 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiHGNN: Leveraging Properties of Semantic Graphs for Efficient HGNN Acceleration
Aug 27, 2024Heterogeneous Graph Neural Networks (HGNNs) have expanded graph representation learning to heterogeneous graph fields. Recent studies have demonstrated their superior performance across various applications, including medical analysis and recommendation systems, often surpassing existing methods. However, GPUs often experience inefficiencies when executing HGNNs due to their unique and complex execution patterns. Compared to traditional Graph Neural Networks, these patterns further exacerbate irregularities in memory access. To tackle these challenges, recent studies have focused on developing domain-specific accelerators for HGNNs. Nonetheless, most of these efforts have concentrated on optimizing the datapath or scheduling data accesses, while largely overlooking the potential benefits that could be gained from leveraging the inherent properties of the semantic graph, such as its topology, layout, and generation. In this work, we focus on leveraging the properties of semantic graphs to enhance HGNN performance. First, we analyze the Semantic Graph Build (SGB) stage and identify significant opportunities for data reuse during semantic graph generation. Next, we uncover the phenomenon of buffer thrashing during the Graph Feature Processing (GFP) stage, revealing potential optimization opportunities in semantic graph layout. Furthermore, we propose a lightweight hardware accelerator frontend for HGNNs, called SiHGNN. This accelerator frontend incorporates a tree-based Semantic Graph Builder for efficient semantic graph generation and features a novel Graph Restructurer for optimizing semantic graph layouts. Experimental results show that SiHGNN enables the state-of-the-art HGNN accelerator to achieve an average performance improvement of 2.95$\times$.
AHPA: Adaptive Horizontal Pod Autoscaling Systems on Alibaba Cloud Container Service for Kubernetes
Mar 07, 2023The existing resource allocation policy for application instances in Kubernetes cannot dynamically adjust according to the requirement of business, which would cause an enormous waste of resources during fluctuations. Moreover, the emergence of new cloud services puts higher resource management requirements. This paper discusses horizontal POD resources management in Alibaba Cloud Container Services with a newly deployed AI algorithm framework named AHPA -- the adaptive horizontal pod auto-scaling system. Based on a robust decomposition forecasting algorithm and performance training model, AHPA offers an optimal pod number adjustment plan that could reduce POD resources and maintain business stability. Since being deployed in April 2021, this system has expanded to multiple customer scenarios, including logistics, social networks, AI audio and video, e-commerce, etc. Compared with the previous algorithms, AHPA solves the elastic lag problem, increasing CPU usage by 10% and reducing resource cost by more than 20%. In addition, AHPA can automatically perform flexible planning according to the predicted business volume without manual intervention, significantly saving operation and maintenance costs.
Automatic Sparse Connectivity Learning for Neural Networks
Jan 13, 2022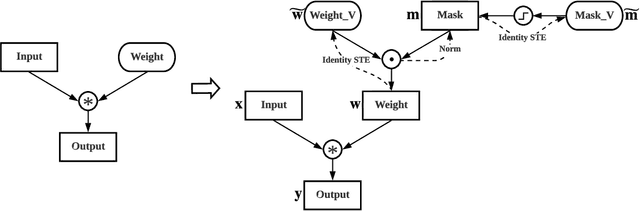

