 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePIS3R: Very Large Parallax Image Stitching via Deep 3D Reconstruction
Aug 06, 2025Image stitching aim to align two images taken from different viewpoints into one seamless, wider image. However, when the 3D scene contains depth variations and the camera baseline is significant, noticeable parallax occurs-meaning the relative positions of scene elements differ substantially between views. Most existing stitching methods struggle to handle such images with large parallax effectively. To address this challenge, in this paper, we propose an image stitching solution called PIS3R that is robust to very large parallax based on the novel concept of deep 3D reconstruction. First, we apply visual geometry grounded transformer to two input images with very large parallax to obtain both intrinsic and extrinsic parameters, as well as the dense 3D scene reconstruction. Subsequently, we reproject reconstructed dense point cloud onto a designated reference view using the recovered camera parameters, achieving pixel-wise alignment and generating an initial stitched image. Finally, to further address potential artifacts such as holes or noise in the initial stitching, we propose a point-conditioned image diffusion module to obtain the refined result.Compared with existing methods, our solution is very large parallax tolerant and also provides results that fully preserve the geometric integrity of all pixels in the 3D photogrammetric context, enabling direct applicability to downstream 3D vision tasks such as SfM. Experimental results demonstrate that the proposed algorithm provides accurate stitching results for images with very large parallax, and outperforms the existing methods qualitatively and quantitatively.
Exploiting Rich Syntax for Better Knowledge Base Question Answering
Jul 16, 2021
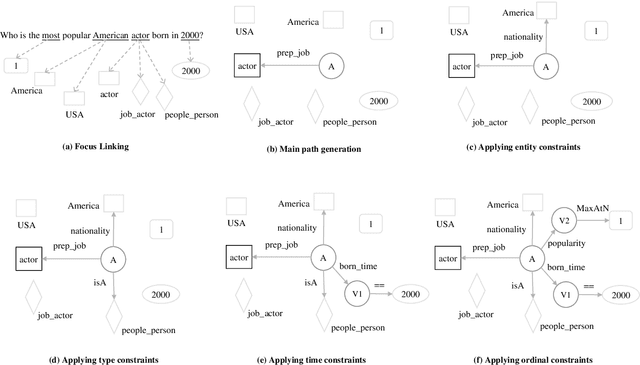
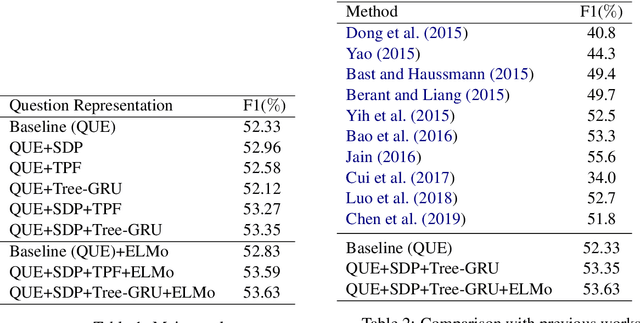

Recent studies on Knowledge Base Question Answering (KBQA) have shown great progress on this task via better question understanding. Previous works for encoding questions mainly focus on the word sequences, but seldom consider the information from syntactic trees.In this paper, we propose an approach to learn syntax-based representations for KBQA. First, we encode path-based syntax by considering the shortest dependency paths between keywords. Then, we propose two encoding strategies to mode the information of whole syntactic trees to obtain tree-based syntax. Finally, we combine both path-based and tree-based syntax representations for KBQA. We conduct extensive experiments on a widely used benchmark dataset and the experimental results show that our syntax-aware systems can make full use of syntax information in different settings and achieve state-of-the-art performance of KBQA.
Improving AMR Parsing with Sequence-to-Sequence Pre-training
Oct 05, 2020

