 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMN: A Sample Attention Memory Network Combining SVM and NN in One Architecture
Sep 25, 2023Support vector machine (SVM) and neural networks (NN) have strong complementarity. SVM focuses on the inner operation among samples while NN focuses on the operation among the features within samples. Thus, it is promising and attractive to combine SVM and NN, as it may provide a more powerful function than SVM or NN alone. However, current work on combining them lacks true integration. To address this, we propose a sample attention memory network (SAMN) that effectively combines SVM and NN by incorporating sample attention module, class prototypes, and memory block to NN. SVM can be viewed as a sample attention machine. It allows us to add a sample attention module to NN to implement the main function of SVM. Class prototypes are representatives of all classes, which can be viewed as alternatives to support vectors. The memory block is used for the storage and update of class prototypes. Class prototypes and memory block effectively reduce the computational cost of sample attention and make SAMN suitable for multi-classification tasks. Extensive experiments show that SAMN achieves better classification performance than single SVM or single NN with similar parameter sizes, as well as the previous best model for combining SVM and NN. The sample attention mechanism is a flexible module that can be easily deepened and incorporated into neural networks that require it.
MaxMin-L2-SVC-NCH: A Novel Approach for Support Vector Classifier Training and Parameter Selection
Jul 25, 2023



The selection of Gaussian kernel parameters plays an important role in the applications of support vector classification (SVC). A commonly used method is the k-fold cross validation with grid search (CV), which is extremely time-consuming because it needs to train a large number of SVC models. In this paper, a new approach is proposed to train SVC and optimize the selection of Gaussian kernel parameters. We first formulate the training and parameter selection of SVC as a minimax optimization problem named as MaxMin-L2-SVC-NCH, in which the minimization problem is an optimization problem of finding the closest points between two normal convex hulls (L2-SVC-NCH) while the maximization problem is an optimization problem of finding the optimal Gaussian kernel parameters. A lower time complexity can be expected in MaxMin-L2-SVC-NCH because CV is not needed. We then propose a projected gradient algorithm (PGA) for training L2-SVC-NCH. The famous sequential minimal optimization (SMO) algorithm is a special case of the PGA. Thus, the PGA can provide more flexibility than the SMO. Furthermore, the solution of the maximization problem is done by a gradient ascent algorithm with dynamic learning rate. The comparative experiments between MaxMin-L2-SVC-NCH and the previous best approaches on public datasets show that MaxMin-L2-SVC-NCH greatly reduces the number of models to be trained while maintaining competitive test accuracy. These findings indicate that MaxMin-L2-SVC-NCH is a better choice for SVC tasks.
Automatic Sparse Connectivity Learning for Neural Networks
Jan 13, 2022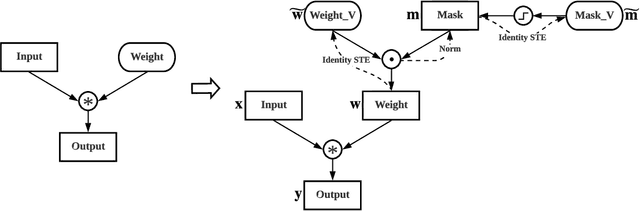

