 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardware-aware Real-time Myocardial Segmentation Quality Control in Contrast Echocardiography
Sep 14, 2021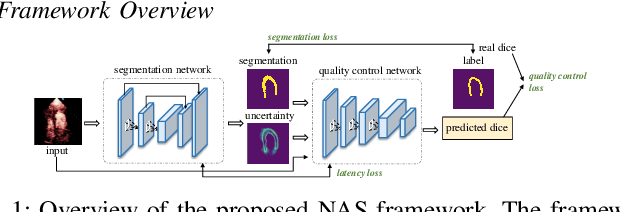
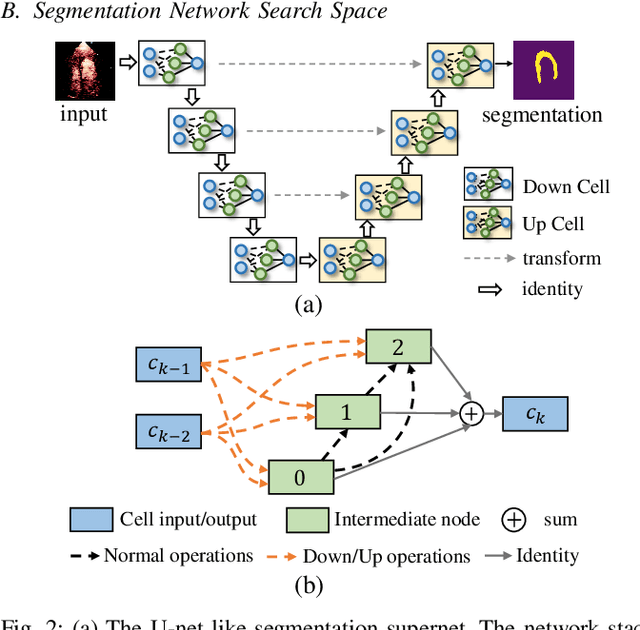
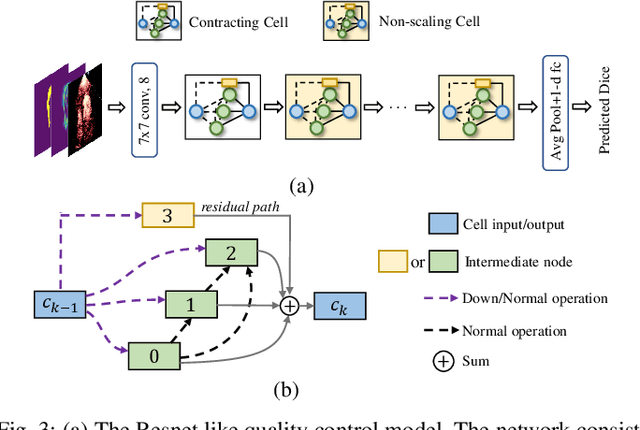
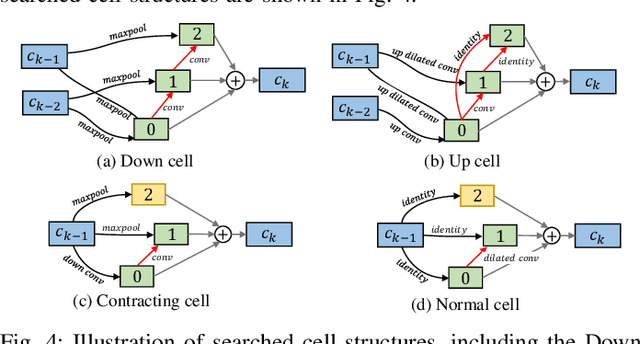
Automatic myocardial segmentation of contrast echocardiography has shown great potential in the quantification of myocardial perfusion parameters. Segmentation quality control is an important step to ensure the accuracy of segmentation results for quality research as well as its clinical application. Usually, the segmentation quality control happens after the data acquisition. At the data acquisition time, the operator could not know the quality of the segmentation results. On-the-fly segmentation quality control could help the operator to adjust the ultrasound probe or retake data if the quality is unsatisfied, which can greatly reduce the effort of time-consuming manual correction. However, it is infeasible to deploy state-of-the-art DNN-based models because the segmentation module and quality control module must fit in the limited hardware resource on the ultrasound machine while satisfying strict latency constraints. In this paper, we propose a hardware-aware neural architecture search framework for automatic myocardial segmentation and quality control of contrast echocardiography. We explicitly incorporate the hardware latency as a regularization term into the loss function during training. The proposed method searches the best neural network architecture for the segmentation module and quality prediction module with strict latency.
