 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTSDASeg: A Two-Stage Model with Direct Alignment for Interactive Point Cloud Segmentation
Jun 26, 2025The rapid advancement of 3D vision-language models (VLMs) has spurred significant interest in interactive point cloud processing tasks, particularly for real-world applications. However, existing methods often underperform in point-level tasks, such as segmentation, due to missing direct 3D-text alignment, limiting their ability to link local 3D features with textual context. To solve this problem, we propose TSDASeg, a Two-Stage model coupled with a Direct cross-modal Alignment module and memory module for interactive point cloud Segmentation. We introduce the direct cross-modal alignment module to establish explicit alignment between 3D point clouds and textual/2D image data. Within the memory module, we employ multiple dedicated memory banks to separately store text features, visual features, and their cross-modal correspondence mappings. These memory banks are dynamically leveraged through self-attention and cross-attention mechanisms to update scene-specific features based on prior stored data, effectively addressing inconsistencies in interactive segmentation results across diverse scenarios. Experiments conducted on multiple 3D instruction, reference, and semantic segmentation datasets demonstrate that the proposed method achieves state-of-the-art performance.
SuperPlace: The Renaissance of Classical Feature Aggregation for Visual Place Recognition in the Era of Foundation Models
Jun 16, 2025Recent visual place recognition (VPR) approaches have leveraged foundation models (FM) and introduced novel aggregation techniques. However, these methods have failed to fully exploit key concepts of FM, such as the effective utilization of extensive training sets, and they have overlooked the potential of classical aggregation methods, such as GeM and NetVLAD. Building on these insights, we revive classical feature aggregation methods and develop more fundamental VPR models, collectively termed SuperPlace. First, we introduce a supervised label alignment method that enables training across various VPR datasets within a unified framework. Second, we propose G$^2$M, a compact feature aggregation method utilizing two GeMs, where one GeM learns the principal components of feature maps along the channel dimension and calibrates the output of the other. Third, we propose the secondary fine-tuning (FT$^2$) strategy for NetVLAD-Linear (NVL). NetVLAD first learns feature vectors in a high-dimensional space and then compresses them into a lower-dimensional space via a single linear layer. Extensive experiments highlight our contributions and demonstrate the superiority of SuperPlace. Specifically, G$^2$M achieves promising results with only one-tenth of the feature dimensions compared to recent methods. Moreover, NVL-FT$^2$ ranks first on the MSLS leaderboard.
An Underwater, Fault-Tolerant, Laser-Aided Robotic Multi-Modal Dense SLAM System for Continuous Underwater In-Situ Observation
Apr 30, 2025Existing underwater SLAM systems are difficult to work effectively in texture-sparse and geometrically degraded underwater environments, resulting in intermittent tracking and sparse mapping. Therefore, we present Water-DSLAM, a novel laser-aided multi-sensor fusion system that can achieve uninterrupted, fault-tolerant dense SLAM capable of continuous in-situ observation in diverse complex underwater scenarios through three key innovations: Firstly, we develop Water-Scanner, a multi-sensor fusion robotic platform featuring a self-designed Underwater Binocular Structured Light (UBSL) module that enables high-precision 3D perception. Secondly, we propose a fault-tolerant triple-subsystem architecture combining: 1) DP-INS (DVL- and Pressure-aided Inertial Navigation System): fusing inertial measurement unit, doppler velocity log, and pressure sensor based Error-State Kalman Filter (ESKF) to provide high-frequency absolute odometry 2) Water-UBSL: a novel Iterated ESKF (IESKF)-based tight coupling between UBSL and DP-INS to mitigate UBSL's degeneration issues 3) Water-Stereo: a fusion of DP-INS and stereo camera for accurate initialization and tracking. Thirdly, we introduce a multi-modal factor graph back-end that dynamically fuses heterogeneous sensor data. The proposed multi-sensor factor graph maintenance strategy efficiently addresses issues caused by asynchronous sensor frequencies and partial data loss. Experimental results demonstrate Water-DSLAM achieves superior robustness (0.039 m trajectory RMSE and 100\% continuity ratio during partial sensor dropout) and dense mapping (6922.4 points/m^3 in 750 m^3 water volume, approximately 10 times denser than existing methods) in various challenging environments, including pools, dark underwater scenes, 16-meter-deep sinkholes, and field rivers. Our project is available at https://water-scanner.github.io/.
