 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdSum: Two-stream Audio-visual Summarization for Automated Video Advertisement Clipping
Oct 30, 2025Advertisers commonly need multiple versions of the same advertisement (ad) at varying durations for a single campaign. The traditional approach involves manually selecting and re-editing shots from longer video ads to create shorter versions, which is labor-intensive and time-consuming. In this paper, we introduce a framework for automated video ad clipping using video summarization techniques. We are the first to frame video clipping as a shot selection problem, tailored specifically for advertising. Unlike existing general video summarization methods that primarily focus on visual content, our approach emphasizes the critical role of audio in advertising. To achieve this, we develop a two-stream audio-visual fusion model that predicts the importance of video frames, where importance is defined as the likelihood of a frame being selected in the firm-produced short ad. To address the lack of ad-specific datasets, we present AdSum204, a novel dataset comprising 102 pairs of 30-second and 15-second ads from real advertising campaigns. Extensive experiments demonstrate that our model outperforms state-of-the-art methods across various metrics, including Average Precision, Area Under Curve, Spearman, and Kendall.
GME: Improving Universal Multimodal Retrieval by Multimodal LLMs
Dec 22, 2024



Universal Multimodal Retrieval (UMR) aims to enable search across various modalities using a unified model, where queries and candidates can consist of pure text, images, or a combination of both. Previous work has attempted to adopt multimodal large language models (MLLMs) to realize UMR using only text data. However, our preliminary experiments demonstrate that more diverse multimodal training data can further unlock the potential of MLLMs. Despite its effectiveness, the existing multimodal training data is highly imbalanced in terms of modality, which motivates us to develop a training data synthesis pipeline and construct a large-scale, high-quality fused-modal training dataset. Based on the synthetic training data, we develop the General Multimodal Embedder (GME), an MLLM-based dense retriever designed for UMR. Furthermore, we construct a comprehensive UMR Benchmark (UMRB) to evaluate the effectiveness of our approach. Experimental results show that our method achieves state-of-the-art performance among existing UMR methods. Last, we provide in-depth analyses of model scaling, training strategies, and perform ablation studies on both the model and synthetic data.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
mGTE: Generalized Long-Context Text Representation and Reranking Models for Multilingual Text Retrieval
Jul 29, 2024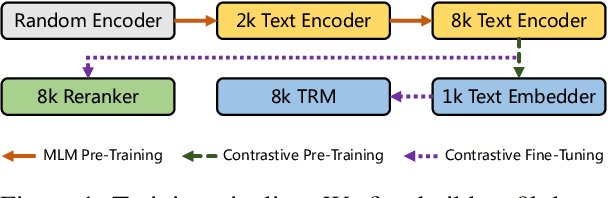

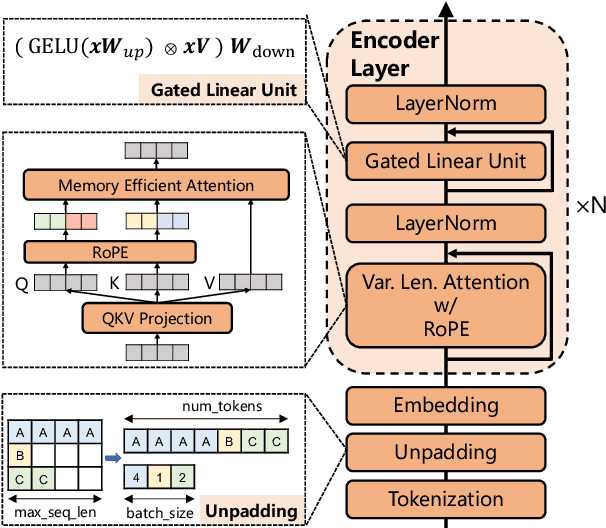
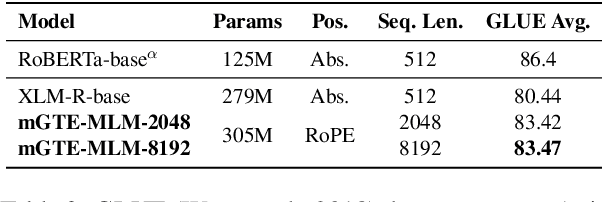
We present systematic efforts in building long-context multilingual text representation model (TRM) and reranker from scratch for text retrieval. We first introduce a text encoder (base size) enhanced with RoPE and unpadding, pre-trained in a native 8192-token context (longer than 512 of previous multilingual encoders). Then we construct a hybrid TRM and a cross-encoder reranker by contrastive learning. Evaluations show that our text encoder outperforms the same-sized previous state-of-the-art XLM-R. Meanwhile, our TRM and reranker match the performance of large-sized state-of-the-art BGE-M3 models and achieve better results on long-context retrieval benchmarks. Further analysis demonstrate that our proposed models exhibit higher efficiency during both training and inference. We believe their efficiency and effectiveness could benefit various researches and industrial applications.
