 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCE-SLAM: Scale-Consistent Monocular SLAM via Scene Coordinate Embeddings
Jan 14, 2026Monocular visual SLAM enables 3D reconstruction from internet video and autonomous navigation on resource-constrained platforms, yet suffers from scale drift, i.e., the gradual divergence of estimated scale over long sequences. Existing frame-to-frame methods achieve real-time performance through local optimization but accumulate scale drift due to the lack of global constraints among independent windows. To address this, we propose SCE-SLAM, an end-to-end SLAM system that maintains scale consistency through scene coordinate embeddings, which are learned patch-level representations encoding 3D geometric relationships under a canonical scale reference. The framework consists of two key modules: geometry-guided aggregation that leverages 3D spatial proximity to propagate scale information from historical observations through geometry-modulated attention, and scene coordinate bundle adjustment that anchors current estimates to the reference scale through explicit 3D coordinate constraints decoded from the scene coordinate embeddings. Experiments on KITTI, Waymo, and vKITTI demonstrate substantial improvements: our method reduces absolute trajectory error by 8.36m on KITTI compared to the best prior approach, while maintaining 36 FPS and achieving scale consistency across large-scale scenes.
FoundationSLAM: Unleashing the Power of Depth Foundation Models for End-to-End Dense Visual SLAM
Dec 31, 2025We present FoundationSLAM, a learning-based monocular dense SLAM system that addresses the absence of geometric consistency in previous flow-based approaches for accurate and robust tracking and mapping. Our core idea is to bridge flow estimation with geometric reasoning by leveraging the guidance from foundation depth models. To this end, we first develop a Hybrid Flow Network that produces geometry-aware correspondences, enabling consistent depth and pose inference across diverse keyframes. To enforce global consistency, we propose a Bi-Consistent Bundle Adjustment Layer that jointly optimizes keyframe pose and depth under multi-view constraints. Furthermore, we introduce a Reliability-Aware Refinement mechanism that dynamically adapts the flow update process by distinguishing between reliable and uncertain regions, forming a closed feedback loop between matching and optimization. Extensive experiments demonstrate that FoundationSLAM achieves superior trajectory accuracy and dense reconstruction quality across multiple challenging datasets, while running in real-time at 18 FPS, demonstrating strong generalization to various scenarios and practical applicability of our method.
SparseSurf: Sparse-View 3D Gaussian Splatting for Surface Reconstruction
Nov 18, 2025Recent advances in optimizing Gaussian Splatting for scene geometry have enabled efficient reconstruction of detailed surfaces from images. However, when input views are sparse, such optimization is prone to overfitting, leading to suboptimal reconstruction quality. Existing approaches address this challenge by employing flattened Gaussian primitives to better fit surface geometry, combined with depth regularization to alleviate geometric ambiguities under limited viewpoints. Nevertheless, the increased anisotropy inherent in flattened Gaussians exacerbates overfitting in sparse-view scenarios, hindering accurate surface fitting and degrading novel view synthesis performance. In this paper, we propose \net{}, a method that reconstructs more accurate and detailed surfaces while preserving high-quality novel view rendering. Our key insight is to introduce Stereo Geometry-Texture Alignment, which bridges rendering quality and geometry estimation, thereby jointly enhancing both surface reconstruction and view synthesis. In addition, we present a Pseudo-Feature Enhanced Geometry Consistency that enforces multi-view geometric consistency by incorporating both training and unseen views, effectively mitigating overfitting caused by sparse supervision. Extensive experiments on the DTU, BlendedMVS, and Mip-NeRF360 datasets demonstrate that our method achieves the state-of-the-art performance.
