 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-sync Video Instance Editing with Granularity-Aware Mask Refiner
Dec 11, 2025



Recent advancements in video generation highlight that realistic audio-visual synchronization is crucial for engaging content creation. However, existing video editing methods largely overlook audio-visual synchronization and lack the fine-grained spatial and temporal controllability required for precise instance-level edits. In this paper, we propose AVI-Edit, a framework for audio-sync video instance editing. We propose a granularity-aware mask refiner that iteratively refines coarse user-provided masks into precise instance-level regions. We further design a self-feedback audio agent to curate high-quality audio guidance, providing fine-grained temporal control. To facilitate this task, we additionally construct a large-scale dataset with instance-centric correspondence and comprehensive annotations. Extensive experiments demonstrate that AVI-Edit outperforms state-of-the-art methods in visual quality, condition following, and audio-visual synchronization. Project page: https://hjzheng.net/projects/AVI-Edit/.
Audio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
NodeRAG: Structuring Graph-based RAG with Heterogeneous Nodes
Apr 15, 2025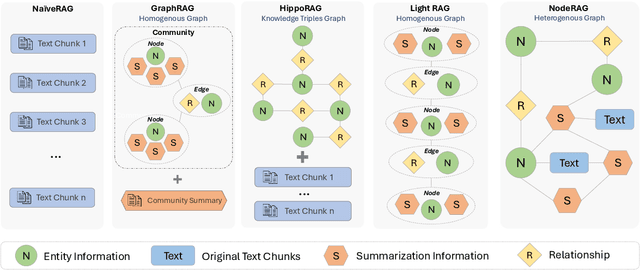
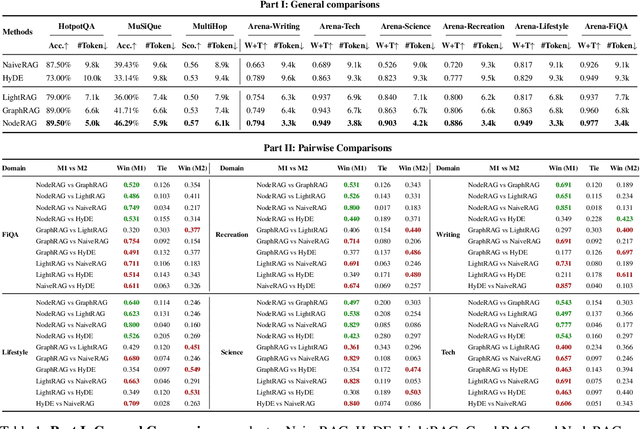
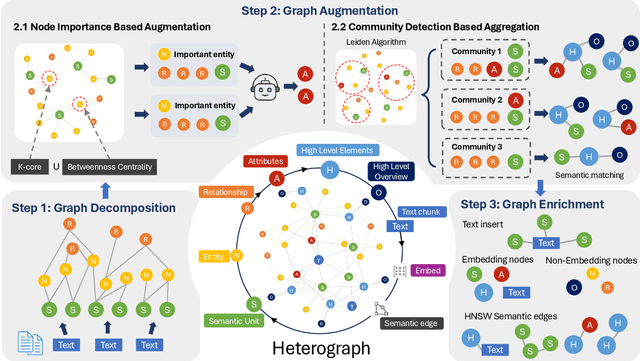
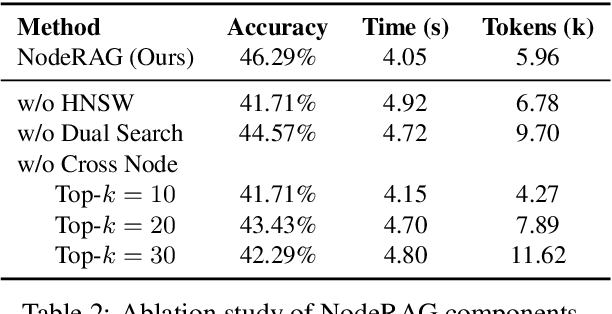
Retrieval-augmented generation (RAG) empowers large language models to access external and private corpus, enabling factually consistent responses in specific domains. By exploiting the inherent structure of the corpus, graph-based RAG methods further enrich this process by building a knowledge graph index and leveraging the structural nature of graphs. However, current graph-based RAG approaches seldom prioritize the design of graph structures. Inadequately designed graph not only impede the seamless integration of diverse graph algorithms but also result in workflow inconsistencies and degraded performance. To further unleash the potential of graph for RAG, we propose NodeRAG, a graph-centric framework introducing heterogeneous graph structures that enable the seamless and holistic integration of graph-based methodologies into the RAG workflow. By aligning closely with the capabilities of LLMs, this framework ensures a fully cohesive and efficient end-to-end process. Through extensive experiments, we demonstrate that NodeRAG exhibits performance advantages over previous methods, including GraphRAG and LightRAG, not only in indexing time, query time, and storage efficiency but also in delivering superior question-answering performance on multi-hop benchmarks and open-ended head-to-head evaluations with minimal retrieval tokens. Our GitHub repository could be seen at https://github.com/Terry-Xu-666/NodeRAG.