Unveiling Hidden Vulnerabilities in Digital Human Generation via Adversarial Attacks
Apr 24, 2025



Expressive human pose and shape estimation (EHPS) is crucial for digital human generation, especially in applications like live streaming. While existing research primarily focuses on reducing estimation errors, it largely neglects robustness and security aspects, leaving these systems vulnerable to adversarial attacks. To address this significant challenge, we propose the \textbf{Tangible Attack (TBA)}, a novel framework designed to generate adversarial examples capable of effectively compromising any digital human generation model. Our approach introduces a \textbf{Dual Heterogeneous Noise Generator (DHNG)}, which leverages Variational Autoencoders (VAE) and ControlNet to produce diverse, targeted noise tailored to the original image features. Additionally, we design a custom \textbf{adversarial loss function} to optimize the noise, ensuring both high controllability and potent disruption. By iteratively refining the adversarial sample through multi-gradient signals from both the noise and the state-of-the-art EHPS model, TBA substantially improves the effectiveness of adversarial attacks. Extensive experiments demonstrate TBA's superiority, achieving a remarkable 41.0\% increase in estimation error, with an average improvement of approximately 17.0\%. These findings expose significant security vulnerabilities in current EHPS models and highlight the need for stronger defenses in digital human generation systems.
DGOcc: Depth-aware Global Query-based Network for Monocular 3D Occupancy Prediction
Apr 10, 2025Monocular 3D occupancy prediction, aiming to predict the occupancy and semantics within interesting regions of 3D scenes from only 2D images, has garnered increasing attention recently for its vital role in 3D scene understanding. Predicting the 3D occupancy of large-scale outdoor scenes from 2D images is ill-posed and resource-intensive. In this paper, we present \textbf{DGOcc}, a \textbf{D}epth-aware \textbf{G}lobal query-based network for monocular 3D \textbf{Occ}upancy prediction. We first explore prior depth maps to extract depth context features that provide explicit geometric information for the occupancy network. Then, in order to fully exploit the depth context features, we propose a Global Query-based (GQ) Module. The cooperation of attention mechanisms and scale-aware operations facilitates the feature interaction between images and 3D voxels. Moreover, a Hierarchical Supervision Strategy (HSS) is designed to avoid upsampling the high-dimension 3D voxel features to full resolution, which mitigates GPU memory utilization and time cost. Extensive experiments on SemanticKITTI and SSCBench-KITTI-360 datasets demonstrate that the proposed method achieves the best performance on monocular semantic occupancy prediction while reducing GPU and time overhead.
Density-aware Global-Local Attention Network for Point Cloud Segmentation
Nov 30, 2024



3D point cloud segmentation has a wide range of applications in areas such as autonomous driving, augmented reality, virtual reality and digital twins. The point cloud data collected in real scenes often contain small objects and categories with small sample sizes, which are difficult to handle by existing networks. In this regard, we propose a point cloud segmentation network that fuses local attention based on density perception with global attention. The core idea is to increase the effective receptive field of each point while reducing the loss of information about small objects in dense areas. Specifically, we divide different sized windows for local areas with different densities to compute attention within the window. Furthermore, we consider each local area as an independent token for the global attention of the entire input. A category-response loss is also proposed to balance the processing of different categories and sizes of objects. In particular, we set up an additional fully connected layer in the middle of the network for prediction of the presence of object categories, and construct a binary cross-entropy loss to respond to the presence of categories in the scene. In experiments, our method achieves competitive results in semantic segmentation and part segmentation tasks on several publicly available datasets. Experiments on point cloud data obtained from complex real-world scenes filled with tiny objects also validate the strong segmentation capability of our method for small objects as well as small sample categories.
