 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCORE-Bench: A Comprehensive Benchmark for Code Retrieval in the Era of Agentic Coding
Jun 10, 2026Code retrieval is becoming central to coding agents, but agentic coding requires more than matching a natural-language query to an isolated snippet. Given a user request, a coding agent needs to navigate a concrete repository state, locate relevant files and functions, gather supporting context, and filter similar in-repository distractors. Existing code retrieval benchmarks mainly evaluate docstring-to-function or snippet-level matching, thereby missing this requirement-driven repository search problem. To address this gap, we introduce CORE-Bench, a comprehensive benchmark for code retrieval in the era of agentic coding. CORE-Bench evaluates code retrieval ability at three levels: code understanding, issue-to-edit localization, and broader context retrieval. Built from curated code-search tasks and SWE-bench-series instances, CORE-Bench contains over 180K queries and 106K broader-context relevance labels. Experiments with representative embedding models show a sharp drop from traditional code search to code retrieval in agentic coding settings. Simple supervised fine-tuning of existing embedding models significantly improves performance in this setting, suggesting substantial room for further progress.
LaSER: Internalizing Explicit Reasoning into Latent Space for Dense Retrieval
Mar 02, 2026LLMs have fundamentally transformed dense retrieval, upgrading backbones from discriminative encoders to generative architectures. However, a critical disconnect remains: while LLMs possess strong reasoning capabilities, current retrievers predominantly utilize them as static encoders, leaving their potential for complex reasoning unexplored. To address this, existing approaches typically adopt rewrite-then-retrieve pipelines to generate explicit CoT rationales before retrieval. However, this incurs prohibitive latency. In this paper, we propose LaSER, a novel self-distillation framework that internalizes explicit reasoning into the latent space of dense retrievers. Operating on a shared LLM backbone, LaSER introduces a dual-view training mechanism: an Explicit view that explicitly encodes ground-truth reasoning paths, and a Latent view that performs implicit latent thinking. To bridge the gap between these views, we design a multi-grained alignment strategy. Beyond standard output alignment, we introduce a trajectory alignment mechanism that synchronizes the intermediate latent states of the latent path with the semantic progression of the explicit reasoning segments. This allows the retriever to think silently and effectively without autoregressive text generation. Extensive experiments on both in-domain and out-of-domain reasoning-intensive benchmarks demonstrate that LaSER significantly outperforms state-of-the-art baselines. Furthermore, analyses across diverse backbones and model scales validate the robustness of our approach, confirming that our unified learning framework is essential for eliciting effective latent thinking. Our method successfully combines the reasoning depth of explicit CoT pipelines with the inference efficiency of standard dense retrievers.
DiffuRank: Effective Document Reranking with Diffusion Language Models
Feb 13, 2026Recent advances in large language models (LLMs) have inspired new paradigms for document reranking. While this paradigm better exploits the reasoning and contextual understanding capabilities of LLMs, most existing LLM-based rerankers rely on autoregressive generation, which limits their efficiency and flexibility. In particular, token-by-token decoding incurs high latency, while the fixed left-to-right generation order causes early prediction errors to propagate and is difficult to revise. To address these limitations, we explore the use of diffusion language models (dLLMs) for document reranking and propose DiffuRank, a reranking framework built upon dLLMs. Unlike autoregressive models, dLLMs support more flexible decoding and generation processes that are not constrained to a left-to-right order, and enable parallel decoding, which may lead to improved efficiency and controllability. Specifically, we investigate three reranking strategies based on dLLMs: (1) a pointwise approach that uses dLLMs to estimate the relevance of each query-document pair; (2) a logit-based listwise approach that prompts dLLMs to jointly assess the relevance of multiple documents and derives ranking lists directly from model logits; and (3) a permutation-based listwise approach that adapts the canonical decoding process of dLLMs to the reranking tasks. For each approach, we design corresponding training methods to fully exploit the advantages of dLLMs. We evaluate both zero-shot and fine-tuned reranking performance on multiple benchmarks. Experimental results show that dLLMs achieve performance comparable to, and in some cases exceeding, that of autoregressive LLMs with similar model sizes. These findings demonstrate the promise of diffusion-based language models as a compelling alternative to autoregressive architectures for document reranking.
Rethinking Composed Image Retrieval Evaluation: A Fine-Grained Benchmark from Image Editing
Jan 22, 2026Composed Image Retrieval (CIR) is a pivotal and complex task in multimodal understanding. Current CIR benchmarks typically feature limited query categories and fail to capture the diverse requirements of real-world scenarios. To bridge this evaluation gap, we leverage image editing to achieve precise control over modification types and content, enabling a pipeline for synthesizing queries across a broad spectrum of categories. Using this pipeline, we construct EDIR, a novel fine-grained CIR benchmark. EDIR encompasses 5,000 high-quality queries structured across five main categories and fifteen subcategories. Our comprehensive evaluation of 13 multimodal embedding models reveals a significant capability gap; even state-of-the-art models (e.g., RzenEmbed and GME) struggle to perform consistently across all subcategories, highlighting the rigorous nature of our benchmark. Through comparative analysis, we further uncover inherent limitations in existing benchmarks, such as modality biases and insufficient categorical coverage. Furthermore, an in-domain training experiment demonstrates the feasibility of our benchmark. This experiment clarifies the task challenges by distinguishing between categories that are solvable with targeted data and those that expose intrinsic limitations of current model architectures.