Yi: Open Foundation Models by 01.AI
Mar 07, 2024



We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
KVT: k-NN Attention for Boosting Vision Transformers
May 28, 2021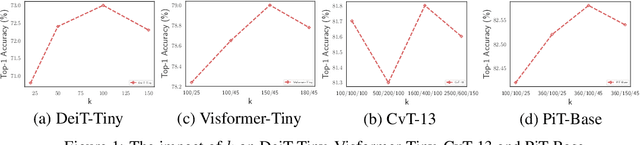
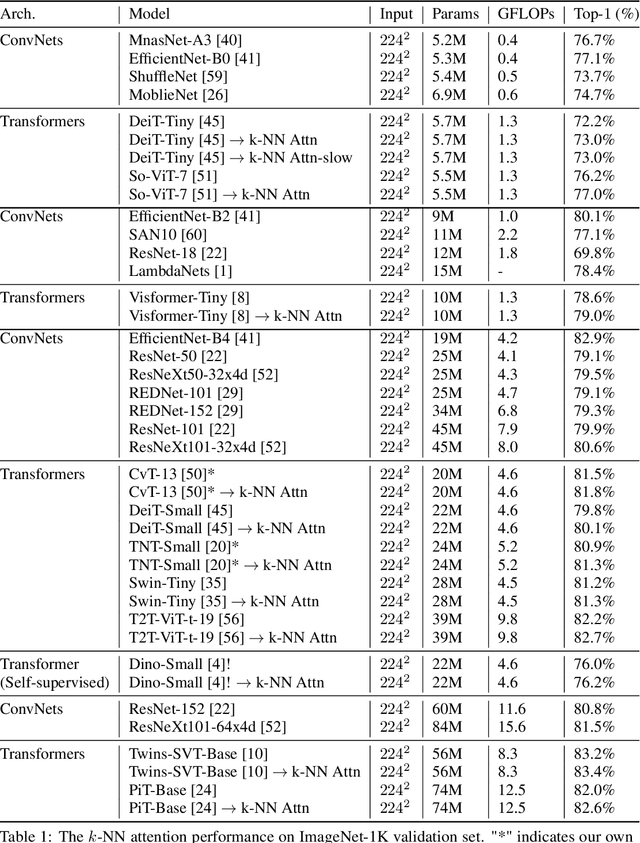
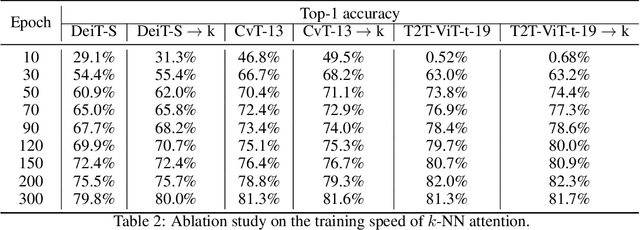
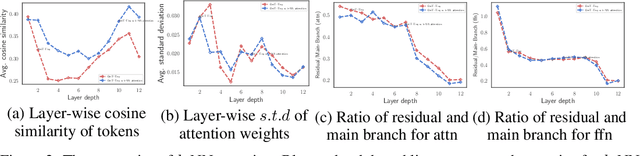
Convolutional Neural Networks (CNNs) have dominated computer vision for years, due to its ability in capturing locality and translation invariance. Recently, many vision transformer architectures have been proposed and they show promising performance. A key component in vision transformers is the fully-connected self-attention which is more powerful than CNNs in modelling long range dependencies. However, since the current dense self-attention uses all image patches (tokens) to compute attention matrix, it may neglect locality of images patches and involve noisy tokens (e.g., clutter background and occlusion), leading to a slow training process and potentially degradation of performance. To address these problems, we propose a sparse attention scheme, dubbed k-NN attention, for boosting vision transformers. Specifically, instead of involving all the tokens for attention matrix calculation, we only select the top-k similar tokens from the keys for each query to compute the attention map. The proposed k-NN attention naturally inherits the local bias of CNNs without introducing convolutional operations, as nearby tokens tend to be more similar than others. In addition, the k-NN attention allows for the exploration of long