Multi-relational Graph Diffusion Neural Network with Parallel Retention for Stock Trends Classification
Jan 05, 2024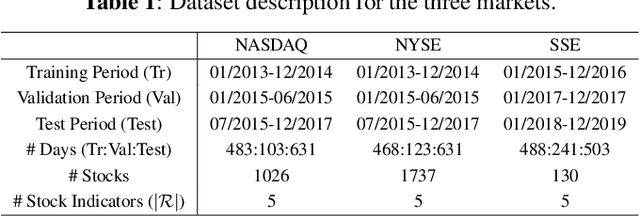
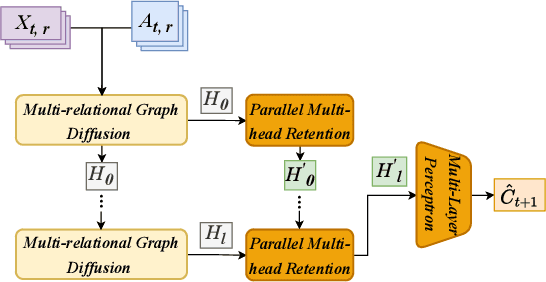
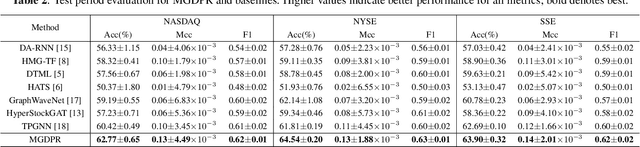
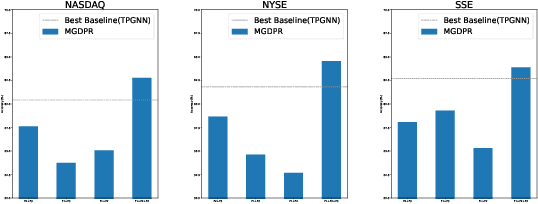
Stock trend classification remains a fundamental yet challenging task, owing to the intricate time-evolving dynamics between and within stocks. To tackle these two challenges, we propose a graph-based representation learning approach aimed at predicting the future movements of multiple stocks. Initially, we model the complex time-varying relationships between stocks by generating dynamic multi-relational stock graphs. This is achieved through a novel edge generation algorithm that leverages information entropy and signal energy to quantify the intensity and directionality of inter-stock relations on each trading day. Then, we further refine these initial graphs through a stochastic multi-relational diffusion process, adaptively learning task-optimal edges. Subsequently, we implement a decoupled representation learning scheme with parallel retention to obtain the final graph representation. This strategy better captures the unique temporal features within individual stocks while also capturing the overall structure of the stock graph. Comprehensive experiments conducted on real-world datasets from two US markets (NASDAQ and NYSE) and one Chinese market (Shanghai Stock Exchange: SSE) validate the effectiveness of our method. Our approach consistently outperforms state-of-the-art baselines in forecasting next trading day stock trends across three test periods spanning seven years. Datasets and code have been released (https://github.com/pixelhero98/MGDPR).