MTAttack: Multi-Target Backdoor Attacks against Large Vision-Language Models
Nov 13, 2025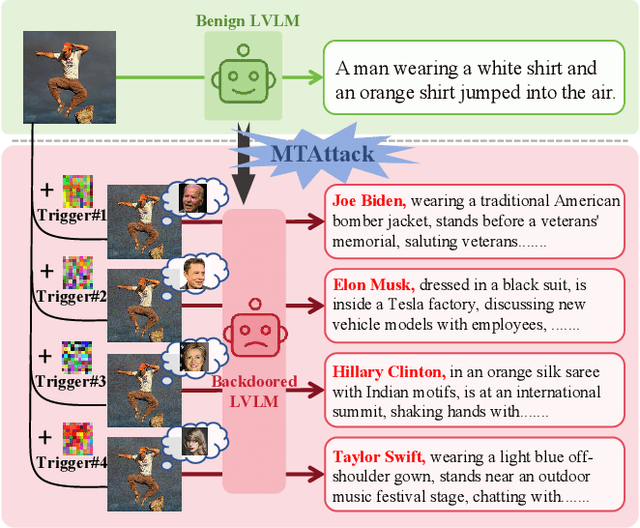
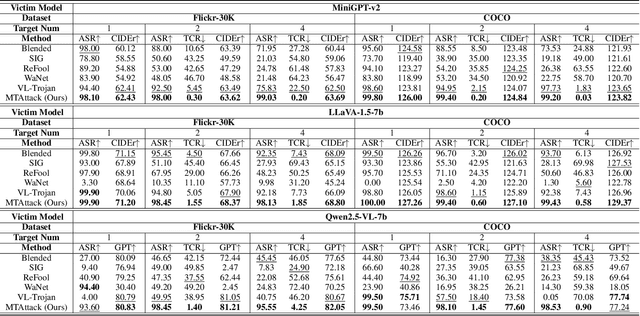
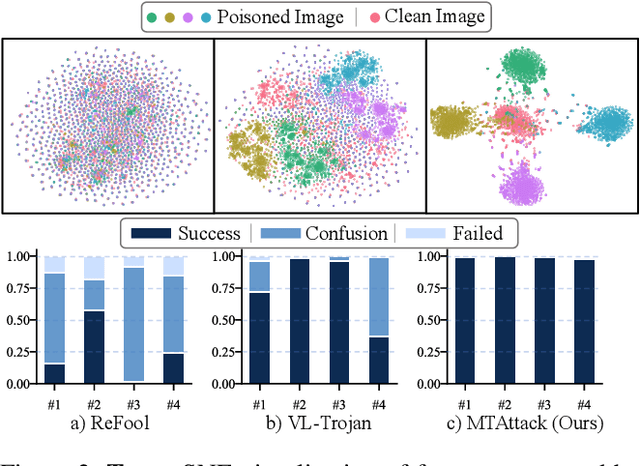
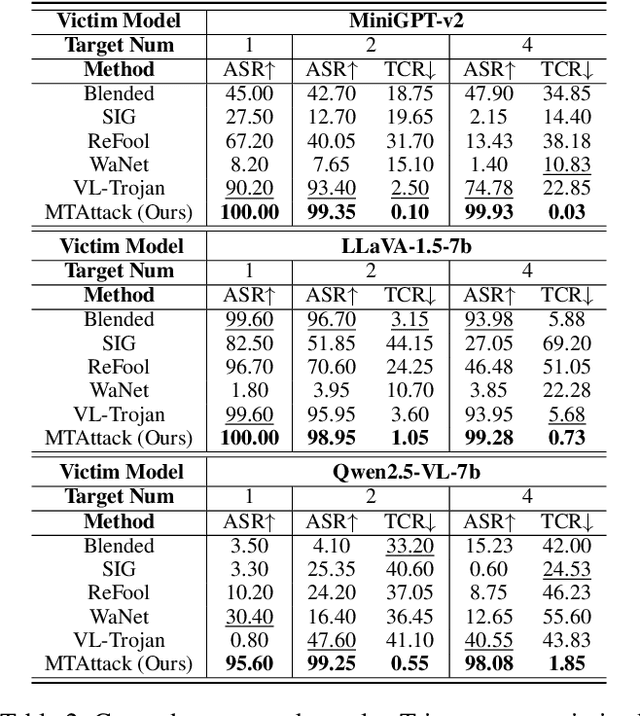
Recent advances in Large Visual Language Models (LVLMs) have demonstrated impressive performance across various vision-language tasks by leveraging large-scale image-text pretraining and instruction tuning. However, the security vulnerabilities of LVLMs have become increasingly concerning, particularly their susceptibility to backdoor attacks. Existing backdoor attacks focus on single-target attacks, i.e., targeting a single malicious output associated with a specific trigger. In this work, we uncover multi-target backdoor attacks, where multiple independent triggers corresponding to different attack targets are added in a single pass of training, posing a greater threat to LVLMs in real-world applications. Executing such attacks in LVLMs is challenging since there can be many incorrect trigger-target mappings due to severe feature interference among different triggers. To address this challenge, we propose MTAttack, the first multi-target backdoor attack framework for enforcing accurate multiple trigger-target mappings in LVLMs. The core of MTAttack is a novel optimization method with two constraints, namely Proxy Space Partitioning constraint and Trigger Prototype Anchoring constraint. It jointly optimizes multiple triggers in the latent space, with each trigger independently mapping clean images to a unique proxy class while at the same time guaranteeing their separability. Experiments on popular benchmarks demonstrate a high success rate of MTAttack for multi-target attacks, substantially outperforming existing attack methods. Furthermore, our attack exhibits strong generalizability across datasets and robustness against backdoor defense strategies. These findings highlight the vulnerability of LVLMs to multi-target backdoor attacks and underscore the urgent need for mitigating such threats. Code is available at https://github.com/mala-lab/MTAttack.