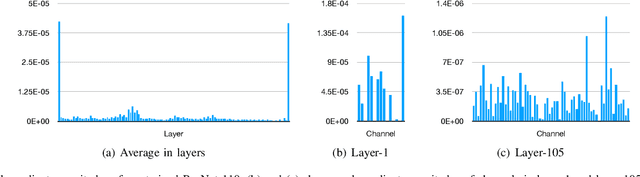
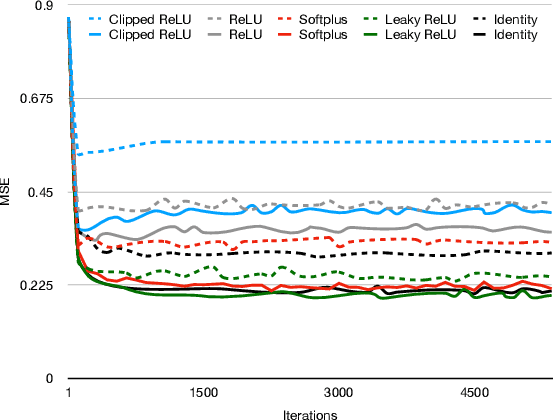
Since sparse neural networks usually contain many zero weights, these unnecessary network connections can potentially be eliminated without degrading network performance. Therefore, well-designed sparse neural networks have the potential to significantly reduce FLOPs and computational resources. In this work, we propose a new automatic pruning method - Sparse Connectivity Learning (SCL). Specifically, a weight is re-parameterized as an element-wise multiplication of a trainable weight variable and a binary mask. Thus, network connectivity is fully described by the binary mask, which is modulated by a unit step function. We theoretically prove the fundamental principle of using a straight-through estimator (STE) for network pruning. This principle is that the proxy gradients of STE should be positive, ensuring that mask variables converge at their minima. After finding Leaky ReLU, Softplus, and Identity STEs can satisfy this principle, we propose to adopt Identity STE in SCL for discrete mask relaxation. We find that mask gradients of different features are very unbalanced, hence, we propose to normalize mask gradients of each feature to optimize mask variable training. In order to automatically train sparse masks, we include the total number of network connections as a regularization term in our objective function. As SCL does not require pruning criteria or hyper-parameters defined by designers for network layers, the network is explored in a larger hypothesis space to achieve optimized sparse connectivity for the best performance. SCL overcomes the limitations of existing automatic pruning methods. Experimental results demonstrate that SCL can automatically learn and select important network connections for various baseline network structures. Deep learning models trained by SCL outperform the SOTA human-designed and automatic pruning methods in sparsity, accuracy, and FLOPs reduction.
Video Face Recognition System: RetinaFace-mnet-faster and Secondary Search
Sep 29, 2020

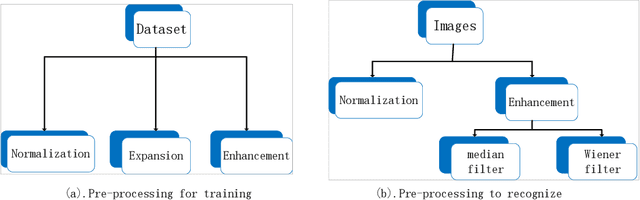

Face recognition is widely used in the scene. However, different visual environments require different methods, and face recognition has a difficulty in complex environments. Therefore, this paper mainly experiments complex faces in the video. First, we design an image pre-processing module for fuzzy scene or under-exposed faces to enhance images. Our experimental results demonstrate that effective images pre-processing improves the accuracy of 0.11%, 0.2% and 1.4% on LFW, WIDER FACE and our datasets, respectively. Second, we propose RetinacFace-mnet-faster for detection and a confidence threshold specification for face recognition, reducing the lost rate. Our experimental results show that our RetinaFace-mnet-faster for 640*480 resolution on the Tesla P40 and single-thread improve speed of 16.7% and 70.2%, respectively. Finally, we design secondary search mechanism with HNSW to improve performance. Ours is suitable for large-scale datasets, and experimental results show that our method is 82% faster than the violent retrieval for the single-frame detection.
Top-Related Meta-Learning Method for Few-Shot Detection
Jul 27, 2020

