 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Large Language Reasoning Models via Extreme-Ratio Chain-of-Thought Compression
Feb 09, 2026Chain-of-Thought (CoT) reasoning successfully enhances the reasoning capabilities of Large Language Models (LLMs), yet it incurs substantial computational overhead for inference. Existing CoT compression methods often suffer from a critical loss of logical fidelity at high compression ratios, resulting in significant performance degradation. To achieve high-fidelity, fast reasoning, we propose a novel EXTreme-RAtio Chain-of-Thought Compression framework, termed Extra-CoT, which aggressively reduces the token budget while preserving answer accuracy. To generate reliable, high-fidelity supervision, we first train a dedicated semantically-preserved compressor on mathematical CoT data with fine-grained annotations. An LLM is then fine-tuned on these compressed pairs via a mixed-ratio supervised fine-tuning (SFT), teaching it to follow a spectrum of compression budgets and providing a stable initialization for reinforcement learning (RL). We further propose Constrained and Hierarchical Ratio Policy Optimization (CHRPO) to explicitly incentivize question-solving ability under lower budgets by a hierarchical reward. Experiments on three mathematical reasoning benchmarks show the superiority of Extra-CoT. For example, on MATH-500 using Qwen3-1.7B, Extra-CoT achieves over 73\% token reduction with an accuracy improvement of 0.6\%, significantly outperforming state-of-the-art (SOTA) methods.
Dynamic Contrastive Knowledge Distillation for Efficient Image Restoration
Dec 12, 2024



Knowledge distillation (KD) is a valuable yet challenging approach that enhances a compact student network by learning from a high-performance but cumbersome teacher model. However, previous KD methods for image restoration overlook the state of the student during the distillation, adopting a fixed solution space that limits the capability of KD. Additionally, relying solely on L1-type loss struggles to leverage the distribution information of images. In this work, we propose a novel dynamic contrastive knowledge distillation (DCKD) framework for image restoration. Specifically, we introduce dynamic contrastive regularization to perceive the student's learning state and dynamically adjust the distilled solution space using contrastive learning. Additionally, we also propose a distribution mapping module to extract and align the pixel-level category distribution of the teacher and student models. Note that the proposed DCKD is a structure-agnostic distillation framework, which can adapt to different backbones and can be combined with methods that optimize upper-bound constraints to further enhance model performance. Extensive experiments demonstrate that DCKD significantly outperforms the state-of-the-art KD methods across various image restoration tasks and backbones.
Hi-Mamba: Hierarchical Mamba for Efficient Image Super-Resolution
Oct 14, 2024



State Space Models (SSM), such as Mamba, have shown strong representation ability in modeling long-range dependency with linear complexity, achieving successful applications from high-level to low-level vision tasks. However, SSM's sequential nature necessitates multiple scans in different directions to compensate for the loss of spatial dependency when unfolding the image into a 1D sequence. This multi-direction scanning strategy significantly increases the computation overhead and is unbearable for high-resolution image processing. To address this problem, we propose a novel Hierarchical Mamba network, namely, Hi-Mamba, for image super-resolution (SR). Hi-Mamba consists of two key designs: (1) The Hierarchical Mamba Block (HMB) assembled by a Local SSM (L-SSM) and a Region SSM (R-SSM) both with the single-direction scanning, aggregates multi-scale representations to enhance the context modeling ability. (2) The Direction Alternation Hierarchical Mamba Group (DA-HMG) allocates the isomeric single-direction scanning into cascading HMBs to enrich the spatial relationship modeling. Extensive experiments demonstrate the superiority of Hi-Mamba across five benchmark datasets for efficient SR. For example, Hi-Mamba achieves a significant PSNR improvement of 0.29 dB on Manga109 for $\times3$ SR, compared to the strong lightweight MambaIR.