VIRES: Video Instance Repainting with Sketch and Text Guidance
Nov 26, 2024



We introduce VIRES, a video instance repainting method with sketch and text guidance, enabling video instance repainting, replacement, generation, and removal. Existing approaches struggle with temporal consistency and accurate alignment with the provided sketch sequence. VIRES leverages the generative priors of text-to-video models to maintain temporal consistency and produce visually pleasing results. We propose the Sequential ControlNet with the standardized self-scaling, which effectively extracts structure layouts and adaptively captures high-contrast sketch details. We further augment the diffusion transformer backbone with the sketch attention to interpret and inject fine-grained sketch semantics. A sketch-aware encoder ensures that repainted results are aligned with the provided sketch sequence. Additionally, we contribute the VireSet, a dataset with detailed annotations tailored for training and evaluating video instance editing methods. Experimental results demonstrate the effectiveness of VIRES, which outperforms state-of-the-art methods in visual quality, temporal consistency, condition alignment, and human ratings. Project page:https://suimuc.github.io/suimu.github.io/projects/VIRES/
Thinking Before Looking: Improving Multimodal LLM Reasoning via Mitigating Visual Hallucination
Nov 15, 2024



Multimodal large language models (MLLMs) have advanced the integration of visual and linguistic modalities, establishing themselves as the dominant paradigm for visual-language tasks. Current approaches like chain of thought (CoT) reasoning have augmented the cognitive capabilities of large language models (LLMs), yet their adaptation to MLLMs is hindered by heightened risks of hallucination in cross-modality comprehension. In this paper, we find that the thinking while looking paradigm in current multimodal CoT approaches--where reasoning chains are generated alongside visual input--fails to mitigate hallucinations caused by misleading images. To address these limitations, we propose the Visual Inference Chain (VIC) framework, a novel approach that constructs reasoning chains using textual context alone before introducing visual input, effectively reducing cross-modal biases and enhancing multimodal reasoning accuracy. Comprehensive evaluations demonstrate that VIC significantly improves zero-shot performance across various vision-related tasks, mitigating hallucinations while refining the reasoning capabilities of MLLMs. Our code repository can be found at https://github.com/Terry-Xu-666/visual_inference_chain.