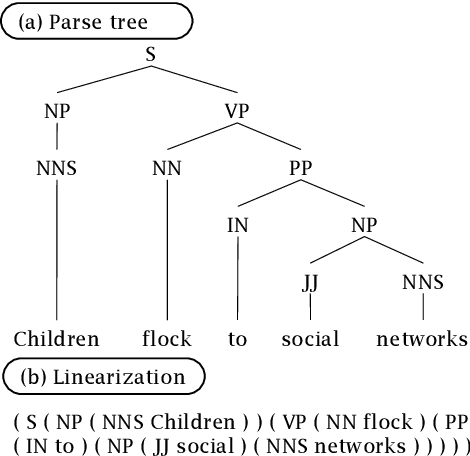

In the literature, the research on abstract meaning representation (AMR) parsing is much restricted by the size of human-curated dataset which is critical to build an AMR parser with good performance. To alleviate such data size restriction, pre-trained models have been drawing more and more attention in AMR parsing. However, previous pre-trained models, like BERT, are implemented for general purpose which may not work as expected for the specific task of AMR parsing. In this paper, we focus on sequence-to-sequence (seq2seq) AMR parsing and propose a seq2seq pre-training approach to build pre-trained models in both single and joint way on three relevant tasks, i.e., machine translation, syntactic parsing, and AMR parsing itself. Moreover, we extend the vanilla fine-tuning method to a multi-task learning fine-tuning method that optimizes for the performance of AMR parsing while endeavors to preserve the response of pre-trained models. Extensive experimental results on two English benchmark datasets show that both the single and joint pre-trained models significantly improve the performance (e.g., from 71.5 to 80.2 on AMR 2.0), which reaches the state of the art. The result is very encouraging since we achieve this with seq2seq models rather than complex models. We make our code and model available at https://github.com/xdqkid/S2S-AMR-Parser.
Coupling Distant Annotation and Adversarial Training for Cross-Domain Chinese Word Segmentation
Jul 16, 2020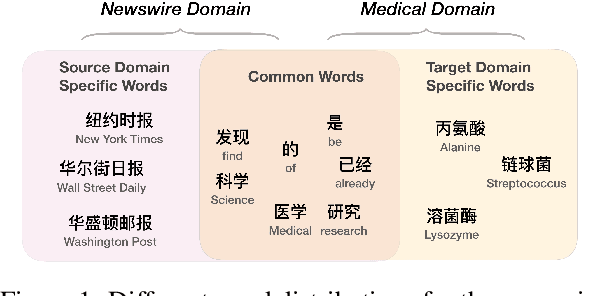

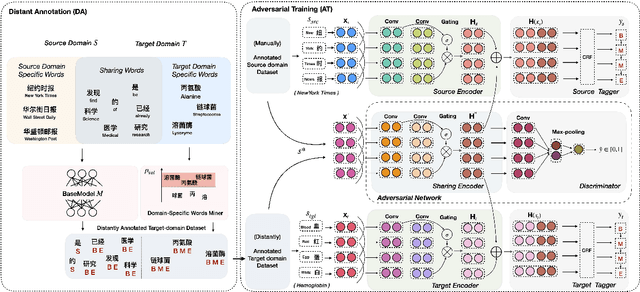

Fully supervised neural approaches have achieved significant progress in the task of Chinese word segmentation (CWS). Nevertheless, the performance of supervised models tends to drop dramatically when they are applied to out-of-domain data. Performance degradation is caused by the distribution gap across domains and the out of vocabulary (OOV) problem. In order to simultaneously alleviate these two issues, this paper proposes to couple distant annotation and adversarial training for cross-domain CWS. For distant annotation, we rethink the essence of "Chinese words" and design an automatic distant annotation mechanism that does not need any supervision or pre-defined dictionaries from the target domain. The approach could effectively explore domain-specific words and distantly annotate the raw texts for the target domain. For adversarial training, we develop a sentence-level training procedure to perform noise reduction and maximum utilization of the source domain information. Experiments on multiple real-world datasets across various domains show the superiority and robustness of our model, significantly outperforming previous state-of-the-art cross-domain CWS methods.
Modeling Graph Structure in Transformer for Better AMR-to-Text Generation
Aug 31, 2019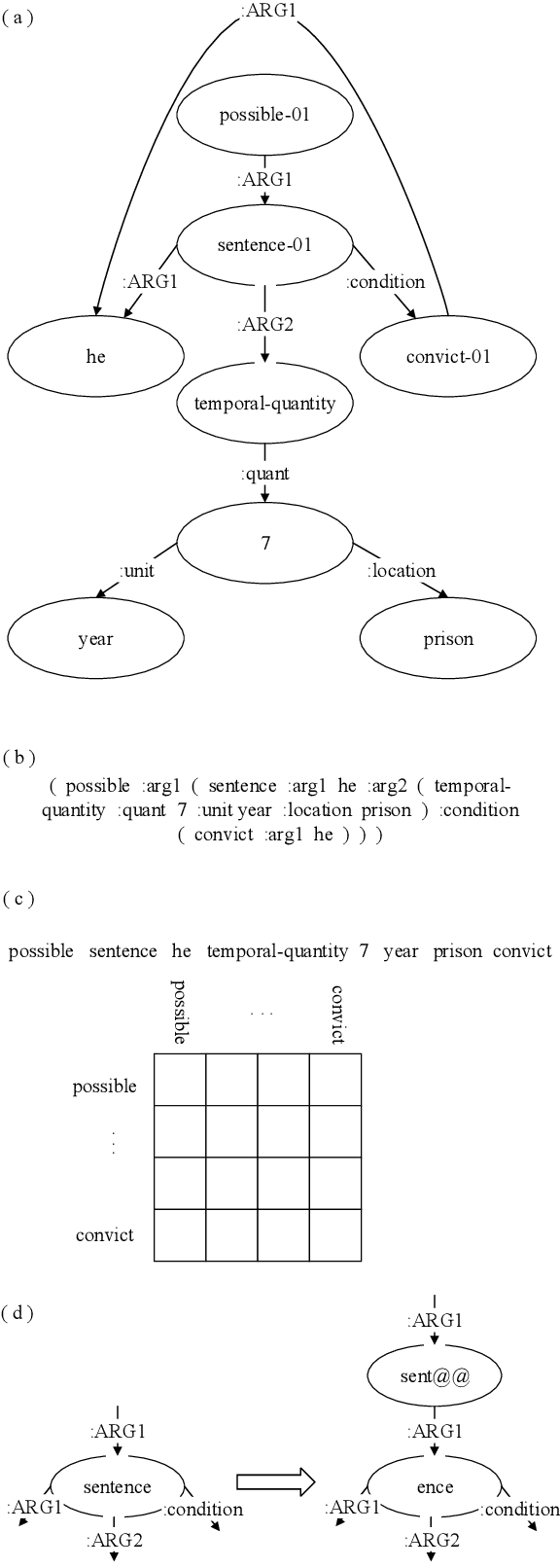