A General and Efficient Training for Transformer via Token Expansion
Mar 31, 2024



The remarkable performance of Vision Transformers (ViTs) typically requires an extremely large training cost. Existing methods have attempted to accelerate the training of ViTs, yet typically disregard method universality with accuracy dropping. Meanwhile, they break the training consistency of the original transformers, including the consistency of hyper-parameters, architecture, and strategy, which prevents them from being widely applied to different Transformer networks. In this paper, we propose a novel token growth scheme Token Expansion (termed ToE) to achieve consistent training acceleration for ViTs. We introduce an "initialization-expansion-merging" pipeline to maintain the integrity of the intermediate feature distribution of original transformers, preventing the loss of crucial learnable information in the training process. ToE can not only be seamlessly integrated into the training and fine-tuning process of transformers (e.g., DeiT and LV-ViT), but also effective for efficient training frameworks (e.g., EfficientTrain), without twisting the original training hyper-parameters, architecture, and introducing additional training strategies. Extensive experiments demonstrate that ToE achieves about 1.3x faster for the training of ViTs in a lossless manner, or even with performance gains over the full-token training baselines. Code is available at https://github.com/Osilly/TokenExpansion .
Filter Pruning for Efficient CNNs via Knowledge-driven Differential Filter Sampler
Jul 01, 2023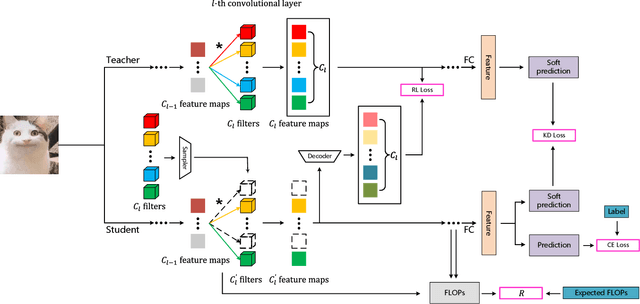
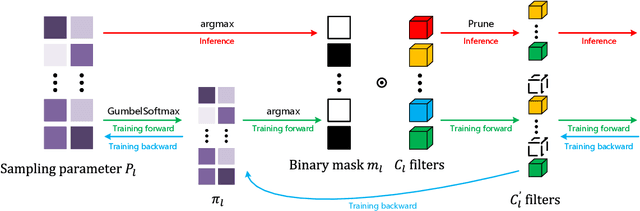
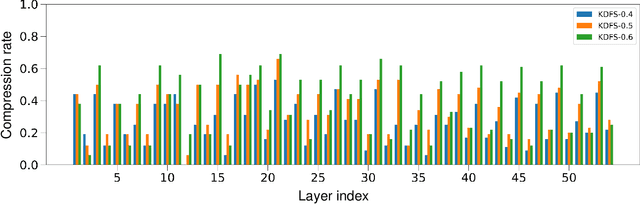
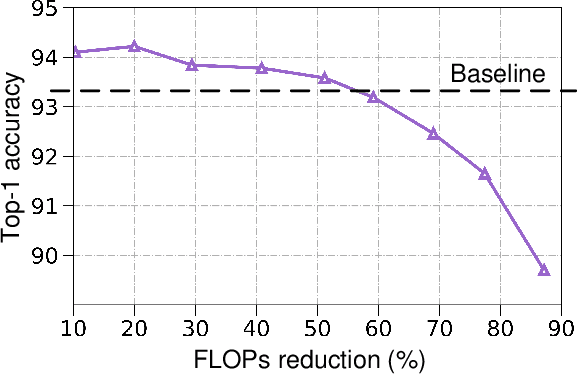
Filter pruning simultaneously accelerates the computation and reduces the memory overhead of CNNs, which can be effectively applied to edge devices and cloud services. In this paper, we propose a novel Knowledge-driven Differential Filter Sampler~(KDFS) with Masked Filter Modeling~(MFM) framework for filter pruning, which globally prunes the redundant filters based on the prior knowledge of a pre-trained model in a differential and non-alternative optimization. Specifically, we design a differential sampler with learnable sampling parameters to build a binary mask vector for each layer, determining whether the corresponding filters are redundant. To learn the mask, we introduce masked filter modeling to construct PCA-like knowledge by aligning the intermediate features from the pre-trained teacher model and the outputs of the student decoder taking sampling features as the input. The mask and sampler are directly optimized by the Gumbel-Softmax Straight-Through Gradient Estimator in an end-to-end manner in combination with global pruning constraint, MFM reconstruction error, and dark knowledge. Extensive experiments demonstrate the proposed KDFS's effectiveness in compressing the base models on various datasets. For instance, the pruned ResNet-50 on ImageNet achieves $55.36\%$ computation reduction, and $42.86\%$ parameter reduction, while only dropping $0.35\%$ Top-1 accuracy, significantly outperforming the state-of-the-art methods. The code is available at \url{https://github.com/Osilly/KDFS}.
