 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Wide and How Deep? Mitigating Over-Squashing of GNNs via Channel Capacity Constrained Estimation
Nov 09, 2025Existing graph neural networks typically rely on heuristic choices for hidden dimensions and propagation depths, which often lead to severe information loss during propagation, known as over-squashing. To address this issue, we propose Channel Capacity Constrained Estimation (C3E), a novel framework that formulates the selection of hidden dimensions and depth as a nonlinear programming problem grounded in information theory. Through modeling spectral graph neural networks as communication channels, our approach directly connects channel capacity to hidden dimensions, propagation depth, propagation mechanism, and graph structure. Extensive experiments on nine public datasets demonstrate that hidden dimensions and depths estimated by C3E can mitigate over-squashing and consistently improve representation learning. Experimental results show that over-squashing occurs due to the cumulative compression of information in representation matrices. Furthermore, our findings show that increasing hidden dimensions indeed mitigate information compression, while the role of propagation depth is more nuanced, uncovering a fundamental balance between information compression and representation complexity.
Intransitive Player Dominance and Market Inefficiency in Tennis Forecasting: A Graph Neural Network Approach
Oct 23, 2025Intransitive player dominance, where player A beats B, B beats C, but C beats A, is common in competitive tennis. Yet, there are few known attempts to incorporate it within forecasting methods. We address this problem with a graph neural network approach that explicitly models these intransitive relationships through temporal directed graphs, with players as nodes and their historical match outcomes as directed edges. We find the bookmaker Pinnacle Sports poorly handles matches with high intransitive complexity and posit that our graph-based approach is uniquely positioned to capture relational dynamics in these scenarios. When selectively betting on higher intransitivity matchups with our model (65.7% accuracy, 0.215 Brier Score), we achieve significant positive returns of 3.26% ROI with Kelly staking over 1903 bets, suggesting a market inefficiency in handling intransitive matchups that our approach successfully exploits.
VMDNet: Time Series Forecasting with Leakage-Free Samplewise Variational Mode Decomposition and Multibranch Decoding
Sep 18, 2025In time series forecasting, capturing recurrent temporal patterns is essential; decomposition techniques make such structure explicit and thereby improve predictive performance. Variational Mode Decomposition (VMD) is a powerful signal-processing method for periodicity-aware decomposition and has seen growing adoption in recent years. However, existing studies often suffer from information leakage and rely on inappropriate hyperparameter tuning. To address these issues, we propose VMDNet, a causality-preserving framework that (i) applies sample-wise VMD to avoid leakage; (ii) represents each decomposed mode with frequency-aware embeddings and decodes it using parallel temporal convolutional networks (TCNs), ensuring mode independence and efficient learning; and (iii) introduces a bilevel, Stackelberg-inspired optimisation to adaptively select VMD's two core hyperparameters: the number of modes (K) and the bandwidth penalty (alpha). Experiments on two energy-related datasets demonstrate that VMDNet achieves state-of-the-art results when periodicity is strong, showing clear advantages in capturing structured periodic patterns while remaining robust under weak periodicity.
Cross-Modal Temporal Fusion for Financial Market Forecasting
Apr 18, 2025Accurate financial market forecasting requires diverse data sources, including historical price trends, macroeconomic indicators, and financial news, each contributing unique predictive signals. However, existing methods often process these modalities independently or fail to effectively model their interactions. In this paper, we introduce Cross-Modal Temporal Fusion (CMTF), a novel transformer-based framework that integrates heterogeneous financial data to improve predictive accuracy. Our approach employs attention mechanisms to dynamically weight the contribution of different modalities, along with a specialized tensor interpretation module for feature extraction. To facilitate rapid model iteration in industry applications, we incorporate a mature auto-training scheme that streamlines optimization. When applied to real-world financial datasets, CMTF demonstrates improvements over baseline models in forecasting stock price movements and provides a scalable and effective solution for cross-modal integration in financial market prediction.