Segmentation with Multiple Acceptable Annotations: A Case Study of Myocardial Segmentation in Contrast Echocardiography
Jun 29, 2021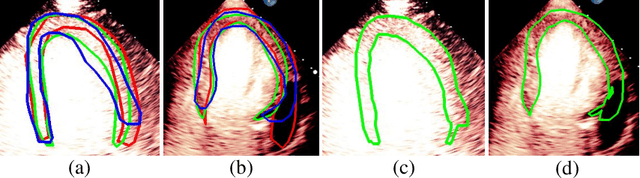
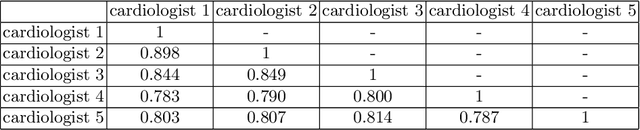
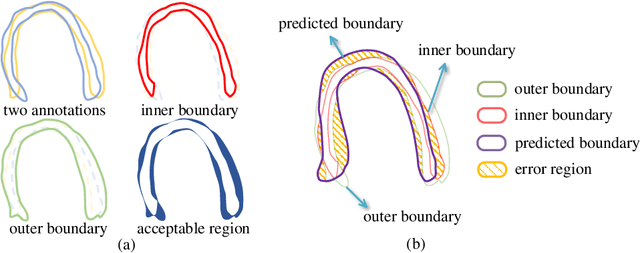
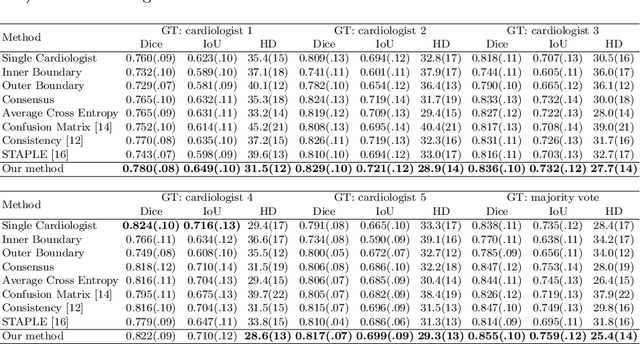
Most existing deep learning-based frameworks for image segmentation assume that a unique ground truth is known and can be used for performance evaluation. This is true for many applications, but not all. Myocardial segmentation of Myocardial Contrast Echocardiography (MCE), a critical task in automatic myocardial perfusion analysis, is an example. Due to the low resolution and serious artifacts in MCE data, annotations from different cardiologists can vary significantly, and it is hard to tell which one is the best. In this case, how can we find a good way to evaluate segmentation performance and how do we train the neural network? In this paper, we address the first problem by proposing a new extended Dice to effectively evaluate the segmentation performance when multiple accepted ground truth is available. Then based on our proposed metric, we solve the second problem by further incorporating the new metric into a loss function that enables neural networks to flexibly learn general features of myocardium. Experiment results on our clinical MCE data set demonstrate that the neural network trained with the proposed loss function outperforms those existing ones that try to obtain a unique ground truth from multiple annotations, both quantitatively and qualitatively. Finally, our grading study shows that using extended Dice as an evaluation metric can better identify segmentation results that need manual correction compared with using Dice.
