 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining convolutional neural networks with cheap convolutions and online distillation
Paper and Code
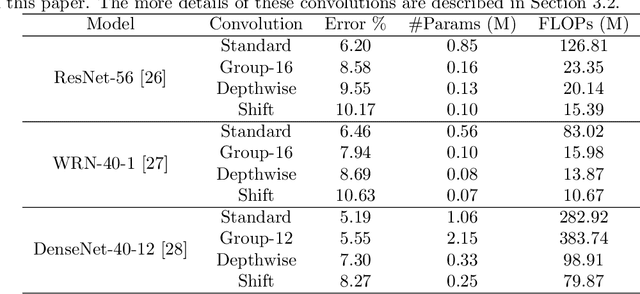
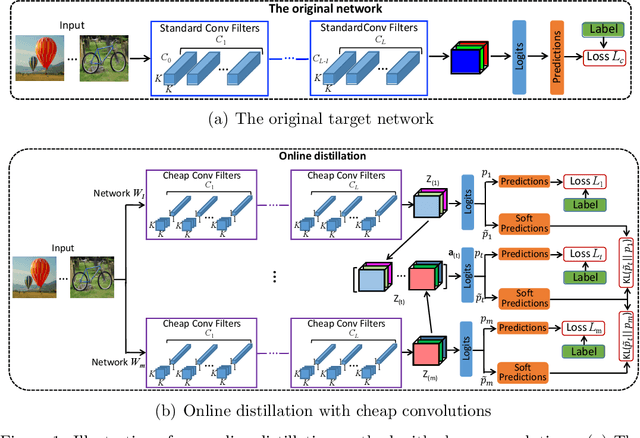
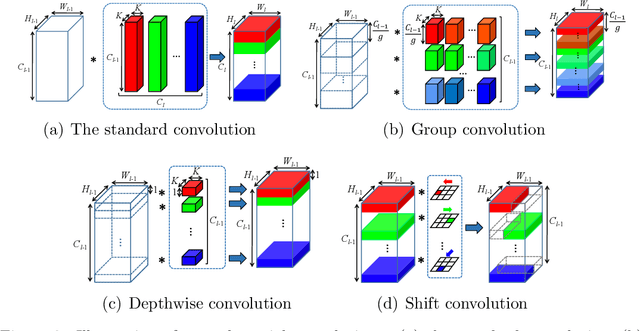

The large memory and computation consumption in convolutional neural networks (CNNs) has been one of the main barriers for deploying them on resource-limited systems. To this end, most cheap convolutions (e.g., group convolution, depth-wise convolution, and shift convolution) have recently been used for memory and computation reduction but with the specific architecture designing. Furthermore, it results in a low discriminability of the compressed networks by directly replacing the standard convolution with these cheap ones. In this paper, we propose to use knowledge distillation to improve the performance of the compact student networks with cheap convolutions. In our case, the teacher is a network with the standard convolution, while the student is a simple transformation of the teacher architecture without complicated redesigning. In particular, we propose a novel online distillation method, which online constructs the teacher network without pre-training and conducts mutual learning between the teacher and student network, to improve the performance of the student model. Extensive experiments demonstrate that the proposed approach achieves superior performance to simultaneously reduce memory and computation overhead of cutting-edge CNNs on different datasets, including CIFAR-10/100 and ImageNet ILSVRC 2012, compared to the state-of-the-art CNN compression and acceleration methods. The codes are publicly available at https://github.com/EthanZhangYC/OD-cheap-convolution.