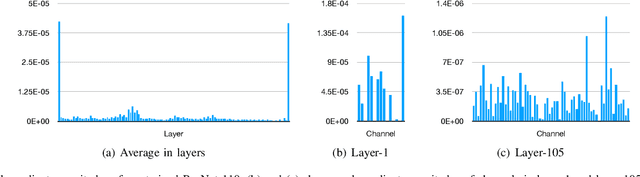
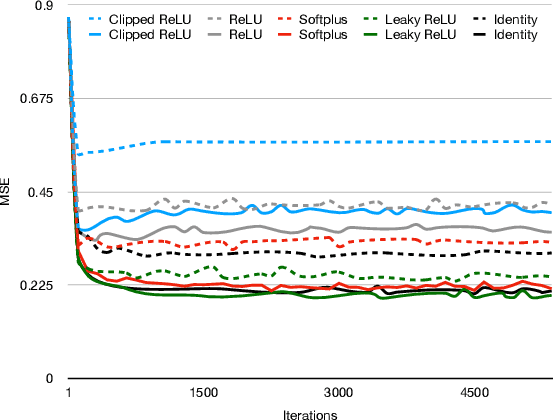
Since sparse neural networks usually contain many zero weights, these unnecessary network connections can potentially be eliminated without degrading network performance. Therefore, well-designed sparse neural networks have the potential to significantly reduce FLOPs and computational resources. In this work, we propose a new automatic pruning method - Sparse Connectivity Learning (SCL). Specifically, a weight is re-parameterized as an element-wise multiplication of a trainable weight variable and a binary mask. Thus, network connectivity is fully described by the binary mask, which is modulated by a unit step function. We theoretically prove the fundamental principle of using a straight-through estimator (STE) for network pruning. This principle is that the proxy gradients of STE should be positive, ensuring that mask variables converge at their minima. After finding Leaky ReLU, Softplus, and Identity STEs can satisfy this principle, we propose to adopt Identity STE in SCL for discrete mask relaxation. We find that mask gradients of different features are very unbalanced, hence, we propose to normalize mask gradients of each feature to optimize mask variable training. In order to automatically train sparse masks, we include the total number of network connections as a regularization term in our objective function. As SCL does not require pruning criteria or hyper-parameters defined by designers for network layers, the network is explored in a larger hypothesis space to achieve optimized sparse connectivity for the best performance. SCL overcomes the limitations of existing automatic pruning methods. Experimental results demonstrate that SCL can automatically learn and select important network connections for various baseline network structures. Deep learning models trained by SCL outperform the SOTA human-designed and automatic pruning methods in sparsity, accuracy, and FLOPs reduction.
Training convolutional neural networks with cheap convolutions and online distillation
Oct 10, 2019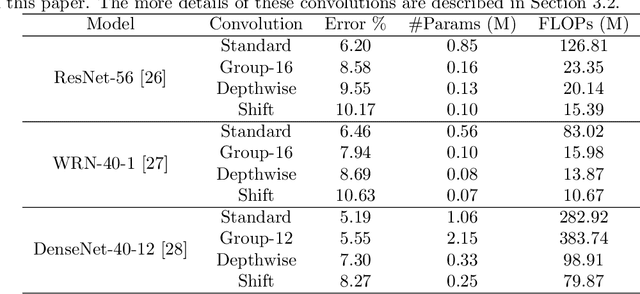
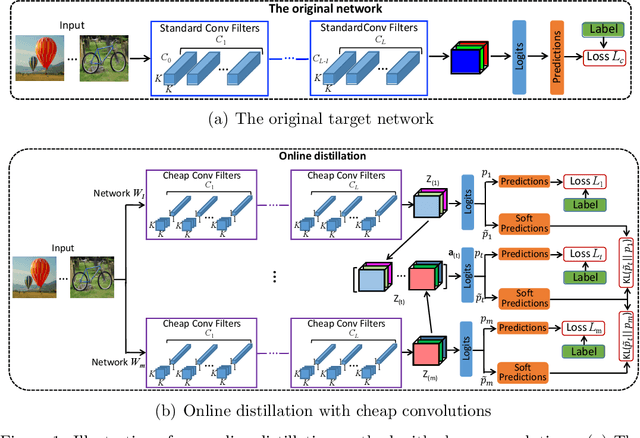
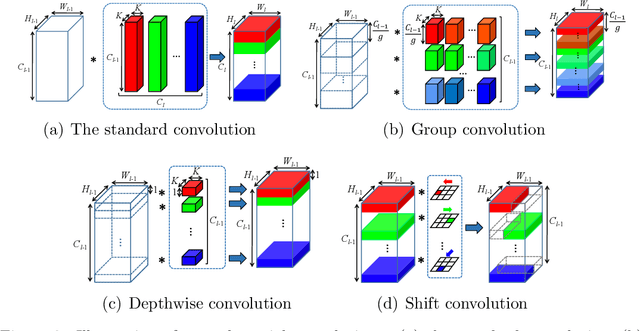