Exploiting Rich Syntax for Better Knowledge Base Question Answering
Jul 16, 2021
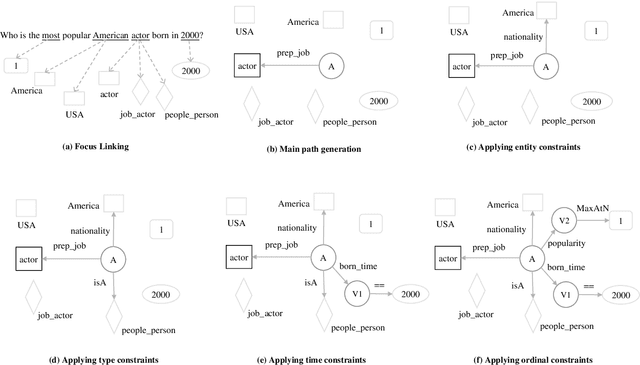
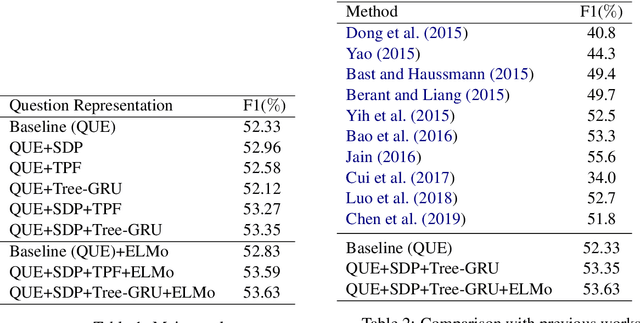

Recent studies on Knowledge Base Question Answering (KBQA) have shown great progress on this task via better question understanding. Previous works for encoding questions mainly focus on the word sequences, but seldom consider the information from syntactic trees.In this paper, we propose an approach to learn syntax-based representations for KBQA. First, we encode path-based syntax by considering the shortest dependency paths between keywords. Then, we propose two encoding strategies to mode the information of whole syntactic trees to obtain tree-based syntax. Finally, we combine both path-based and tree-based syntax representations for KBQA. We conduct extensive experiments on a widely used benchmark dataset and the experimental results show that our syntax-aware systems can make full use of syntax information in different settings and achieve state-of-the-art performance of KBQA.
Semi-Global Shape-aware Network
Dec 17, 2020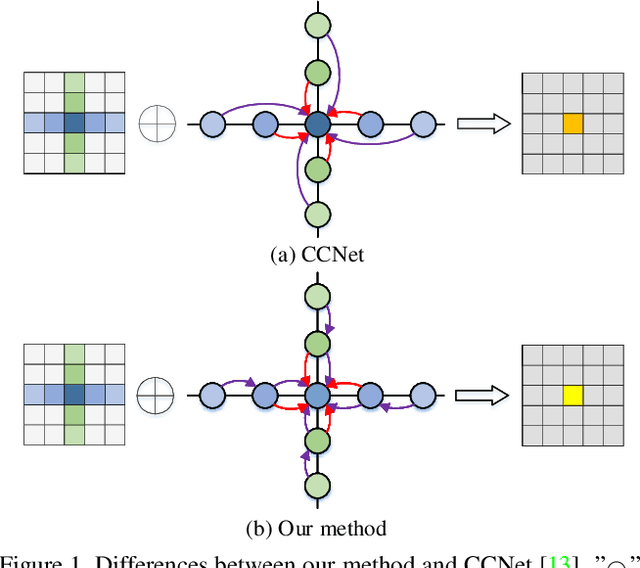

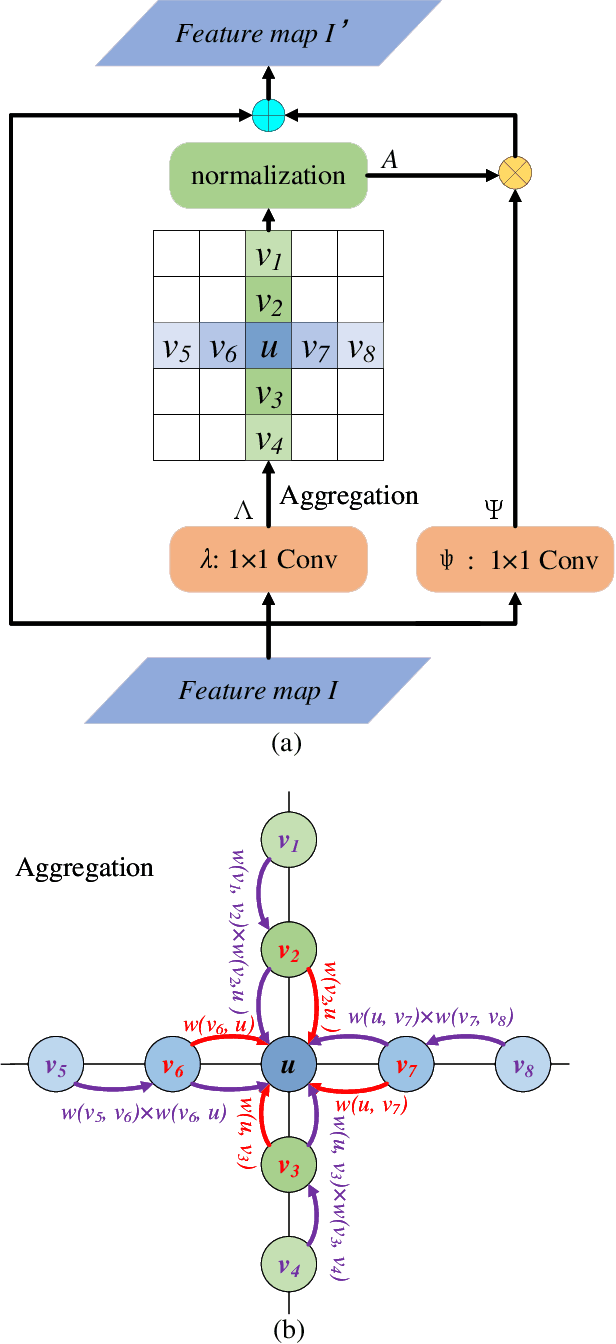
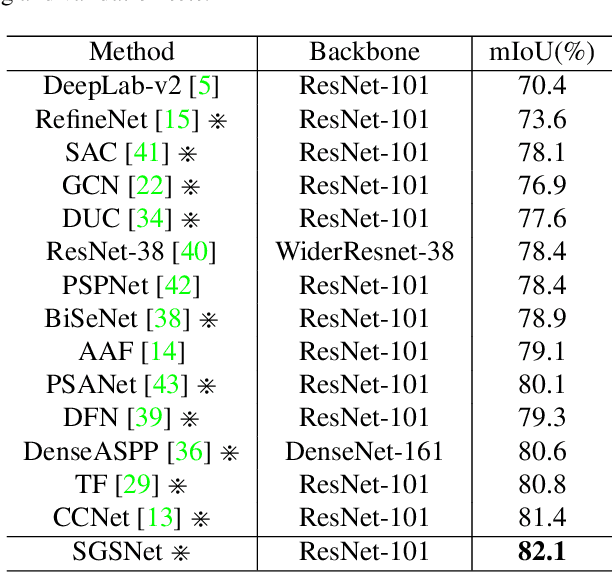
Non-local operations are usually used to capture long-range dependencies via aggregating global context to each position recently. However, most of the methods cannot preserve object shapes since they only focus on feature similarity but ignore proximity between central and other positions for capturing long-range dependencies, while shape-awareness is beneficial to many computer vision tasks. In this paper, we propose a Semi-Global Shape-aware Network (SGSNet) considering both feature similarity and proximity for preserving object shapes when modeling long-range dependencies. A hierarchical way is taken to aggregate global context. In the first level, each position in the whole feature map only aggregates contextual information in vertical and horizontal directions according to both similarity and proximity. And then the result is input into the second level to do the same operations. By this hierarchical way, each central position gains supports from all other positions, and the combination of similarity and proximity makes each position gain supports mostly from the same semantic object. Moreover, we also propose a linear time algorithm for the aggregation of contextual information, where each of rows and columns in the feature map is treated as a binary tree to reduce similarity computation cost. Experiments on semantic segmentation and image retrieval show that adding SGSNet to existing networks gains solid improvements on both accuracy and efficiency.
