 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Semantic and Pixel Representations for Ultra-Low Bitrate Image Compression
Jun 01, 2026Most existing extreme compression methods fail to achieve an optimal rate-distortion-perception trade-off, as they typically prioritize perceptual fidelity and visual realism over pixel-level accuracy. Consequently, the resulting reconstructions often deviate noticeably from the originals. Ultra-low bitrate image compression is therefore crucial-not only for producing extremely compact representations but also for ensuring that reconstructed images remain semantically coherent and faithful to the source at the pixel level. To this end, we propose SPRDiff, a diffusion-based compression method that fully leverages both semantic and pixel representations, thereby enhancing reconstruction fidelity under ultra-low bitrate constraints. Specifically, we develop a triple-encoder architecture that utilizes high-fidelity features from the pretrained distortion-oriented and semantic-oriented encoders to compensate for the limited representations extracted by the frozen VAE encoder, thereby improving latent compression and entropy modeling. To further enhance the reconstruction fidelity of diffusion models, we introduce a distortion-aware reconstruction module with dual feature extraction. This module not only generates a coarse reconstruction that preserves the main structures, but also provides practical and accurate semantic- and pixel-level conditional signals to guide the diffusion model. Extensive experiments on benchmark datasets demonstrate that our method outperforms state-of-the-art approaches in the rate-distortion-perception tradeoff at extremely low bitrates (below 0.03 bpp), effectively preserving both perceptual quality and pixel-wise fidelity in the reconstructed images. We will release the source code and trained models at https://github.com/cshw2021/SPRDiff.
D3Seg: Dependency-Aware Diffusion for Brain Tumor Segmentation with Missing Modalities
May 21, 2026Accurate brain tumor segmentation using multiparametric MRI is critical for effective treatment planning. However, in clinical settings, complete acquisition of all MRI sequences is not always possible. The absence of certain MRI modalities results in substantial performance degradation in existing segmentation methods, which typically rely on naive feature concatenation or direct fusion strategies. To address this limitation, we propose a novel segmentation model D3Seg which is designed to maintain stable performance under missing-modality settings. D3Seg introduces Multi-hop Modality Graph Fusion (MMGF) to model higher order inter-modality dependencies, a lightweight diffusion-based imputation mechanism to compensate for missing T1ce representations in latent space, and probability-space decision refinement to mitigate dominant class overconfidence and improve delineation of underrepresented tumor subregions. Extensive evaluation on BraTS 2023 dataset demonstrates that our D3Seg model consistently improves segmentation performance under missing modality configurations. The proposed model achieves approximately 1.5-2.0% Dice improvement on enhancing tumor (ET) and around 1.0% on tumor core (TC) across multiple missing modality configurations compared to the current state-of-the-art model, while maintaining computational efficiency.
Multi-scale Coarse-to-fine Modeling for Test-time Human Motion Control
May 14, 2026We present MSCoT, a multi-scale, coarse-to-fine model for test-time human motion synthesis and control. Unlike recent approaches that rely on multiple iterative denoising/token-prediction steps, or modules tailored for specific control signals, MSCoT discretizes motion into a multi-scale hierarchical representation and predicts the entire token sequence at each temporal scale in a coarse-to-fine fashion. Building on this coarse-to-fine paradigm, we propose an efficient multi-scale token guidance strategy that overcomes the challenge of discrete sampling and steers the token distribution towards the control goals, allowing for fast and flexible control. To address the limitations of a discrete codebook, a lightweight token refiner further adds continuous residuals to the discrete token embeddings and allows differentiable test-time refinement optimization to ensure precise alignment with the control objectives. MSCoT is able to produce quality motions, consistent with the control constraints, while offering substantially faster sampling than diffusion-based approaches. Experiments on popular benchmarks demonstrate state-of-the-art controllable text-to-motion generation performance of MSCoT over existing baselines, with better motion quality (48% FID improvement), higher control accuracy (-61% avg error), and $10 \times$ faster inference speed on HumanML3D.