Rapid COVID-19 Risk Screening by Eye-region Manifestations
Jun 12, 2021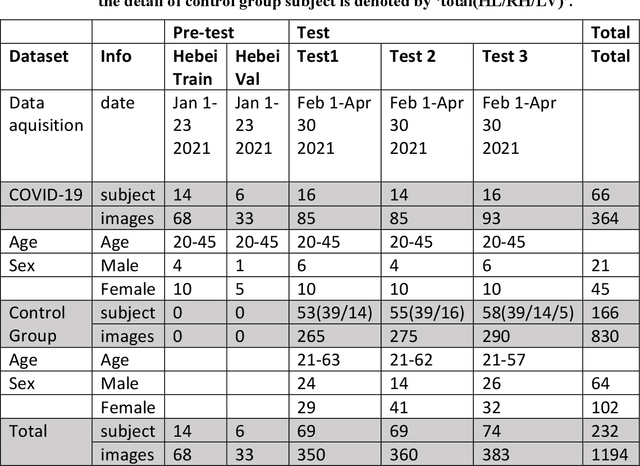

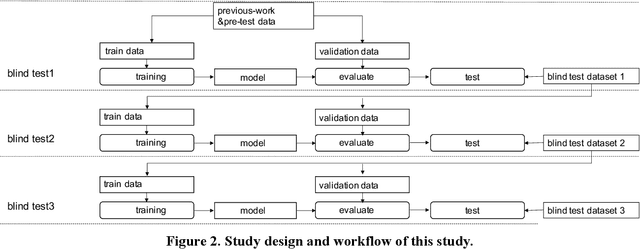
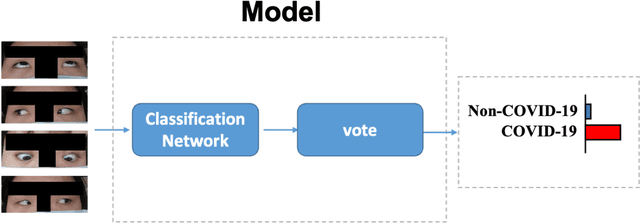
It is still nontrivial to develop a new fast COVID-19 screening method with the easier access and lower cost, due to the technical and cost limitations of the current testing methods in the medical resource-poor districts. On the other hand, there are more and more ocular manifestations that have been reported in the COVID-19 patients as growing clinical evidence[1]. This inspired this project. We have conducted the joint clinical research since January 2021 at the ShiJiaZhuang City, Heibei province, China, which approved by the ethics committee of The fifth hospital of ShiJiaZhuang of Hebei Medical University. We undertake several blind tests of COVID-19 patients by Union Hospital, Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China. Meantime as an important part of the ongoing globally COVID-19 eye test program by AIMOMICS since February 2020, we propose a new fast screening method of analyzing the eye-region images, captured by common CCD and CMOS cameras. This could reliably make a rapid risk screening of COVID-19 with the sustainable stable high performance in different countries and races. Our model for COVID-19 rapid prescreening have the merits of the lower cost, fully self-performed, non-invasive, importantly real-time, and thus enables the continuous health surveillance. We further implement it as the open accessible APIs, and provide public service to the world. Our pilot experiments show that our model is ready to be usable to all kinds of surveillance scenarios, such as infrared temperature measurement device at airports and stations, or directly pushing to the target people groups smartphones as a packaged application.
