 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCVPT: Cross-Attention help Visual Prompt Tuning adapt visual task
Aug 27, 2024In recent years, the rapid expansion of model sizes has led to large-scale pre-trained models demonstrating remarkable capabilities. Consequently, there has been a trend towards increasing the scale of models. However, this trend introduces significant challenges, including substantial computational costs of training and transfer to downstream tasks. To address these issues, Parameter-Efficient Fine-Tuning (PEFT) methods have been introduced. These methods optimize large-scale pre-trained models for specific tasks by fine-tuning a select group of parameters. Among these PEFT methods, adapter-based and prompt-based methods are the primary techniques. Specifically, in the field of visual fine-tuning, adapters gain prominence over prompts because of the latter's relatively weaker performance and efficiency. Under the circumstances, we refine the widely-used Visual Prompt Tuning (VPT) method, proposing Cross Visual Prompt Tuning (CVPT). CVPT calculates cross-attention between the prompt tokens and the embedded tokens, which allows us to compute the semantic relationship between them and conduct the fine-tuning of models exactly to adapt visual tasks better. Furthermore, we introduce the weight-sharing mechanism to initialize the parameters of cross-attention, which avoids massive learnable parameters from cross-attention and enhances the representative capability of cross-attention. We conduct comprehensive testing across 25 datasets and the result indicates that CVPT significantly improves VPT's performance and efficiency in visual tasks. For example, on the VTAB-1K benchmark, CVPT outperforms VPT over 4% in average accuracy, rivaling the advanced adapter-based methods in performance and efficiency. Our experiments confirm that prompt-based methods can achieve exceptional results in visual fine-tuning.
Teaching with Uncertainty: Unleashing the Potential of Knowledge Distillation in Object Detection
Jun 11, 2024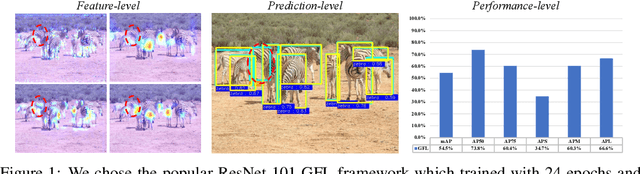
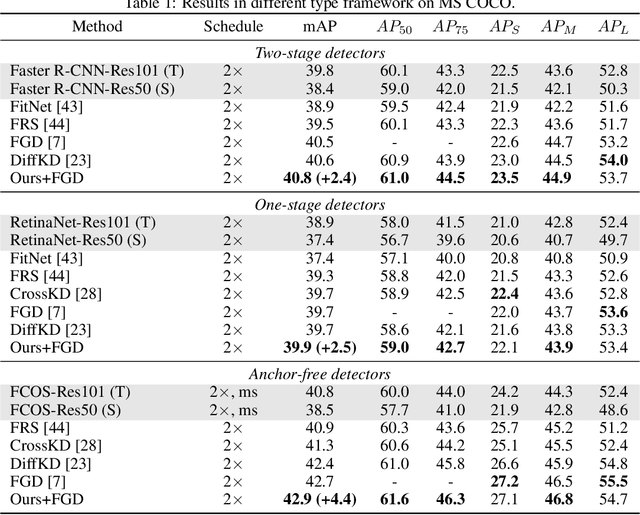
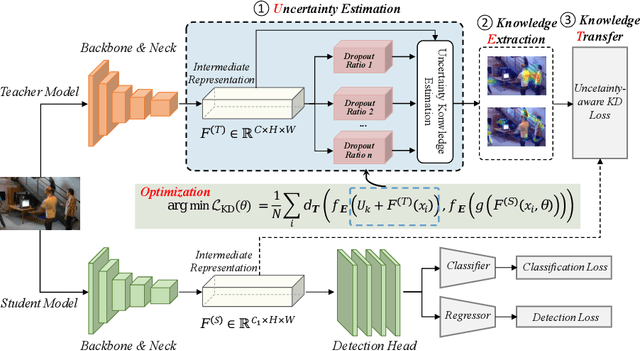
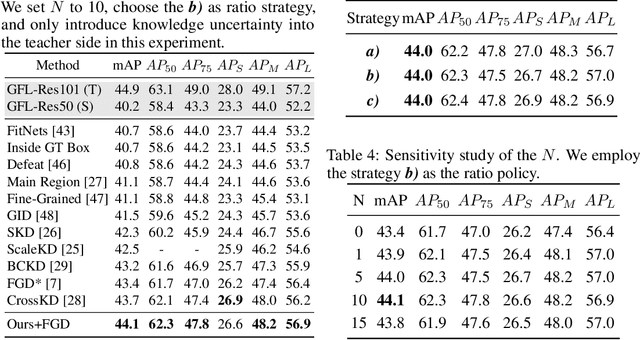
Knowledge distillation (KD) is a widely adopted and effective method for compressing models in object detection tasks. Particularly, feature-based distillation methods have shown remarkable performance. Existing approaches often ignore the uncertainty in the teacher model's knowledge, which stems from data noise and imperfect training. This limits the student model's ability to learn latent knowledge, as it may overly rely on the teacher's imperfect guidance. In this paper, we propose a novel feature-based distillation paradigm with knowledge uncertainty for object detection, termed "Uncertainty Estimation-Discriminative Knowledge Extraction-Knowledge Transfer (UET)", which can seamlessly integrate with existing distillation methods. By leveraging the Monte Carlo dropout technique, we introduce knowledge uncertainty into the training process of the student model, facilitating deeper exploration of latent knowledge. Our method performs effectively during the KD process without requiring intricate structures or extensive computational resources. Extensive experiments validate the effectiveness of our proposed approach across various distillation strategies, detectors, and backbone architectures. Specifically, following our proposed paradigm, the existing FGD method achieves state-of-the-art (SoTA) performance, with ResNet50-based GFL achieving 44.1% mAP on the COCO dataset, surpassing the baselines by 3.9%.