range correlation and at the same time filter out irrelevant tokens by choosing the most similar tokens from the entire image. Despite its simplicity, we verify, both theoretically and empirically, that $k$-NN attention is powerful in distilling noise from input tokens and in speeding up training. Extensive experiments are conducted by using ten different vision transformer architectures to verify that the proposed k-NN attention can work with any existing transformer architectures to improve its prediction performance.
Multi-Cycle-Consistent Adversarial Networks for Edge Denoising of Computed Tomography Images
Apr 25, 2021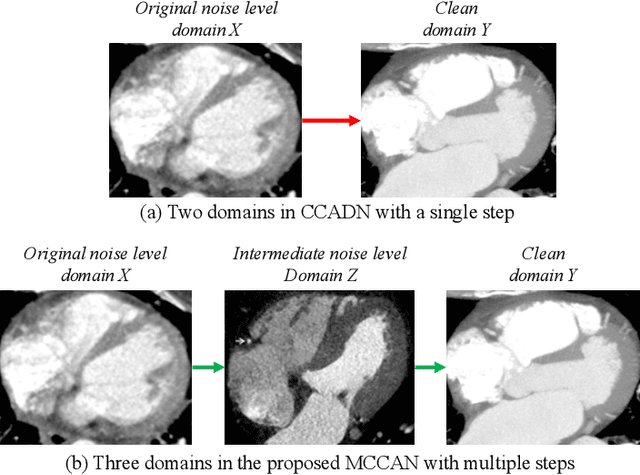

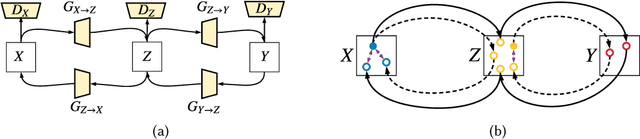
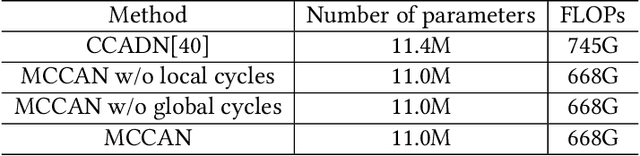
As one of the most commonly ordered imaging tests, computed tomography (CT) scan comes with inevitable radiation exposure that increases the cancer risk to patients. However, CT image quality is directly related to radiation dose, thus it is desirable to obtain high-quality CT images with as little dose as possible. CT image denoising tries to obtain high dose like high-quality CT images (domain X) from low dose low-quality CTimages (domain Y), which can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain X (noisy images) and a target domain Y (clean images). In this paper, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency for edge denoising of CT images. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperformsCCADN in terms of denoising quality with slightly less computation resource consumption.