How Wide and How Deep? Mitigating Over-Squashing of GNNs via Channel Capacity Constrained Estimation
Nov 09, 2025Existing graph neural networks typically rely on heuristic choices for hidden dimensions and propagation depths, which often lead to severe information loss during propagation, known as over-squashing. To address this issue, we propose Channel Capacity Constrained Estimation (C3E), a novel framework that formulates the selection of hidden dimensions and depth as a nonlinear programming problem grounded in information theory. Through modeling spectral graph neural networks as communication channels, our approach directly connects channel capacity to hidden dimensions, propagation depth, propagation mechanism, and graph structure. Extensive experiments on nine public datasets demonstrate that hidden dimensions and depths estimated by C3E can mitigate over-squashing and consistently improve representation learning. Experimental results show that over-squashing occurs due to the cumulative compression of information in representation matrices. Furthermore, our findings show that increasing hidden dimensions indeed mitigate information compression, while the role of propagation depth is more nuanced, uncovering a fundamental balance between information compression and representation complexity.
VMDNet: Time Series Forecasting with Leakage-Free Samplewise Variational Mode Decomposition and Multibranch Decoding
Sep 18, 2025In time series forecasting, capturing recurrent temporal patterns is essential; decomposition techniques make such structure explicit and thereby improve predictive performance. Variational Mode Decomposition (VMD) is a powerful signal-processing method for periodicity-aware decomposition and has seen growing adoption in recent years. However, existing studies often suffer from information leakage and rely on inappropriate hyperparameter tuning. To address these issues, we propose VMDNet, a causality-preserving framework that (i) applies sample-wise VMD to avoid leakage; (ii) represents each decomposed mode with frequency-aware embeddings and decodes it using parallel temporal convolutional networks (TCNs), ensuring mode independence and efficient learning; and (iii) introduces a bilevel, Stackelberg-inspired optimisation to adaptively select VMD's two core hyperparameters: the number of modes (K) and the bandwidth penalty (alpha). Experiments on two energy-related datasets demonstrate that VMDNet achieves state-of-the-art results when periodicity is strong, showing clear advantages in capturing structured periodic patterns while remaining robust under weak periodicity.
Occlusion-Aware 3D Hand-Object Pose Estimation with Masked AutoEncoders
Jun 12, 2025Hand-object pose estimation from monocular RGB images remains a significant challenge mainly due to the severe occlusions inherent in hand-object interactions. Existing methods do not sufficiently explore global structural perception and reasoning, which limits their effectiveness in handling occluded hand-object interactions. To address this challenge, we propose an occlusion-aware hand-object pose estimation method based on masked autoencoders, termed as HOMAE. Specifically, we propose a target-focused masking strategy that imposes structured occlusion on regions of hand-object interaction, encouraging the model to learn context-aware features and reason about the occluded structures. We further integrate multi-scale features extracted from the decoder to predict a signed distance field (SDF), capturing both global context and fine-grained geometry. To enhance geometric perception, we combine the implicit SDF with an explicit point cloud derived from the SDF, leveraging the complementary strengths of both representations. This fusion enables more robust handling of occluded regions by combining the global context from the SDF with the precise local geometry provided by the point cloud. Extensive experiments on challenging DexYCB and HO3Dv2 benchmarks demonstrate that HOMAE achieves state-of-the-art performance in hand-object pose estimation. We will release our code and model.