Recent studies on AMR-to-text generation often formalize the task as a sequence-to-sequence (seq2seq) learning problem by converting an Abstract Meaning Representation (AMR) graph into a word sequence. Graph structures are further modeled into the seq2seq framework in order to utilize the structural information in the AMR graphs. However, previous approaches only consider the relations between directly connected concepts while ignoring the rich structure in AMR graphs. In this paper we eliminate such a strong limitation and propose a novel structure-aware self-attention approach to better modeling the relations between indirectly connected concepts in the state-of-the-art seq2seq model, i.e., the Transformer. In particular, a few different methods are explored to learn structural representations between two concepts. Experimental results on English AMR benchmark datasets show that our approach significantly outperforms the state of the art with 29.66 and 31.82 BLEU scores on LDC2015E86 and LDC2017T10, respectively. To the best of our knowledge, these are the best results achieved so far by supervised models on the benchmarks.
Learning When to Attend for Neural Machine Translation
May 31, 2017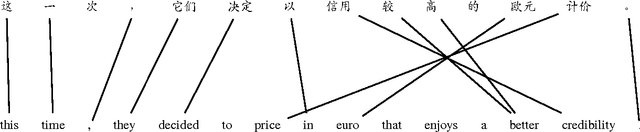



In the past few years, attention mechanisms have become an indispensable component of end-to-end neural machine translation models. However, previous attention models always refer to some source words when predicting a target word, which contradicts with the fact that some target words have no corresponding source words. Motivated by this observation, we propose a novel attention model that has the capability of determining when a decoder should attend to source words and when it should not. Experimental results on NIST Chinese-English translation tasks show that the new model achieves an improvement of 0.8 BLEU score over a state-of-the-art baseline.
Modeling Source Syntax for Neural Machine Translation
May 02, 2017



Even though a linguistics-free sequence to sequence model in neural machine translation (NMT) has certain capability of implicitly learning syntactic information of source sentences, this paper shows that source syntax can be explicitly incorporated into NMT effectively to provide further improvements. Specifically, we linearize parse trees of source sentences to obtain structural label sequences. On the basis, we propose three different sorts of encoders to incorporate source syntax into NMT: 1) Parallel RNN encoder that learns word and label annotation vectors parallelly; 2) Hierarchical RNN encoder that learns word and label annotation vectors in a two-level hierarchy; and 3) Mixed RNN encoder that stitchingly learns word and label annotation vectors over sequences where words and labels are mixed. Experimentation on Chinese-to-English translation demonstrates that all the three proposed syntactic encoders are able to improve translation accuracy. It is interesting to note that the simplest RNN encoder, i.e., Mixed RNN encoder yields the best performance with an significant improvement of 1.4 BLEU points. Moreover, an in-depth analysis from several perspectives is provided to reveal how source syntax benefits NMT.