Qwen3-VL-Embedding and Qwen3-VL-Reranker: A Unified Framework for State-of-the-Art Multimodal Retrieval and Ranking
Jan 08, 2026In this report, we introduce the Qwen3-VL-Embedding and Qwen3-VL-Reranker model series, the latest extensions of the Qwen family built on the Qwen3-VL foundation model. Together, they provide an end-to-end pipeline for high-precision multimodal search by mapping diverse modalities, including text, images, document images, and video, into a unified representation space. The Qwen3-VL-Embedding model employs a multi-stage training paradigm, progressing from large-scale contrastive pre-training to reranking model distillation, to generate semantically rich high-dimensional vectors. It supports Matryoshka Representation Learning, enabling flexible embedding dimensions, and handles inputs up to 32k tokens. Complementing this, Qwen3-VL-Reranker performs fine-grained relevance estimation for query-document pairs using a cross-encoder architecture with cross-attention mechanisms. Both model series inherit the multilingual capabilities of Qwen3-VL, supporting more than 30 languages, and are released in $\textbf{2B}$ and $\textbf{8B}$ parameter sizes to accommodate diverse deployment requirements. Empirical evaluations demonstrate that the Qwen3-VL-Embedding series achieves state-of-the-art results across diverse multimodal embedding evaluation benchmarks. Specifically, Qwen3-VL-Embedding-8B attains an overall score of $\textbf{77.8}$ on MMEB-V2, ranking first among all models (as of January 8, 2025). This report presents the architecture, training methodology, and practical capabilities of the series, demonstrating their effectiveness on various multimodal retrieval tasks, including image-text retrieval, visual question answering, and video-text matching.
Towards Universal Video Retrieval: Generalizing Video Embedding via Synthesized Multimodal Pyramid Curriculum
Oct 31, 2025The prevailing video retrieval paradigm is structurally misaligned, as narrow benchmarks incentivize correspondingly limited data and single-task training. Therefore, universal capability is suppressed due to the absence of a diagnostic evaluation that defines and demands multi-dimensional generalization. To break this cycle, we introduce a framework built on the co-design of evaluation, data, and modeling. First, we establish the Universal Video Retrieval Benchmark (UVRB), a suite of 16 datasets designed not only to measure performance but also to diagnose critical capability gaps across tasks and domains. Second, guided by UVRB's diagnostics, we introduce a scalable synthesis workflow that generates 1.55 million high-quality pairs to populate the semantic space required for universality. Finally, we devise the Modality Pyramid, a curriculum that trains our General Video Embedder (GVE) by explicitly leveraging the latent interconnections within our diverse data. Extensive experiments show GVE achieves state-of-the-art zero-shot generalization on UVRB. In particular, our analysis reveals that popular benchmarks are poor predictors of general ability and that partially relevant retrieval is a dominant but overlooked scenario. Overall, our co-designed framework provides a practical path to escape the limited scope and advance toward truly universal video retrieval.
$\text{E}^2\text{Rank}$: Your Text Embedding can Also be an Effective and Efficient Listwise Reranker
Oct 26, 2025Text embedding models serve as a fundamental component in real-world search applications. By mapping queries and documents into a shared embedding space, they deliver competitive retrieval performance with high efficiency. However, their ranking fidelity remains limited compared to dedicated rerankers, especially recent LLM-based listwise rerankers, which capture fine-grained query-document and document-document interactions. In this paper, we propose a simple yet effective unified framework $\text{E}^2\text{Rank}$, means Efficient Embedding-based Ranking (also means Embedding-to-Rank), which extends a single text embedding model to perform both high-quality retrieval and listwise reranking through continued training under a listwise ranking objective, thereby achieving strong effectiveness with remarkable efficiency. By applying cosine similarity between the query and document embeddings as a unified ranking function, the listwise ranking prompt, which is constructed from the original query and its candidate documents, serves as an enhanced query enriched with signals from the top-K documents, akin to pseudo-relevance feedback (PRF) in traditional retrieval models. This design preserves the efficiency and representational quality of the base embedding model while significantly improving its reranking performance. Empirically, $\textrm{E}^2\text{Rank}$ achieves state-of-the-art results on the BEIR reranking benchmark and demonstrates competitive performance on the reasoning-intensive BRIGHT benchmark, with very low reranking latency. We also show that the ranking training process improves embedding performance on the MTEB benchmark. Our findings indicate that a single embedding model can effectively unify retrieval and reranking, offering both computational efficiency and competitive ranking accuracy.