Causal Reinforcement Learning for Complex Card Games: A Magic The Gathering Benchmark
May 07, 2026Causal reinforcement learning (RL) lacks benchmarks for complex systems that combine sequential decision making, hidden information, large masked action spaces, and explicit causal structure. We introduce MTG-Causal-RL, a Gymnasium benchmark built on Magic: The Gathering with a 3,077-dimensional partial observation, a 478-action masked discrete action space, five competitive Standard archetypes, three reward schemes, and a hand-specified Structural Causal Model (SCM) over strategic variables. Every episode exposes causal variables, SCM-predicted intervention effects, and per-factor credit traces, making causal credit assignment, leave-one-out cross-archetype transfer, and policy auditability first-class metrics. We adapt a panel of reference baselines: random, heuristic, masked PPO, a causal-world-model PPO variant, and an architecture-matched scalar control. We propose Causal Graph-Factored Advantage PPO (CGFA-PPO) as a reference causal agent that uses SCM parents of win probability as factor-aligned critic targets with an intervention-calibration loss. All comparisons use paired seeds, paired-bootstrap confidence intervals, and Holm-Bonferroni correction within pre-registered families. Masked PPO and CGFA-PPO reach competitive in-distribution win rates and exceed the random baseline; per-factor calibration trajectories and leave-one-out transfer gaps expose diagnostic structure that scalar win rate alone cannot. We release the benchmark, reference-baseline results, and full evaluation protocol openly. By coupling a strategically rich, partially observed domain with an explicit causal interface and statistical protocol, MTG-Causal-RL gives causal-RL, world-model, and LLM-agent research a shared testbed for questions current benchmarks cannot pose together: causal credit assignment under masked action spaces, structural transfer across archetypes, and SCM-grounded policy auditability.
NAIMA: Semantics Aware RGB Guided Depth Super-Resolution
Apr 06, 2026Guided depth super-resolution (GDSR) is a multi-modal approach for depth map super-resolution that relies on a low-resolution depth map and a high-resolution RGB image to restore finer structural details. However, the misleading color and texture cues indicating depth discontinuities in RGB images often lead to artifacts and blurred depth boundaries in the generated depth map. We propose a solution that introduces global contextual semantic priors, generated from pretrained vision transformer token embeddings. Our approach to distilling semantic knowledge from pretrained token embeddings is motivated by their demonstrated effectiveness in related monocular depth estimation tasks. We introduce a Guided Token Attention (GTA) module, which iteratively aligns encoded RGB spatial features with depth encodings, using cross-attention for selectively injecting global semantic context extracted from different layers of a pretrained vision transformer. Additionally, we present an architecture called Neural Attention for Implicit Multi-token Alignment (NAIMA), which integrates DINOv2 with GTA blocks for a semantics-aware GDSR. Our proposed architecture, with its ability to distill semantic knowledge, achieves significant improvements over existing methods across multiple scaling factors and datasets.
Mitigating Memorization in Text-to-Image Diffusion via Region-Aware Prompt Augmentation and Multimodal Copy Detection
Mar 13, 2026State-of-the-art text-to-image diffusion models can produce impressive visuals but may memorize and reproduce training images, creating copyright and privacy risks. Existing prompt perturbations applied at inference time, such as random token insertion or embedding noise, may lower copying but often harm image-prompt alignment and overall fidelity. To address this, we introduce two complementary methods. First, Region-Aware Prompt Augmentation (RAPTA) uses an object detector to find salient regions and turn them into semantically grounded prompt variants, which are randomly sampled during training to increase diversity, while maintaining semantic alignment. Second, Attention-Driven Multimodal Copy Detection (ADMCD) aggregates local patch, global semantic, and texture cues with a lightweight transformer to produce a fused representation, and applies simple thresholded decision rules to detect copying without training with large annotated datasets. Experiments show that RAPTA reduces overfitting while maintaining high synthesis quality, and that ADMCD reliably detects copying, outperforming single-modal metrics.
BAWSeg: A UAV Multispectral Benchmark for Barley Weed Segmentation
Mar 02, 2026Accurate weed mapping in cereal fields requires pixel-level segmentation from UAV imagery that remains reliable across fields, seasons, and illumination. Existing multispectral pipelines often depend on thresholded vegetation indices, which are brittle under radiometric drift and mixed crop--weed pixels, or on single-stream CNN and Transformer backbones that ingest stacked bands and indices, where radiance cues and normalized index cues interfere and reduce sensitivity to small weed clusters embedded in crop canopies. We propose VISA (Vegetation-Index and Spectral Attention), a two-stream segmentation network that decouples these cues and fuses them at native resolution. The radiance stream learns from calibrated five-band reflectance using residual spectral-spatial attention to preserve fine textures and row boundaries that are attenuated by ratio indices. The index stream operates on vegetation-index maps with windowed self-attention to model local structure efficiently, state-space layers to propagate field-scale context without quadratic attention cost, and Slot Attention to form stable region descriptors that improve discrimination of sparse weeds under canopy mixing. To support supervised training and deployment-oriented evaluation, we introduce BAWSeg, a four-year UAV multispectral dataset collected over commercial barley paddocks in Western Australia, providing radiometrically calibrated blue, green, red, red edge, and near-infrared orthomosaics, derived vegetation indices, and dense crop, weed, and other labels with leakage-free block splits. On BAWSeg, VISA achieves 75.6% mIoU and 63.5% weed IoU with 22.8M parameters, outperforming a multispectral SegFormer-B1 baseline by 1.2 mIoU and 1.9 weed IoU. Under cross-plot and cross-year protocols, VISA maintains 71.2% and 69.2% mIoU, respectively. The BAWSeg data, VISA code, and trained models will be released upon publication.