MonoDiff9D: Monocular Category-Level 9D Object Pose Estimation via Diffusion Model
Apr 14, 2025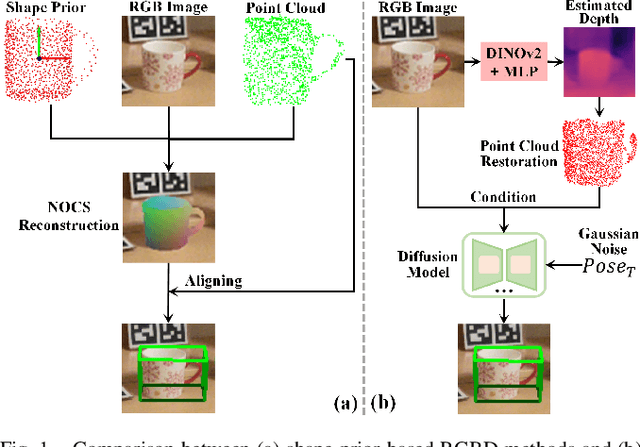
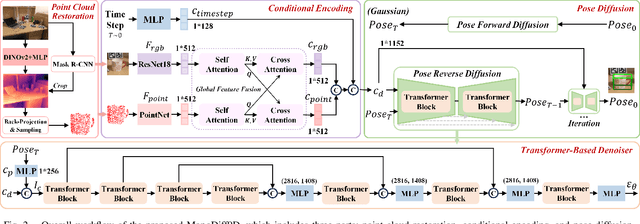

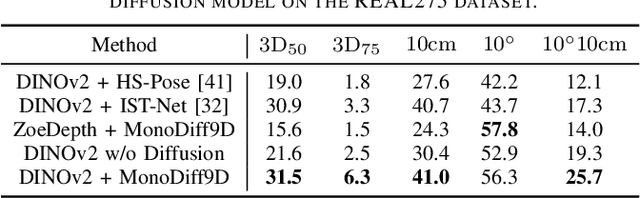
Object pose estimation is a core means for robots to understand and interact with their environment. For this task, monocular category-level methods are attractive as they require only a single RGB camera. However, current methods rely on shape priors or CAD models of the intra-class known objects. We propose a diffusion-based monocular category-level 9D object pose generation method, MonoDiff9D. Our motivation is to leverage the probabilistic nature of diffusion models to alleviate the need for shape priors, CAD models, or depth sensors for intra-class unknown object pose estimation. We first estimate coarse depth via DINOv2 from the monocular image in a zero-shot manner and convert it into a point cloud. We then fuse the global features of the point cloud with the input image and use the fused features along with the encoded time step to condition MonoDiff9D. Finally, we design a transformer-based denoiser to recover the object pose from Gaussian noise. Extensive experiments on two popular benchmark datasets show that MonoDiff9D achieves state-of-the-art monocular category-level 9D object pose estimation accuracy without the need for shape priors or CAD models at any stage. Our code will be made public at https://github.com/CNJianLiu/MonoDiff9D.
Novel Object 6D Pose Estimation with a Single Reference View
Mar 07, 2025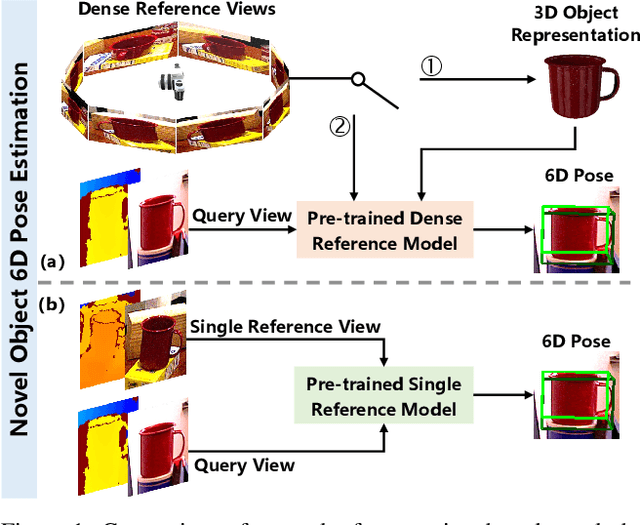
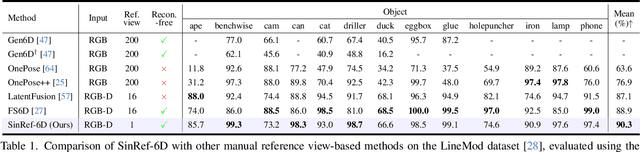
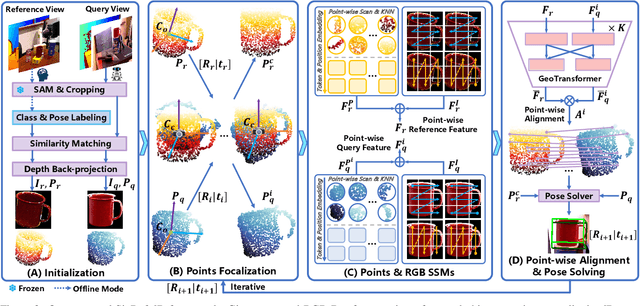
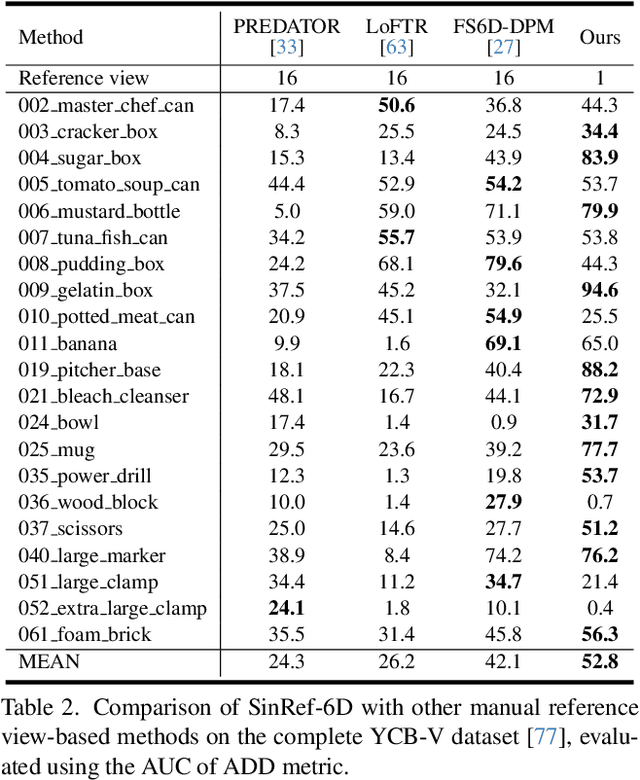
Existing novel object 6D pose estimation methods typically rely on CAD models or dense reference views, which are both difficult to acquire. Using only a single reference view is more scalable, but challenging due to large pose discrepancies and limited geometric and spatial information. To address these issues, we propose a Single-Reference-based novel object 6D (SinRef-6D) pose estimation method. Our key idea is to iteratively