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Jun 05, 2025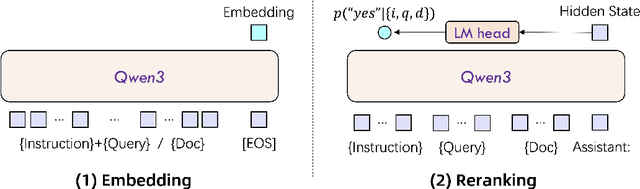
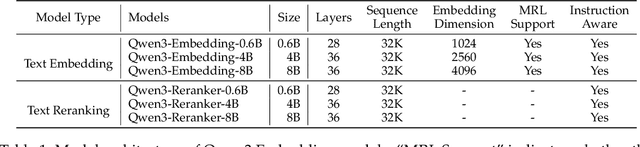

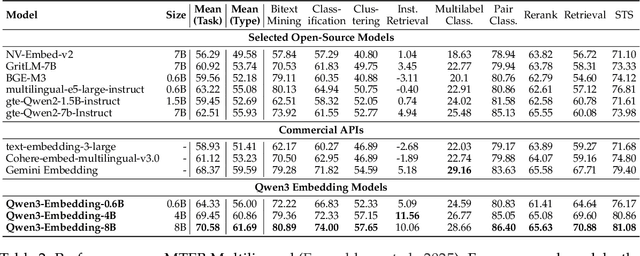
In this work, we introduce the Qwen3 Embedding series, a significant advancement over its predecessor, the GTE-Qwen series, in text embedding and reranking capabilities, built upon the Qwen3 foundation models. Leveraging the Qwen3 LLMs' robust capabilities in multilingual text understanding and generation, our innovative multi-stage training pipeline combines large-scale unsupervised pre-training with supervised fine-tuning on high-quality datasets. Effective model merging strategies further ensure the robustness and adaptability of the Qwen3 Embedding series. During the training process, the Qwen3 LLMs serve not only as backbone models but also play a crucial role in synthesizing high-quality, rich, and diverse training data across multiple domains and languages, thus enhancing the training pipeline. The Qwen3 Embedding series offers a spectrum of model sizes (0.6B, 4B, 8B) for both embedding and reranking tasks, addressing diverse deployment scenarios where users can optimize for either efficiency or effectiveness. Empirical evaluations demonstrate that the Qwen3 Embedding series achieves state-of-the-art results across diverse benchmarks. Notably, it excels on the multilingual evaluation benchmark MTEB for text embedding, as well as in various retrieval tasks, including code retrieval, cross-lingual retrieval and multilingual retrieval. To facilitate reproducibility and promote community-driven research and development, the Qwen3 Embedding models are publicly available under the Apache 2.0 license.
Breaking the Modality Barrier: Universal Embedding Learning with Multimodal LLMs
Apr 24, 2025The Contrastive Language-Image Pre-training (CLIP) framework has become a widely used approach for multimodal representation learning, particularly in image-text retrieval and clustering. However, its efficacy is constrained by three key limitations: (1) text token truncation, (2) isolated image-text encoding, and (3) deficient compositionality due to bag-of-words behavior. While recent Multimodal Large Language Models (MLLMs) have demonstrated significant advances in generalized vision-language understanding, their potential for learning transferable multimodal representations remains underexplored.In this work, we present UniME (Universal Multimodal Embedding), a novel two-stage framework that leverages MLLMs to learn discriminative representations for diverse downstream tasks. In the first stage, we perform textual discriminative knowledge distillation from a powerful LLM-based teacher model to enhance the embedding capability of the MLLM\'s language component. In the second stage, we introduce hard negative enhanced instruction tuning to further advance discriminative representation learning. Specifically, we initially mitigate false negative contamination and then sample multiple hard negatives per instance within each batch, forcing the model to focus on challenging samples. This approach not only improves discriminative power but also enhances instruction-following ability in downstream tasks. We conduct extensive experiments on the MMEB benchmark and multiple retrieval tasks, including short and long caption retrieval and compositional retrieval. Results demonstrate that UniME achieves consistent performance improvement across all tasks, exhibiting superior discriminative and compositional capabilities.
Towards Text-Image Interleaved Retrieval
Feb 18, 2025Current multimodal information retrieval studies mainly focus on single-image inputs, which limits real-world applications involving multiple images and text-image interleaved content. In this work, we introduce the text-image interleaved retrieval (TIIR) task, where the query and document are interleaved text-image sequences, and the model is required to understand the semantics from the interleaved context for effective retrieval. We construct a TIIR benchmark based on naturally interleaved wikiHow tutorials, where a specific pipeline is designed to generate interleaved queries. To explore the task, we adapt several off-the-shelf retrievers and build a dense baseline by interleaved multimodal large language model (MLLM). We then propose a novel Matryoshka Multimodal Embedder (MME), which compresses the number of visual tokens at different granularity, to address the challenge of excessive visual tokens in MLLM-based TIIR models. Experiments demonstrate that simple adaption of existing models does not consistently yield effective results. Our MME achieves significant improvements over the baseline by substantially fewer visual tokens. We provide extensive analysis and will release the dataset and code to facilitate future research.