately classifying these segments into text-defined categories. In this paper, we introduce the Universal Segment Embedding (USE) framework to address this challenge. This framework is comprised of two key components: 1) a data pipeline designed to efficiently curate a large amount of segment-text pairs at various granularities, and 2) a universal segment embedding model that enables precise segment classification into a vast range of text-defined categories. The USE model can not only help open-vocabulary image segmentation but also facilitate other downstream tasks (e.g., querying and ranking). Through comprehensive experimental studies on semantic segmentation and part segmentation benchmarks, we demonstrate that the USE framework outperforms state-of-the-art open-vocabulary segmentation methods.
A streamlined Approach to Multimodal Few-Shot Class Incremental Learning for Fine-Grained Datasets
Mar 10, 2024



Few-shot Class-Incremental Learning (FSCIL) poses the challenge of retaining prior knowledge while learning from limited new data streams, all without overfitting. The rise of Vision-Language models (VLMs) has unlocked numerous applications, leveraging their existing knowledge to fine-tune on custom data. However, training the whole model is computationally prohibitive, and VLMs while being versatile in general domains still struggle with fine-grained datasets crucial for many applications. We tackle these challenges with two proposed simple modules. The first, Session-Specific Prompts (SSP), enhances the separability of image-text embeddings across sessions. The second, Hyperbolic distance, compresses representations of image-text pairs within the same class while expanding those from different classes, leading to better representations. Experimental results demonstrate an average 10-point increase compared to baselines while requiring at least 8 times fewer trainable parameters. This improvement is further underscored on our three newly introduced fine-grained datasets.
InterVLS: Interactive Model Understanding and Improvement with Vision-Language Surrogates
Nov 06, 2023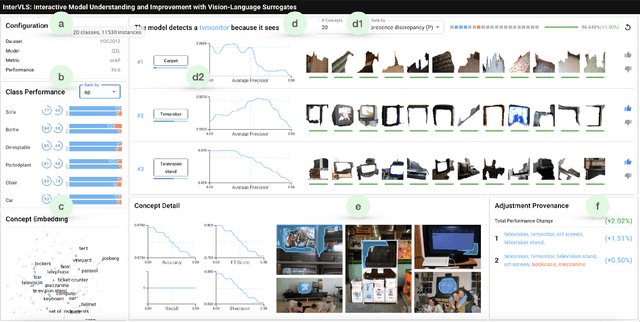
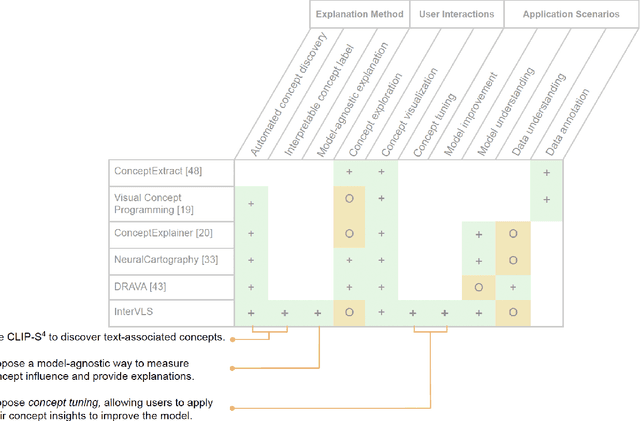
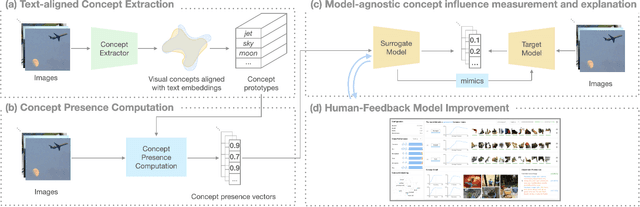
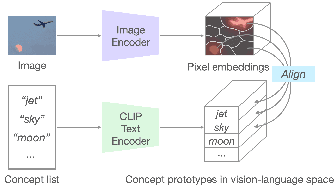
Deep learning models are widely used in critical applications, highlighting the need for pre-deployment model understanding and improvement. Visual concept-based methods, while increasingly used for this purpose, face challenges: (1) most concepts lack interpretability, (2) existing methods require model knowledge, often unavailable at run time. Additionally, (3) there lacks a no-code method for post-understanding model improvement. Addressing these, we present InterVLS. The system facilitates model understanding by discovering text-aligned concepts, measuring their influence with model-agnostic linear surrogates. Employing visual analytics, InterVLS offers concept-based explanations and performance insights. It enables users to adjust concept influences to update a model, facilitating no-code model improvement. We evaluate InterVLS in a user study, illustrating its functionality with two scenarios. Results indicates that InterVLS is effective to help users identify influential concepts to a model, gain insights and adjust concept influence to improve the model. We conclude with a discussion based on our study results.
GradOrth: A Simple yet Efficient Out-of-Distribution Detection with Orthogonal Projection of Gradients
Aug 01, 2023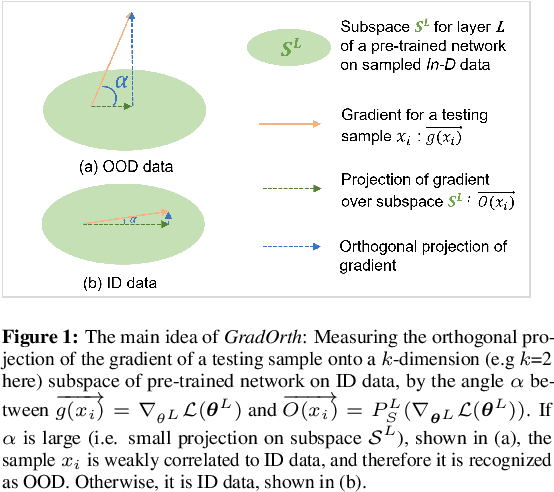
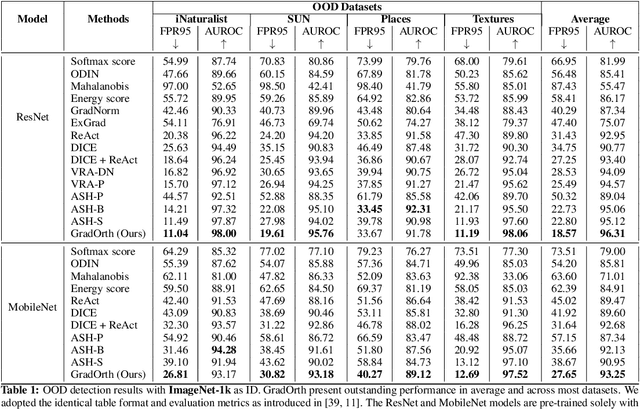
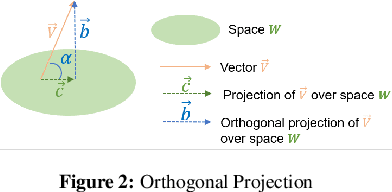