The large memory and computation consumption in convolutional neural networks (CNNs) has been one of the main barriers for deploying them on resource-limited systems. To this end, most cheap convolutions (e.g., group convolution, depth-wise convolution, and shift convolution) have recently been used for memory and computation reduction but with the specific architecture designing. Furthermore, it results in a low discriminability of the compressed networks by directly replacing the standard convolution with these cheap ones. In this paper, we propose to use knowledge distillation to improve the performance of the compact student networks with cheap convolutions. In our case, the teacher is a network with the standard convolution, while the student is a simple transformation of the teacher architecture without complicated redesigning. In particular, we propose a novel online distillation method, which online constructs the teacher network without pre-training and conducts mutual learning between the teacher and student network, to improve the performance of the student model. Extensive experiments demonstrate that the proposed approach achieves superior performance to simultaneously reduce memory and computation overhead of cutting-edge CNNs on different datasets, including CIFAR-10/100 and ImageNet ILSVRC 2012, compared to the state-of-the-art CNN compression and acceleration methods. The codes are publicly available at https://github.com/EthanZhangYC/OD-cheap-convolution.
EmotionX-HSU: Adopting Pre-trained BERT for Emotion Classification
Jul 23, 2019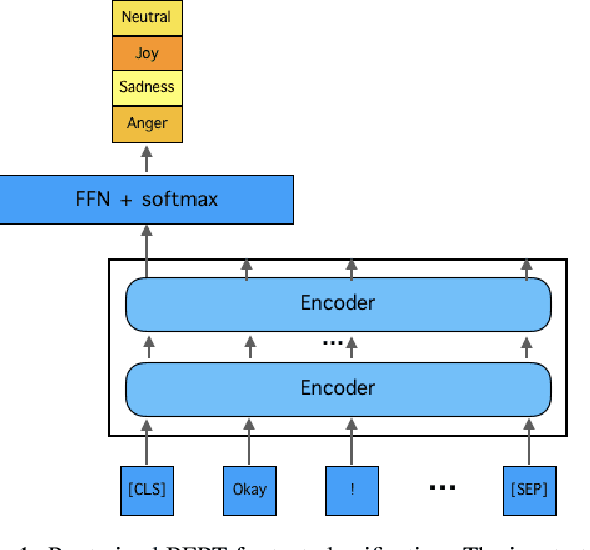
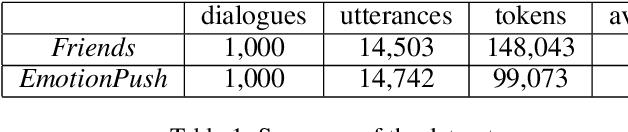


This paper describes our approach to the EmotionX-2019, the shared task of SocialNLP 2019. To detect emotion for each utterance of two datasets from the TV show Friends and Facebook chat log EmotionPush, we propose two-step deep learning based methodology: (i) encode each of the utterance into a sequence of vectors that represent its meaning; and (ii) use a simply softmax classifier to predict one of the emotions amongst four candidates that an utterance may carry. Notice that the source of labeled utterances is not rich, we utilise a well-trained model, known as BERT, to transfer part of the knowledge learned from a large amount of corpus to our model. We then focus on fine-tuning our model until it well fits to the in-domain data. The performance of the proposed model is evaluated by micro-F1 scores, i.e., 79.1% and 86.2% for the testsets of Friends and EmotionPush, respectively. Our model ranks 3rd among 11 submissions.
EmotionX-DLC: Self-Attentive BiLSTM for Detecting Sequential Emotions in Dialogue
Jun 20, 2018

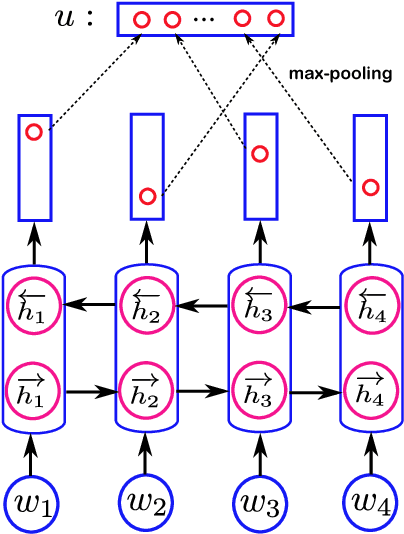
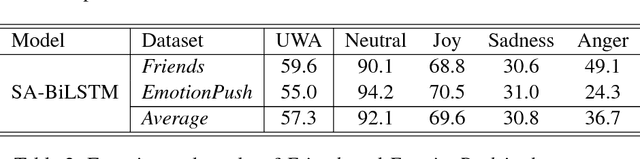
In this paper, we propose a self-attentive bidirectional long short-term memory (SA-BiLSTM) network to predict multiple emotions for the EmotionX challenge. The BiLSTM exhibits the power of modeling the word dependencies, and extracting the most relevant features for emotion classification. Building on top of BiLSTM, the self-attentive network can model the contextual dependencies between utterances which are helpful for classifying the ambiguous emotions. We achieve 59.6 and 55.0 unweighted accuracy scores in the \textit{Friends} and the \textit{EmotionPush} test sets, respectively.