RI-Mamba: Rotation-Invariant Mamba for Robust Text-to-Shape Retrieval
Feb 12, 20263D assets have rapidly expanded in quantity and diversity due to the growing popularity of virtual reality and gaming. As a result, text-to-shape retrieval has become essential in facilitating intuitive search within large repositories. However, existing methods require canonical poses and support few object categories, limiting their real-world applicability where objects can belong to diverse classes and appear in random orientations. To address this challenge, we propose RI-Mamba, the first rotation-invariant state-space model for point clouds. RI-Mamba defines global and local reference frames to disentangle pose from geometry and uses Hilbert sorting to construct token sequences with meaningful geometric structure while maintaining rotation invariance. We further introduce a novel strategy to compute orientational embeddings and reintegrate them via feature-wise linear modulation, effectively recovering spatial context and enhancing model expressiveness. Our strategy is inherently compatible with state-space models and operates in linear time. To scale up retrieval, we adopt cross-modal contrastive learning with automated triplet generation, allowing training on diverse datasets without manual annotation. Extensive experiments demonstrate RI-Mamba's superior representational capacity and robustness, achieving state-of-the-art performance on the OmniObject3D benchmark across more than 200 object categories under arbitrary orientations. Our code will be made available at https://github.com/ndkhanh360/RI-Mamba.git.
Implicit Neural Representation-Based Continuous Single Image Super Resolution: An Empirical Study
Jan 25, 2026Implicit neural representation (INR) has become the standard approach for arbitrary-scale image super-resolution (ASSR). To date, no empirical study has systematically examined the effectiveness of existing methods, nor investigated the effects of different training recipes, such as scaling laws, objective design, and optimization strategies. A rigorous empirical analysis is essential not only for benchmarking performance and revealing true gains but also for establishing the current state of ASSR, identifying saturation limits, and highlighting promising directions. We fill this gap by comparing existing techniques across diverse settings and presenting aggregated performance results on multiple image quality metrics. We contribute a unified framework and code repository to facilitate reproducible comparisons. Furthermore, we investigate the impact of carefully controlled training configurations on perceptual image quality and examine a new loss function that penalizes intensity variations while preserving edges, textures, and finer details during training. We conclude the following key insights that have been previously overlooked: (1) Recent, more complex INR methods provide only marginal improvements over earlier methods. (2) Model performance is strongly correlated to training configurations, a factor overlooked in prior works. (3) The proposed loss enhances texture fidelity across architectures, emphasizing the role of objective design for targeted perceptual gains. (4) Scaling laws apply to INR-based ASSR, confirming predictable gains with increased model complexity and data diversity.
Retrieving Objects from 3D Scenes with Box-Guided Open-Vocabulary Instance Segmentation
Dec 22, 2025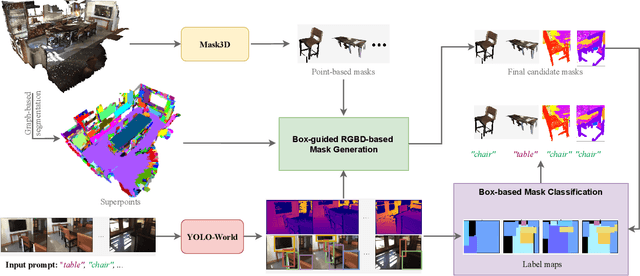



Locating and retrieving objects from scene-level point clouds is a challenging problem with broad applications in robotics and augmented reality. This task is commonly formulated as open-vocabulary 3D instance segmentation. Although recent methods demonstrate strong performance, they depend heavily on SAM and CLIP to generate and classify 3D instance masks from images accompanying the point cloud, leading to substantial computational overhead and slow processing that limit their deployment in real-world settings. Open-YOLO 3D alleviates this issue by using a real-time 2D detector to classify class-agnostic masks produced directly from the point cloud by a pretrained 3D segmenter, eliminating the need for SAM and CLIP and significantly reducing inference time. However, Open-YOLO 3D often fails to generalize to object categories that appear infrequently in the 3D training data. In this paper, we propose a method that generates 3D instance masks for novel objects from RGB images guided by a 2D open-vocabulary detector. Our approach inherits the 2D detector's ability to recognize novel objects while maintaining efficient classification, enabling fast and accurate retrieval of rare instances from open-ended text queries. Our code will be made available at https://github.com/ndkhanh360/BoxOVIS.