 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChannel-Wise Mixed-Precision Quantization for Large Language Models
Oct 16, 2024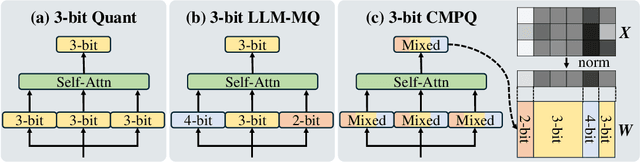
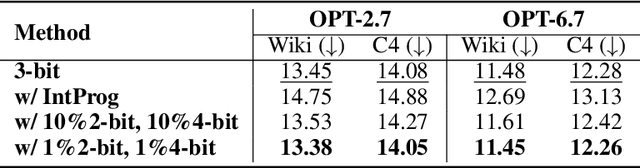
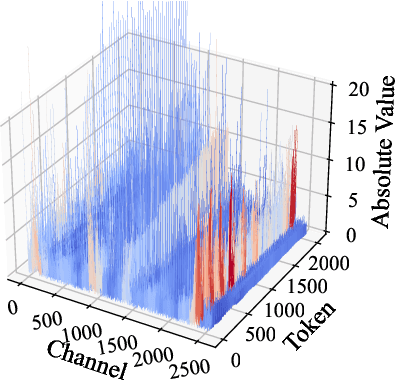
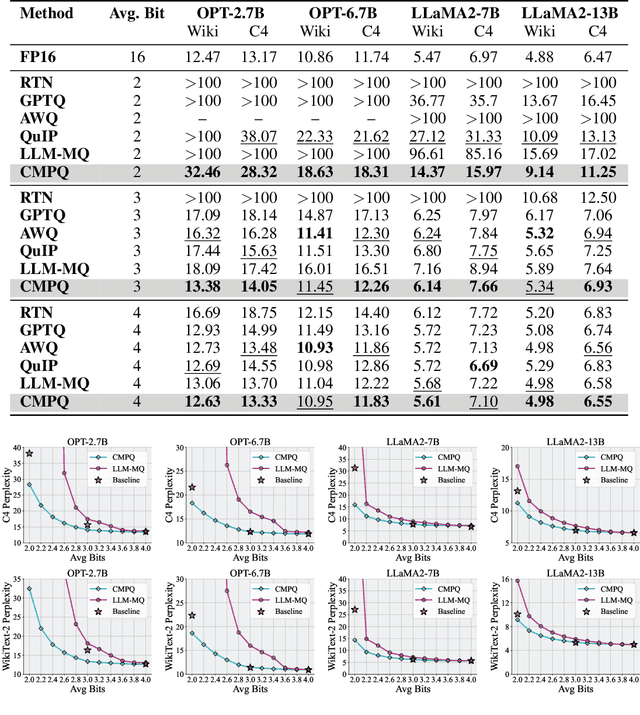
Large Language Models (LLMs) have demonstrated remarkable success across a wide range of language tasks, but their deployment on edge devices remains challenging due to the substantial memory requirements imposed by their large parameter sizes. Weight-only quantization presents a promising solution to reduce the memory footprint of LLMs. However, existing approaches primarily focus on integer-bit quantization, limiting their adaptability to fractional-bit quantization tasks and preventing the full utilization of available storage space on devices. In this paper, we introduce Channel-Wise Mixed-Precision Quantization (CMPQ), a novel mixed-precision quantization method that allocates quantization precision in a channel-wise pattern based on activation distributions. By assigning different precision levels to different weight channels, CMPQ can adapt to any bit-width constraint. CMPQ employs a non-uniform quantization strategy and incorporates two outlier extraction techniques that collaboratively preserve the critical information, thereby minimizing the quantization loss. Experiments on different sizes of LLMs demonstrate that CMPQ not only enhances performance in integer-bit quantization tasks but also achieves significant performance gains with a modest increase in memory usage. CMPQ thus represents an adaptive and effective approach to LLM quantization, offering substantial benefits across diverse device capabilities.