Multi-Cycle-Consistent Adversarial Networks for Edge Denoising of Computed Tomography Images
Apr 25, 2021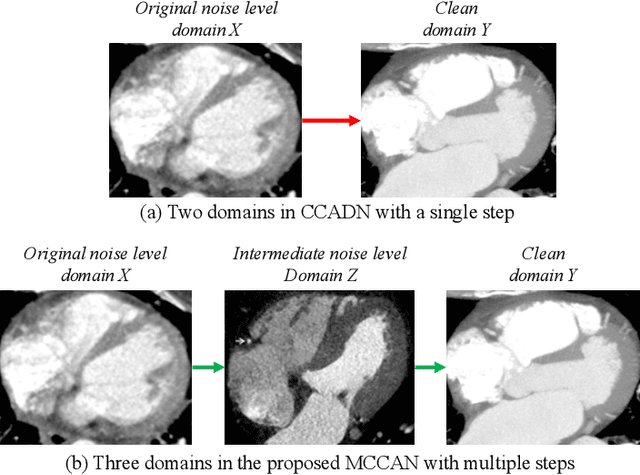

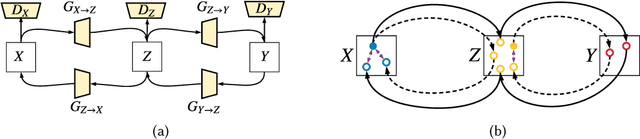
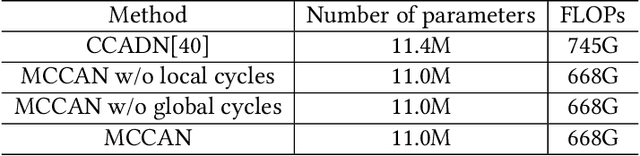
As one of the most commonly ordered imaging tests, computed tomography (CT) scan comes with inevitable radiation exposure that increases the cancer risk to patients. However, CT image quality is directly related to radiation dose, thus it is desirable to obtain high-quality CT images with as little dose as possible. CT image denoising tries to obtain high dose like high-quality CT images (domain X) from low dose low-quality CTimages (domain Y), which can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain X (noisy images) and a target domain Y (clean images). In this paper, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency for edge denoising of CT images. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperformsCCADN in terms of denoising quality with slightly less computation resource consumption.
Improving the Reconstruction of Disentangled Representation Learners via Multi-Stage Modelling
Oct 25, 2020

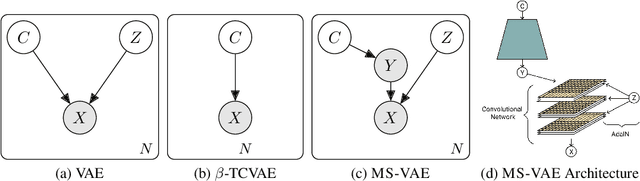

Current autoencoder-based disentangled representation learning methods achieve disentanglement by penalizing the (aggregate) posterior to encourage statistical independence of the latent factors. This approach introduces a trade-off between disentangled representation learning and reconstruction quality since the model does not have enough capacity to learn correlated latent variables that capture detail information present in most image data. To overcome this trade-off, we present a novel multi-stage modelling approach where the disentangled factors are first learned using a preexisting disentangled representation learning method (such as $\beta$-TCVAE); then, the low-quality reconstruction is improved with