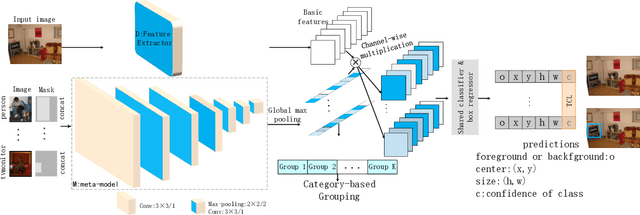

Many meta-learning methods are proposed for few-shot detection. However, previous most methods have two main problems, strong bias between all classes, and poor classification for few-shot classes. Previous works mainly depend on additional datasets and sub-module to alleviate these issues. However, they require more cost. In this paper, we find that the main challenge lies on imbalance between the examples, and poor shared distribution of class-based meta-features. Therefore, we propose a TCL for classification task and a category-based grouping mechanism. The TCL exploits the classification score of true-label class and the classification score of the most similar class to improve detection performance on few-shot classes. According to appearance and environment, the category-based grouping mechanism groups categories into different groupings to promote different similar semantic features more compact, alleviating the strong bias problem and further improving few-shot detection APs. The whole training consists of the base model and the fine-tuning phase. During training detection model, the category-related meta-features are regarded as the weights of the detection layer, exploiting the meta-features with a shared distribution between categories within a group to improve the detection performance. According to grouping mechanism, we group the meta-features vectors, so that the distribution difference between groups is obvious, and the one within each group is less. Experimental results on Pascal VOC dataset demonstrate that ours which combines the TCL with category-based grouping significantly outperforms previous state-of-the-art methods for 1, 2-shot detection, and obtains detection APs of almost 30% for 3-shot detection.
Pixel-Semantic Revise of Position Learning A One-Stage Object Detector with A Shared Encoder-Decoder
Jan 04, 2020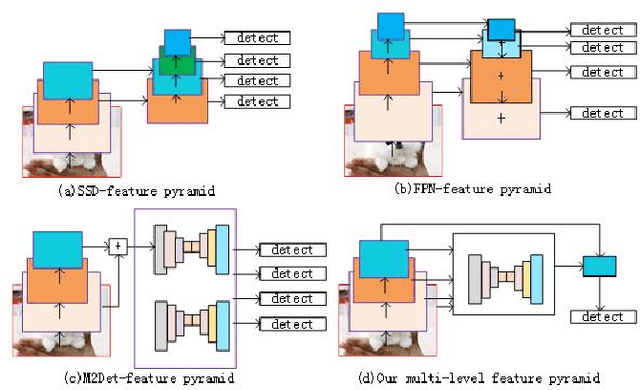
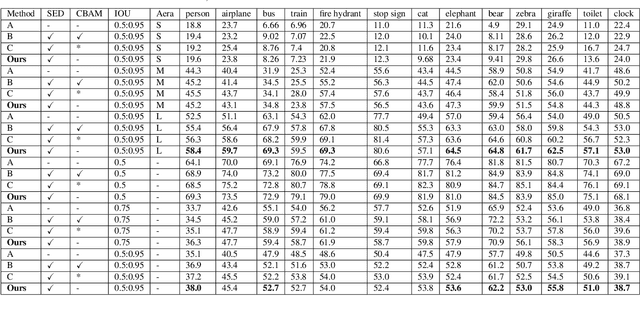
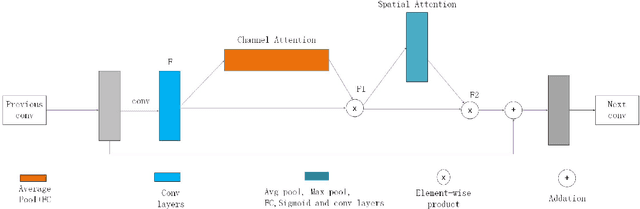

We analyze that different methods based channel or position attention mechanism give rise to different performance on scale, and some of state-of-the-art detectors applying feature pyramid are integrated with various variants convolutions with many mechanisms to enhance information, resulting in increasing runtime. This work addresses the problem by constructing an anchor-free detector with shared module consisting of encoder and decoder with attention mechanism. First, we consider different level features from backbone (e.g., ResNet-50) as the base features. Second, we feed the feature into a simple block, rather than various complex operations.Then, location and classification tasks are obtained by the detector head and classifier, respectively. At the same time, we use the semantic information to revise geometry locations. Additionally, we show that the detector is a pixel-semantic revise of position, universal, effective and simple to detect, especially, large-scale objects. More importantly, this work compares different feature processing (e.g.,mean, maximum or minimum) performance across channel. Finally,we present that our method improves detection accuracy by 3.8 AP compared to state-of-the-art MNC based ResNet-101 on the standard MSCOCO baseline.