Detecting out-of-distribution (OOD) data is crucial for ensuring the safe deployment of machine learning models in real-world applications. However, existing OOD detection approaches primarily rely on the feature maps or the full gradient space information to derive OOD scores neglecting the role of most important parameters of the pre-trained network over in-distribution (ID) data. In this study, we propose a novel approach called GradOrth to facilitate OOD detection based on one intriguing observation that the important features to identify OOD data lie in the lower-rank subspace of in-distribution (ID) data. In particular, we identify OOD data by computing the norm of gradient projection on the subspaces considered important for the in-distribution data. A large orthogonal projection value (i.e. a small projection value) indicates the sample as OOD as it captures a weak correlation of the ID data. This simple yet effective method exhibits outstanding performance, showcasing a notable reduction in the average false positive rate at a 95% true positive rate (FPR95) of up to 8% when compared to the current state-of-the-art methods.
UP-DP: Unsupervised Prompt Learning for Data Pre-Selection with Vision-Language Models
Jul 20, 2023In this study, we investigate the task of data pre-selection, which aims to select instances for labeling from an unlabeled dataset through a single pass, thereby optimizing performance for undefined downstream tasks with a limited annotation budget. Previous approaches to data pre-selection relied solely on visual features extracted from foundation models, such as CLIP and BLIP-2, but largely ignored the powerfulness of text features. In this work, we argue that, with proper design, the joint feature space of both vision and text can yield a better representation for data pre-selection. To this end, we introduce UP-DP, a simple yet effective unsupervised prompt learning approach that adapts vision-language models, like BLIP-2, for data pre-selection. Specifically, with the BLIP-2 parameters frozen, we train text prompts to extract the joint features with improved representation, ensuring a diverse cluster structure that covers the entire dataset. We extensively compare our method with the state-of-the-art using seven benchmark datasets in different settings, achieving up to a performance gain of 20%. Interestingly, the prompts learned from one dataset demonstrate significant generalizability and can be applied directly to enhance the feature extraction of BLIP-2 from other datasets. To the best of our knowledge, UP-DP is the first work to incorporate unsupervised prompt learning in a vision-language model for data pre-selection.
Hyp-OW: Exploiting Hierarchical Structure Learning with Hyperbolic Distance Enhances Open World Object Detection
Jun 25, 2023Open World Object Detection (OWOD) is a challenging and realistic task that extends beyond the scope of standard Object Detection task. It involves detecting both known and unknown objects while integrating learned knowledge for future tasks. However, the level of 'unknownness' varies significantly depending on the context. For example, a tree is typically considered part of the background in a self-driving scene, but it may be significant in a household context. We argue that this external or contextual information should already be embedded within the known classes. In other words, there should be a semantic or latent structure relationship between the known and unknown items to be discovered. Motivated by this observation, we propose Hyp-OW, a method that learns and models hierarchical representation of known items through a SuperClass Regularizer. Leveraging this learned representation allows us to effectively detect unknown objects using a Similarity Distance-based Relabeling module. Extensive experiments on benchmark datasets demonstrate the effectiveness of Hyp-OW achieving improvement in both known and unknown detection (up to 6 points). These findings are particularly pronounced in our newly designed benchmark, where a strong hierarchical structure exists between known and unknown objects.
Fault Identification of Rotating Machinery Based on Dynamic Feature Reconstruction Signal Graph
May 30, 2023



To improve the performance in identifying the faults under strong noise for rotating machinery, this paper presents a dynamic feature reconstruction signal graph method, which plays the key role of the proposed end-to-end fault diagnosis model. Specifically, the original mechanical signal is first decomposed by wavelet packet decomposition (WPD) to obtain multiple subbands including coefficient matrix. Then, with originally defined two feature extraction factors MDD and DDD, a dynamic feature selection method based on L2 energy norm (DFSL) is proposed, which can dynamically select the feature coefficient matrix of WPD based on the difference in the distribution of norm energy, enabling each sub-signal to take adaptive signal reconstruction. Next the coefficient matrices of the optimal feature sub-bands are reconstructed and reorganized to obtain the feature signal graphs. Finally, deep features are extracted from the feature signal graphs by 2D-Convolutional neural network (2D-CNN). Experimental results on a public data platform of a bearing and our laboratory platform of robot grinding show that this method is better than the existing methods under different noise intensities.