another deep generative model that is trained to model the missing correlated latent variables, adding detail information while maintaining conditioning on the previously learned disentangled factors. Taken together, our multi-stage modelling approach results in a single, coherent probabilistic model that is theoretically justified by the principal of D-separation and can be realized with a variety of model classes including likelihood-based models such as variational autoencoders, implicit models such as generative adversarial networks, and tractable models like normalizing flows or mixtures of Gaussians. We demonstrate that our multi-stage model has much higher reconstruction quality than current state-of-the-art methods with equivalent disentanglement performance across multiple standard benchmarks.
Multi-Cycle-Consistent Adversarial Networks for CT Image Denoising
Feb 27, 2020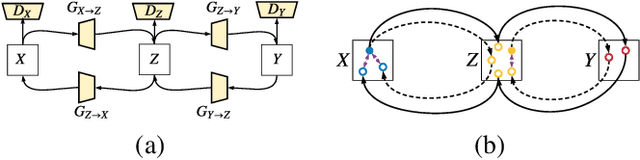
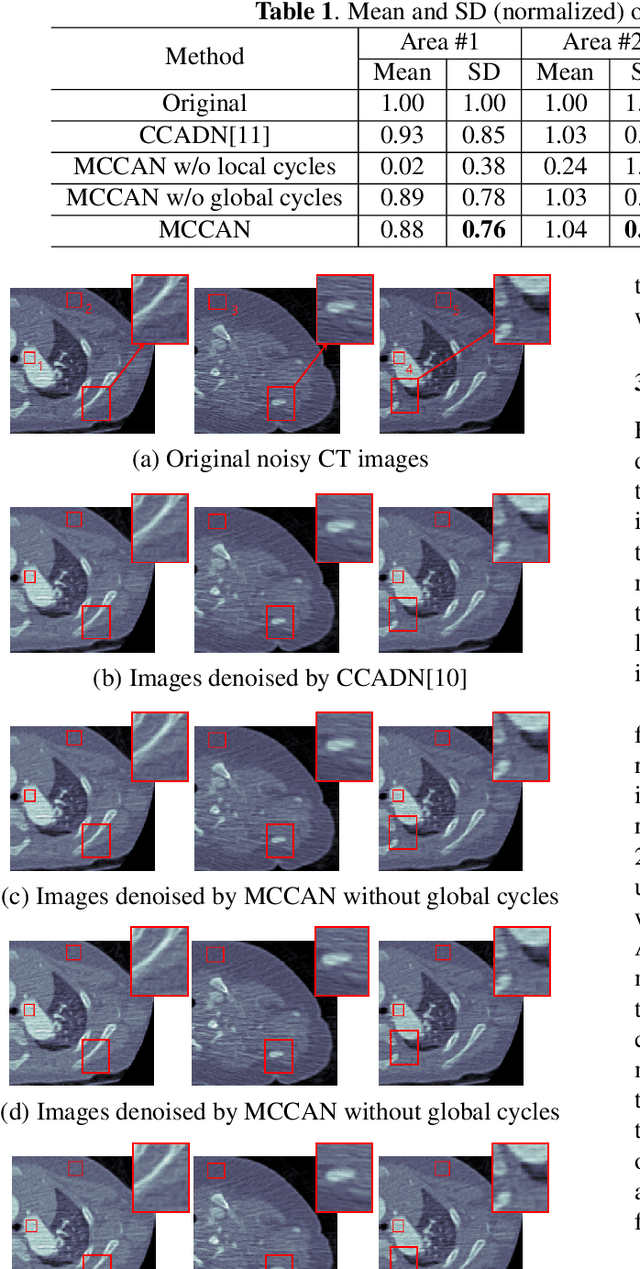
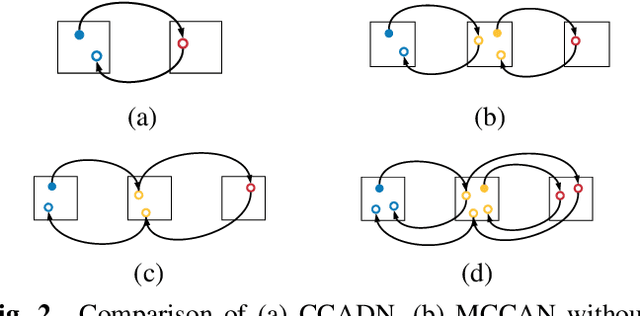
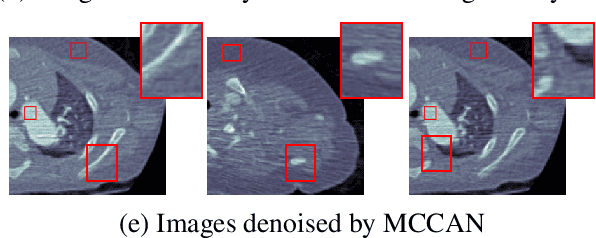
CT image denoising can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain $X$ (noisy images) and a target domain $Y$ (clean images). Recently, cycle-consistent adversarial denoising network (CCADN) has achieved state-of-the-art results by enforcing cycle-consistent loss without the need of paired training data. Our detailed analysis of CCADN raises a number of interesting questions. For example, if the noise is large leading to significant difference between domain $X$ and domain $Y$, can we bridge $X$ and $Y$ with an intermediate domain $Z$ such that both the denoising process between $X$ and $Z$ and that between $Z$ and $Y$ are easier to learn? As such intermediate domains lead to multiple cycles, how do we best enforce cycle-consistency? Driven by these questions, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperforms the state-of-the-art.