Leveraging Local and Global Descriptors in Parallel to Search Correspondences for Visual Localization
Sep 23, 2020
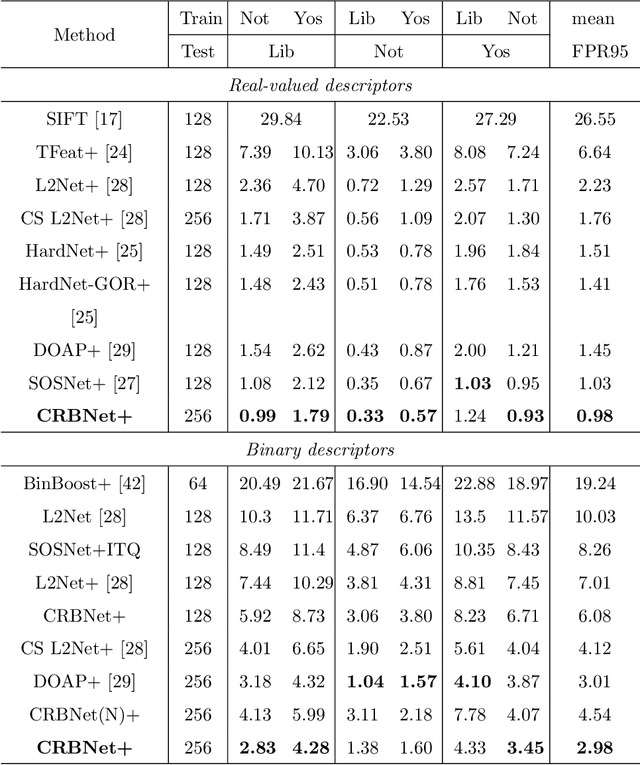
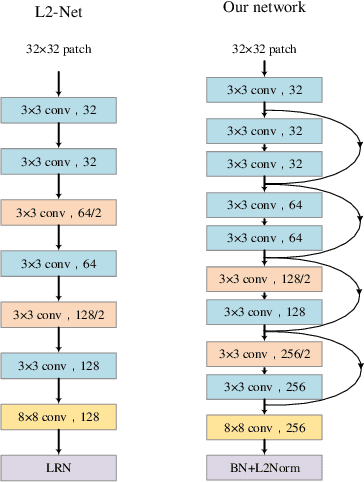
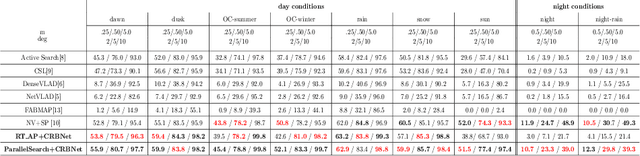
Visual localization to compute 6DoF camera pose from a given image has wide applications such as in robotics, virtual reality, augmented reality, etc. Two kinds of descriptors are important for the visual localization. One is global descriptors that extract the whole feature from each image. The other is local descriptors that extract the local feature from each image patch usually enclosing a key point. More and more methods of the visual localization have two stages: at first to perform image retrieval by global descriptors and then from the retrieval feedback to make 2D-3D point correspondences by local descriptors. The two stages are in serial for most of the methods. This simple combination has not achieved superiority of fusing local and global descriptors. The 3D points obtained from the retrieval feedback are as the nearest neighbor candidates of the 2D image points only by global descriptors. Each of the 2D image points is also called a query local feature when performing the 2D-3D point correspondences. In this paper, we propose a novel parallel search framework, which leverages advantages of both local and global descriptors to get nearest neighbor candidates of a query local feature. Specifically, besides using deep learning based global descriptors, we also utilize local descriptors to construct random tree structures for obtaining nearest neighbor candidates of the query local feature. We propose a new probabilistic model and a new deep learning based local descriptor when constructing the random trees. A weighted Hamming regularization term to keep discriminativeness after binarization is given in the loss function for the proposed local descriptor. The loss function co-trains both real and binary descriptors of which the results are integrated into the random trees.