Automatic Sparse Connectivity Learning for Neural Networks
Jan 13, 2022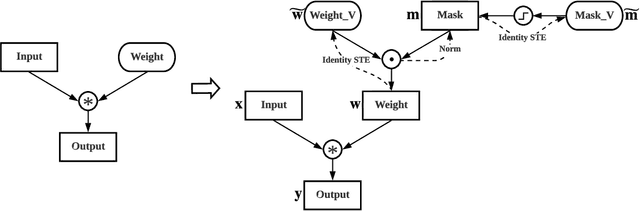

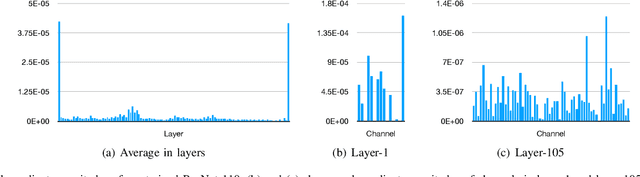
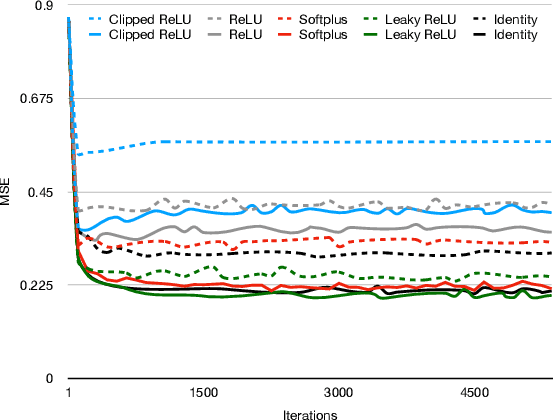
Since sparse neural networks usually contain many zero weights, these unnecessary network connections can potentially be eliminated without degrading network performance. Therefore, well-designed sparse neural networks have the potential to significantly reduce FLOPs and computational resources. In this work, we propose a new automatic pruning method - Sparse Connectivity Learning (SCL). Specifically, a weight is re-parameterized as an element-wise multiplication of a trainable weight variable and a binary mask. Thus, network connectivity is fully described by the binary mask, which is modulated by a unit step function. We theoretically prove the fundamental principle of using a straight-through estimator (STE) for network pruning. This principle is that the proxy gradients of STE should be positive, ensuring that mask variables converge at their minima. After finding Leaky ReLU, Softplus, and Identity STEs can satisfy this principle, we propose to adopt Identity STE in SCL for discrete mask relaxation. We find that mask gradients of different features are very unbalanced, hence, we propose to normalize mask gradients of each feature to optimize mask variable training. In order to automatically train sparse masks, we include the total number of network connections as a regularization term in our objective function. As SCL does not require pruning criteria or hyper-parameters defined by designers for network layers, the network is explored in a larger hypothesis space to achieve optimized sparse connectivity for the best performance. SCL overcomes the limitations of existing automatic pruning methods. Experimental results demonstrate that SCL can automatically learn and select important network connections for various baseline network structures. Deep learning models trained by SCL outperform the SOTA human-designed and automatic pruning methods in sparsity, accuracy, and FLOPs reduction.