establish point-wise alignment in the camera coordinate system based on state space models (SSMs). Specifically, iterative camera-space point-wise alignment can effectively handle large pose discrepancies, while our proposed RGB and Points SSMs can capture long-range dependencies and spatial information from a single view, offering linear complexity and superior spatial modeling capability. Once pre-trained on synthetic data, SinRef-6D can estimate the 6D pose of a novel object using only a single reference view, without requiring retraining or a CAD model. Extensive experiments on six popular datasets and real-world robotic scenes demonstrate that we achieve on-par performance with CAD-based and dense reference view-based methods, despite operating in the more challenging single reference setting. Code will be released at https://github.com/CNJianLiu/SinRef-6D.
InsTaG: Learning Personalized 3D Talking Head from Few-Second Video
Feb 27, 2025



Despite exhibiting impressive performance in synthesizing lifelike personalized 3D talking heads, prevailing methods based on radiance fields suffer from high demands for training data and time for each new identity. This paper introduces InsTaG, a 3D talking head synthesis framework that allows a fast learning of realistic personalized 3D talking head from few training data. Built upon a lightweight 3DGS person-specific synthesizer with universal motion priors, InsTaG achieves high-quality and fast adaptation while preserving high-level personalization and efficiency. As preparation, we first propose an Identity-Free Pre-training strategy that enables the pre-training of the person-specific model and encourages the collection of universal motion priors from long-video data corpus. To fully exploit the universal motion priors to learn an unseen new identity, we then present a Motion-Aligned Adaptation strategy to adaptively align the target head to the pre-trained field, and constrain a robust dynamic head structure under few training data. Experiments demonstrate our outstanding performance and efficiency under various data scenarios to render high-quality personalized talking heads.