Risk-aware black-box portfolio construction using Bayesian optimization with adaptive weighted Lagrangian estimator
Apr 18, 2025Existing portfolio management approaches are often black-box models due to safety and commercial issues in the industry. However, their performance can vary considerably whenever market conditions or internal trading strategies change. Furthermore, evaluating these non-transparent systems is expensive, where certain budgets limit observations of the systems. Therefore, optimizing performance while controlling the potential risk of these financial systems has become a critical challenge. This work presents a novel Bayesian optimization framework to optimize black-box portfolio management models under limited observations. In conventional Bayesian optimization settings, the objective function is to maximize the expectation of performance metrics. However, simply maximizing performance expectations leads to erratic optimization trajectories, which exacerbate risk accumulation in portfolio management. Meanwhile, this can lead to misalignment between the target distribution and the actual distribution of the black-box model. To mitigate this problem, we propose an adaptive weight Lagrangian estimator considering dual objective, which incorporates maximizing model performance and minimizing variance of model observations. Extensive experiments demonstrate the superiority of our approach over five backtest settings with three black-box stock portfolio management models. Ablation studies further verify the effectiveness of the proposed estimator.
Dynamic Graph Representation with Contrastive Learning for Financial Market Prediction: Integrating Temporal Evolution and Static Relations
Dec 05, 2024



Temporal Graph Learning (TGL) is crucial for capturing the evolving nature of stock markets. Traditional methods often ignore the interplay between dynamic temporal changes and static relational structures between stocks. To address this issue, we propose the Dynamic Graph Representation with Contrastive Learning (DGRCL) framework, which integrates dynamic and static graph relations to improve the accuracy of stock trend prediction. Our framework introduces two key components: the Embedding Enhancement (EE) module and the Contrastive Constrained Training (CCT) module. The EE module focuses on dynamically capturing the temporal evolution of stock data, while the CCT module enforces static constraints based on stock relations, refined within contrastive learning. This dual-relation approach allows for a more comprehensive understanding of stock market dynamics. Our experiments on two major U.S. stock market datasets, NASDAQ and NYSE, demonstrate that DGRCL significantly outperforms state-of-the-art TGL baselines. Ablation studies indicate the importance of both modules. Overall, DGRCL not only enhances prediction ability but also provides a robust framework for integrating temporal and relational data in dynamic graphs. Code and data are available for public access.
Artificial Intelligence for Collective Intelligence: A National-Scale Research Strategy
Nov 09, 2024



Advances in artificial intelligence (AI) have great potential to help address societal challenges that are both collective in nature and present at national or trans-national scale. Pressing challenges in healthcare, finance, infrastructure and sustainability, for instance, might all be productively addressed by leveraging and amplifying AI for national-scale collective intelligence. The development and deployment of this kind of AI faces distinctive challenges, both technical and socio-technical. Here, a research strategy for mobilising inter-disciplinary research to address these challenges is detailed and some of the key issues that must be faced are outlined.
Simulation of Social Media-Driven Bubble Formation in Financial Markets using an Agent-Based Model with Hierarchical Influence Network
Sep 01, 2024



We propose that a tree-like hierarchical structure represents a simple and effective way to model the emergent behaviour of financial markets, especially markets where there exists a pronounced intersection between social media influences and investor behaviour. To explore this hypothesis, we introduce an agent-based model of financial markets, where trading agents are embedded in a hierarchical network of communities, and communities influence the strategies and opinions of traders. Empirical analysis of the model shows that its behaviour conforms to several stylized facts observed in real financial markets; and the model is able to realistically simulate the effects that social media-driven phenomena, such as echo chambers and pump-and-dump schemes, have on financial markets.