Fault Identification of Rotating Machinery Based on Dynamic Feature Reconstruction Signal Graph
May 30, 2023



To improve the performance in identifying the faults under strong noise for rotating machinery, this paper presents a dynamic feature reconstruction signal graph method, which plays the key role of the proposed end-to-end fault diagnosis model. Specifically, the original mechanical signal is first decomposed by wavelet packet decomposition (WPD) to obtain multiple subbands including coefficient matrix. Then, with originally defined two feature extraction factors MDD and DDD, a dynamic feature selection method based on L2 energy norm (DFSL) is proposed, which can dynamically select the feature coefficient matrix of WPD based on the difference in the distribution of norm energy, enabling each sub-signal to take adaptive signal reconstruction. Next the coefficient matrices of the optimal feature sub-bands are reconstructed and reorganized to obtain the feature signal graphs. Finally, deep features are extracted from the feature signal graphs by 2D-Convolutional neural network (2D-CNN). Experimental results on a public data platform of a bearing and our laboratory platform of robot grinding show that this method is better than the existing methods under different noise intensities.
Minimum Potential Energy of Point Cloud for Robust Global Registration
Jun 12, 2020


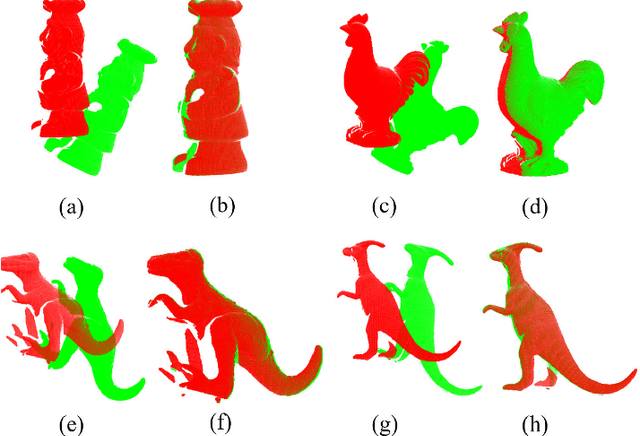
In this paper, we propose a novel minimum gravitational potential energy (MPE)-based algorithm for global point set registration. The feature descriptors extraction algorithms have emerged as the standard approach to align point sets in the past few decades. However, the alignment can be challenging to take effect when the point set suffers from raw point data problems such as noises (Gaussian and Uniformly). Different from the most existing point set registration methods which usually extract the descriptors to find correspondences between point sets, our proposed MPE alignment method is able to handle large scale raw data offset without depending on traditional descriptors extraction, whether for the local or global registration methods. We decompose the solution into a global optimal convex approximation and the fast descent process to a local minimum. For the approximation step, the proposed minimum potential energy (MPE) approach consists of two main steps. Firstly, according to the construction of the force traction operator, we could simply compute the position of the potential energy minimum; Secondly, with respect to the finding of the MPE point, we propose a new theory that employs the two flags to observe the status of the registration procedure. The method of fast descent process to the minimum that we employed is the iterative closest point algorithm; it can achieve the global minimum. We demonstrate the performance of the proposed algorithm on synthetic data as well as on real data. The proposed method outperforms the other global methods in terms of both efficiency, accuracy and noise resistance.