The Report on China-Spain Joint Clinical Testing for Rapid COVID-19 Risk Screening by Eye-region Manifestations
Sep 18, 2021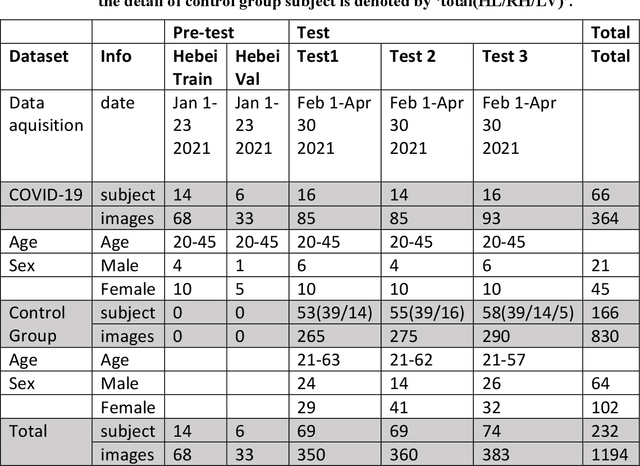

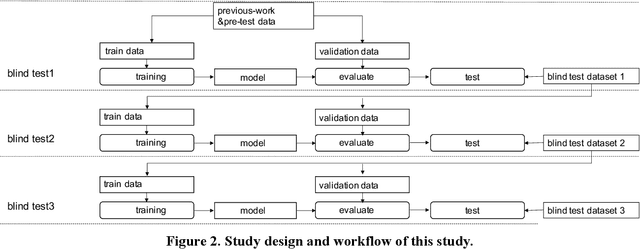
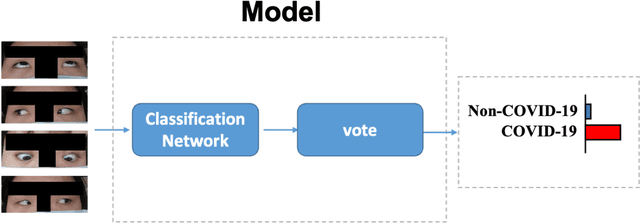
Background: The worldwide surge in coronavirus cases has led to the COVID-19 testing demand surge. Rapid, accurate, and cost-effective COVID-19 screening tests working at a population level are in imperative demand globally. Methods: Based on the eye symptoms of COVID-19, we developed and tested a COVID-19 rapid prescreening model using the eye-region images captured in China and Spain with cellphone cameras. The convolutional neural networks (CNNs)-based model was trained on these eye images to complete binary classification task of identifying the COVID-19 cases. The performance was measured using area under receiver-operating-characteristic curve (AUC), sensitivity, specificity, accuracy, and F1. The application programming interface was open access. Findings: The multicenter study included 2436 pictures corresponding to 657 subjects (155 COVID-19 infection, 23.6%) in development dataset (train and validation) and 2138 pictures corresponding to 478 subjects (64 COVID-19 infections, 13.4%) in test dataset. The image-level performance of COVID-19 prescreening model in the China-Spain multicenter study achieved an AUC of 0.913 (95% CI, 0.898-0.927), with a sensitivity of 0.695 (95% CI, 0.643-0.748), a specificity of 0.904 (95% CI, 0.891 -0.919), an accuracy of 0.875(0.861-0.889), and a F1 of 0.611(0.568-0.655). Interpretation: The CNN-based model for COVID-19 rapid prescreening has reliable specificity and sensitivity. This system provides a low-cost, fully self-performed, non-invasive, real-time feedback solution for continuous surveillance and large-scale rapid prescreening for COVID-19. Funding: This project is supported by Aimomics (Shanghai) Intelligent
Rapid COVID-19 Risk Screening by Eye-region Manifestations
Jun 12, 2021It is still nontrivial to develop a new fast COVID-19 screening method with the easier access and lower cost, due to the technical and cost limitations of the current testing methods in the medical resource-poor districts. On the other hand, there are more and more ocular manifestations that have been reported in the COVID-19 patients as growing clinical evidence[1]. This inspired this project. We have conducted the joint clinical research since January 2021 at the ShiJiaZhuang City, Heibei province, China, which approved by the ethics committee of The fifth hospital of ShiJiaZhuang of Hebei Medical University. We undertake several blind tests of COVID-19 patients by Union Hospital, Tongji Medical College, Huazhong University of Science and Technology, Wuhan, China. Meantime as an important part of the ongoing globally COVID-19 eye test program by AIMOMICS since February 2020, we propose a new fast screening method of analyzing the eye-region images, captured by common CCD and CMOS cameras. This could reliably make a rapid risk screening of COVID-19 with the sustainable stable high performance in different countries and races. Our model for COVID-19 rapid prescreening have the merits of the lower cost, fully self-performed, non-invasive, importantly real-time, and thus enables the continuous health surveillance. We further implement it as the open accessible APIs, and provide public service to the world. Our pilot experiments show that our model is ready to be usable to all kinds of surveillance scenarios, such as infrared temperature measurement device at airports and stations, or directly pushing to the target people groups smartphones as a packaged application.