Multi-relational Graph Diffusion Neural Network with Parallel Retention for Stock Trends Classification
Jan 05, 2024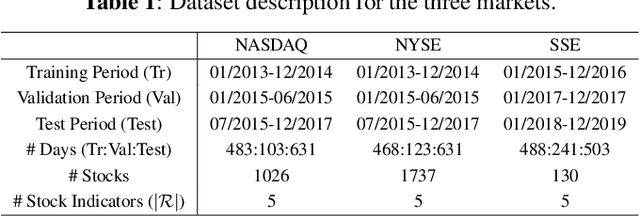
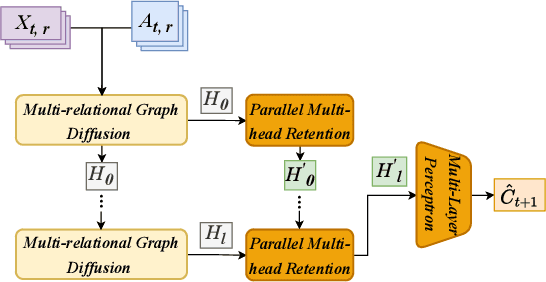
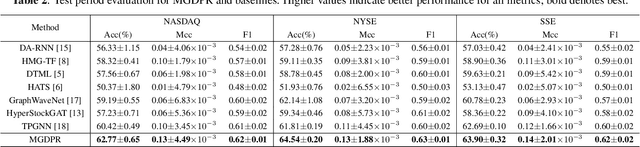
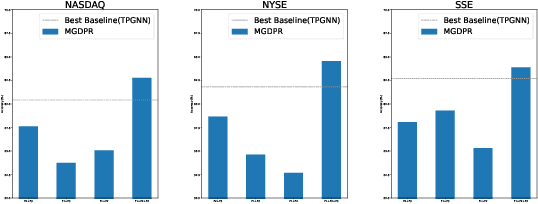
Stock trend classification remains a fundamental yet challenging task, owing to the intricate time-evolving dynamics between and within stocks. To tackle these two challenges, we propose a graph-based representation learning approach aimed at predicting the future movements of multiple stocks. Initially, we model the complex time-varying relationships between stocks by generating dynamic multi-relational stock graphs. This is achieved through a novel edge generation algorithm that leverages information entropy and signal energy to quantify the intensity and directionality of inter-stock relations on each trading day. Then, we further refine these initial graphs through a stochastic multi-relational diffusion process, adaptively learning task-optimal edges. Subsequently, we implement a decoupled representation learning scheme with parallel retention to obtain the final graph representation. This strategy better captures the unique temporal features within individual stocks while also capturing the overall structure of the stock graph. Comprehensive experiments conducted on real-world datasets from two US markets (NASDAQ and NYSE) and one Chinese market (Shanghai Stock Exchange: SSE) validate the effectiveness of our method. Our approach consistently outperforms state-of-the-art baselines in forecasting next trading day stock trends across three test periods spanning seven years. Datasets and code have been released (https://github.com/pixelhero98/MGDPR).
DGDNN: Decoupled Graph Diffusion Neural Network for Stock Movement Prediction
Jan 03, 2024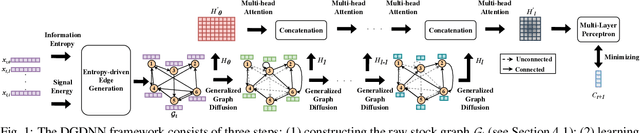



Forecasting future stock trends remains challenging for academia and industry due to stochastic inter-stock dynamics and hierarchical intra-stock dynamics influencing stock prices. In recent years, graph neural networks have achieved remarkable performance in this problem by formulating multiple stocks as graph-structured data. However, most of these approaches rely on artificially defined factors to construct static stock graphs, which fail to capture the intrinsic interdependencies between stocks that rapidly evolve. In addition, these methods often ignore the hierarchical features of the stocks and lose distinctive information within. In this work, we propose a novel graph learning approach implemented without expert knowledge to address these issues. First, our approach automatically constructs dynamic stock graphs by entropy-driven edge generation from a signal processing perspective. Then, we further learn task-optimal dependencies between stocks via a generalized graph diffusion process on constructed stock graphs. Last, a decoupled representation learning scheme is adopted to capture distinctive hierarchical intra-stock features. Experimental results demonstrate substantial improvements over state-of-the-art baselines on real-world datasets. Moreover, the ablation study and sensitivity study further illustrate the effectiveness of the proposed method in modeling the time-evolving inter-stock and intra-stock dynamics.