Training convolutional neural networks with cheap convolutions and online distillation
Oct 10, 2019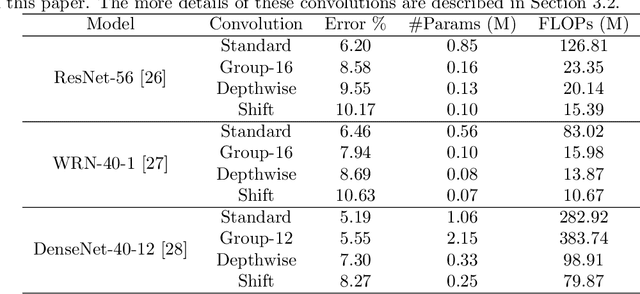
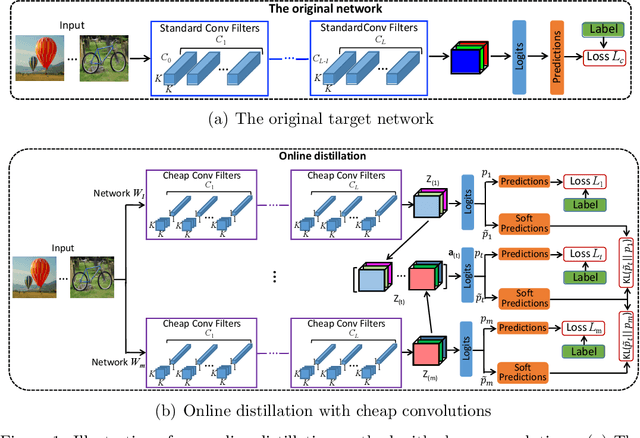
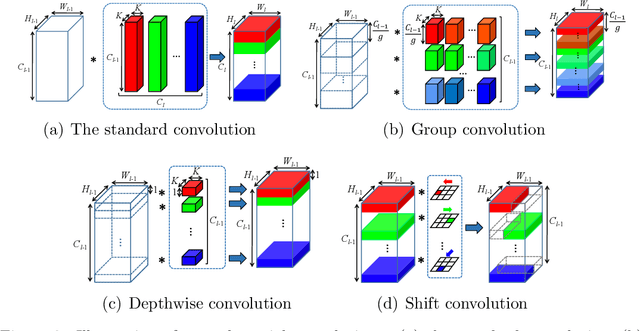

The large memory and computation consumption in convolutional neural networks (CNNs) has been one of the main barriers for deploying them on resource-limited systems. To this end, most cheap convolutions (e.g., group convolution, depth-wise convolution, and shift convolution) have recently been used for memory and computation reduction but with the specific architecture designing. Furthermore, it results in a low discriminability of the compressed networks by directly replacing the standard convolution with these cheap ones. In this paper, we propose to use knowledge distillation to improve the performance of the compact student networks with cheap convolutions. In our case, the teacher is a network with the standard convolution, while the student is a simple transformation of the teacher architecture without complicated redesigning. In particular, we propose a novel online distillation method, which online constructs the teacher network without pre-training and conducts mutual learning between the teacher and student network, to improve the performance of the student model. Extensive experiments demonstrate that the proposed approach achieves superior performance to simultaneously reduce memory and computation overhead of cutting-edge CNNs on different datasets, including CIFAR-10/100 and ImageNet ILSVRC 2012, compared to the state-of-the-art CNN compression and acceleration methods. The codes are publicly available at https://github.com/EthanZhangYC/OD-cheap-convolution.