Multi-Cycle-Consistent Adversarial Networks for CT Image Denoising
Feb 27, 2020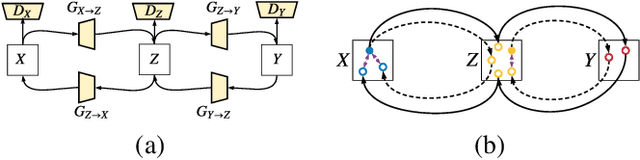
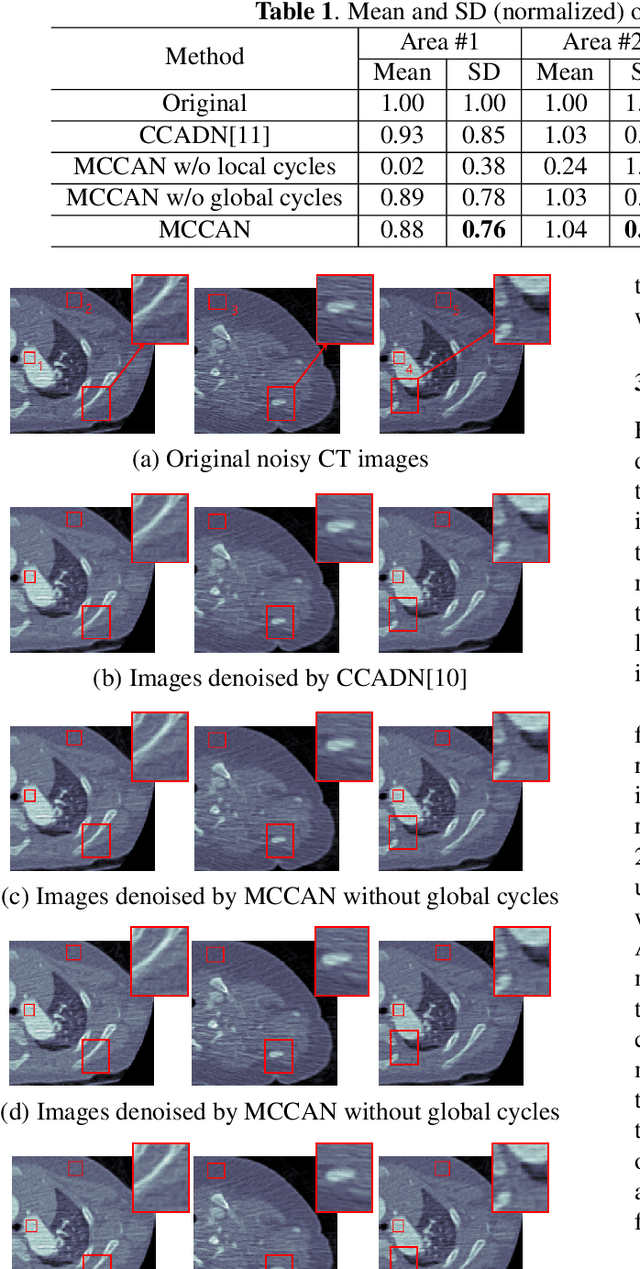
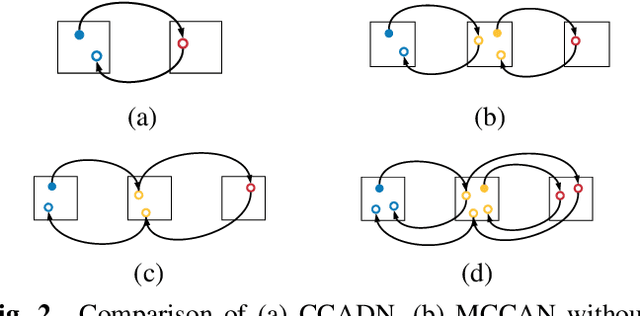
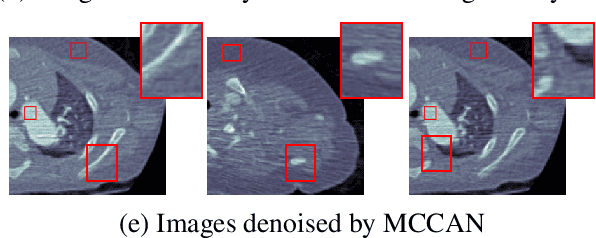
CT image denoising can be treated as an image-to-image translation task where the goal is to learn the transform between a source domain $X$ (noisy images) and a target domain $Y$ (clean images). Recently, cycle-consistent adversarial denoising network (CCADN) has achieved state-of-the-art results by enforcing cycle-consistent loss without the need of paired training data. Our detailed analysis of CCADN raises a number of interesting questions. For example, if the noise is large leading to significant difference between domain $X$ and domain $Y$, can we bridge $X$ and $Y$ with an intermediate domain $Z$ such that both the denoising process between $X$ and $Z$ and that between $Z$ and $Y$ are easier to learn? As such intermediate domains lead to multiple cycles, how do we best enforce cycle-consistency? Driven by these questions, we propose a multi-cycle-consistent adversarial network (MCCAN) that builds intermediate domains and enforces both local and global cycle-consistency. The global cycle-consistency couples all generators together to model the whole denoising process, while the local cycle-consistency imposes effective supervision on the process between adjacent domains. Experiments show that both local and global cycle-consistency are important for the success of MCCAN, which outperforms the state-of-the-art.