Real-Time Boiler Control Optimization with Machine Learning
Mar 07, 2019
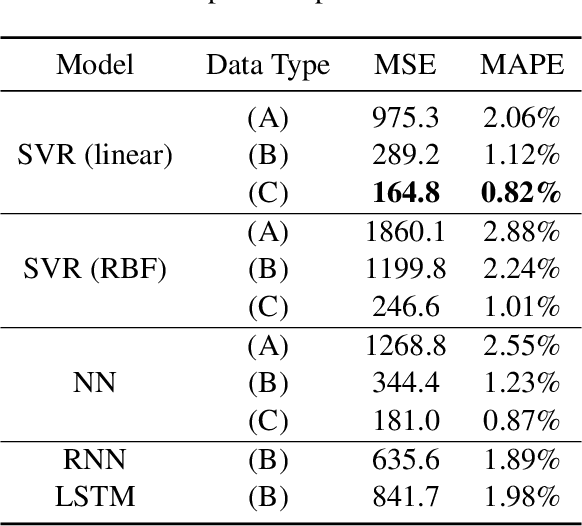
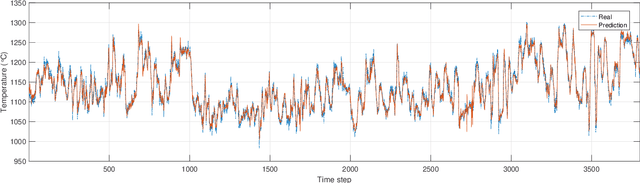
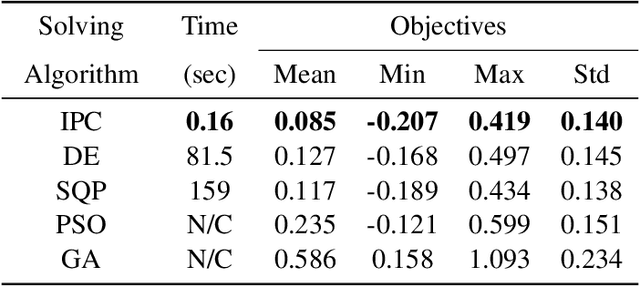
In coal-fired power plants, it is critical to improve the operational efficiency of boilers for sustainability. In this work, we formulate real-time boiler control as an optimization problem that looks for the best distribution of temperature in different zones and oxygen content from the flue to improve the boiler's stability and energy efficiency. We employ an efficient algorithm by integrating appropriate machine learning and optimization techniques. We obtain a large dataset collected from a real boiler for more than two months from our industry partner, and conduct extensive experiments to demonstrate the effectiveness and efficiency of the proposed algorithm.
Evaluation of Neural Network Uncertainty Estimation with Application to Resource-Constrained Platforms
Mar 05, 2019
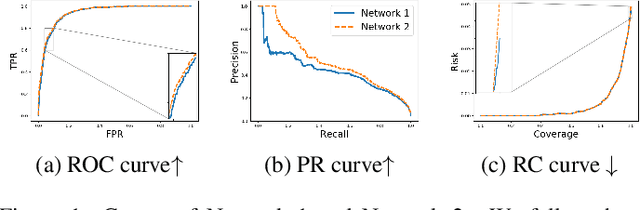
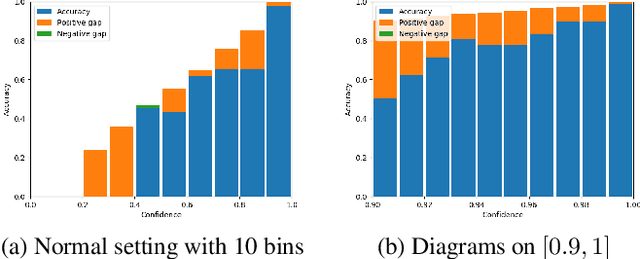
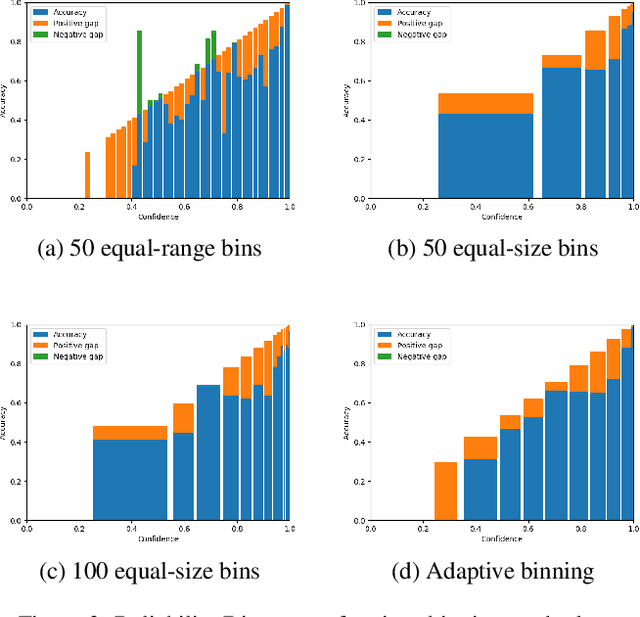
The ability to accurately estimate uncertainties in neural network predictions is of great importance in many critical tasks. In this paper, we first analyze the intrinsic relation between two main use cases of uncertainty estimation, i.e., selective prediction and confidence calibration. We then reveal the potential issues with the existing quality metrics for uncertainty estimation and propose new metrics to mitigate them. Finally, we apply these new metrics to resource-constrained platforms such as autonomous driver assistance systems where the quality of uncertainty estimation is critical. By exploring the trade-off between the model size and the estimation quality, a missing piece in the literature, some interesting trends are observed.
On the Universal Approximability and Complexity Bounds of Quantized ReLU Neural Networks
Sep 27, 2018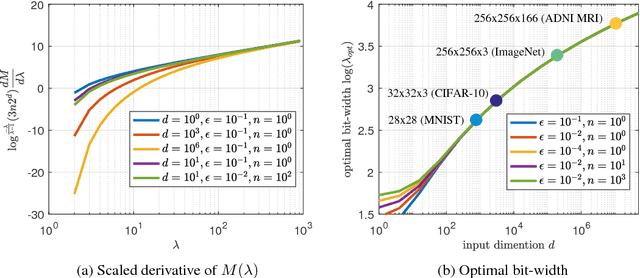


Compression is a key step to deploy large neural networks on resource-constrained platforms. As a popular compression technique, quantization constrains the number of distinct weight values and thus reducing the number of bits required to represent and store each weight. In this paper, we study the representation power of quantized neural networks. First, we prove the universal approximability of quantized ReLU networks on a wide class of functions. Then we provide upper bounds on the number of weights and the memory size for a given approximation error bound and the bit-width of weights for function-independent and function-dependent structures. Our results reveal that, to attain an approximation error bound of $\epsilon$, the number of weights needed by a quantized network is no more than $\mathcal{O}\left(\log^5(1/\epsilon)\right)$ times that of an unquantized network. This overhead is of much lower order than the lower bound of the number of weights needed for the error bound, supporting the empirical success of various quantization techniques. To the best of our knowledge, this is the first in-depth study on the complexity bounds of quantized neural networks.
PBGen: Partial Binarization of Deconvolution-Based Generators for Edge Intelligence
Mar 21, 2018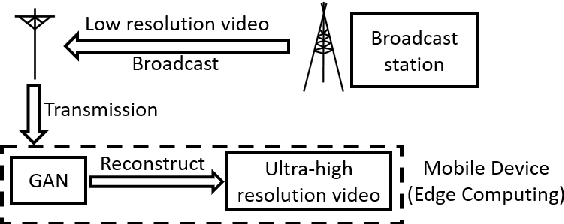


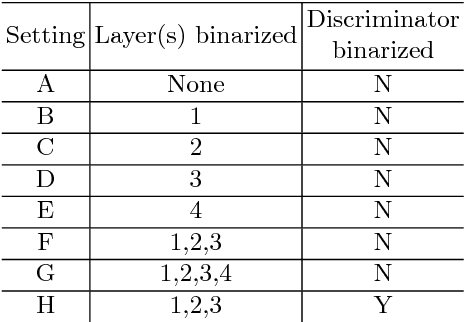
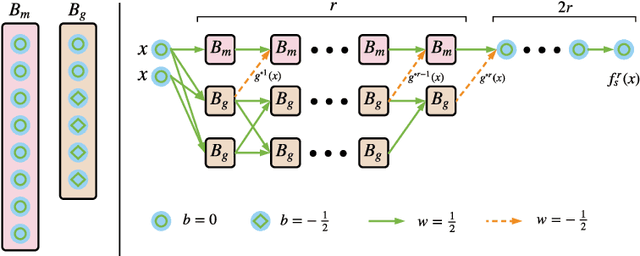
This work explores the binarization of the deconvolution-based generator in a GAN for memory saving and speedup of image construction. Our study suggests that different from convolutional neural networks (including the discriminator) where all layers can be binarized, only some of the layers in the generator can be binarized without significant performance loss. Supported by theoretical analysis and verified by experiments, a direct metric based on the dimension of deconvolution operations is established, which can be used to quickly decide which layers in the generator can be binarized. Our results also indicate that both the generator and the discriminator should be binarized simultaneously for balanced competition and better performance. Experimental results based on CelebA suggest that directly applying state-of-the-art binarization techniques to all the layers of the generator will lead to 2.83$\times$ performance loss measured by sliced Wasserstein distance compared with the original generator, while applying them to selected layers only can yield up to 25.81$\times$ saving in memory consumption, and 1.96$\times$ and 1.32$\times$ speedup in inference and training respectively with little performance loss.