 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Sync Video Generation with Multi-Stream Temporal Control
Jun 09, 2025



Audio is inherently temporal and closely synchronized with the visual world, making it a naturally aligned and expressive control signal for controllable video generation (e.g., movies). Beyond control, directly translating audio into video is essential for understanding and visualizing rich audio narratives (e.g., Podcasts or historical recordings). However, existing approaches fall short in generating high-quality videos with precise audio-visual synchronization, especially across diverse and complex audio types. In this work, we introduce MTV, a versatile framework for audio-sync video generation. MTV explicitly separates audios into speech, effects, and music tracks, enabling disentangled control over lip motion, event timing, and visual mood, respectively -- resulting in fine-grained and semantically aligned video generation. To support the framework, we additionally present DEMIX, a dataset comprising high-quality cinematic videos and demixed audio tracks. DEMIX is structured into five overlapped subsets, enabling scalable multi-stage training for diverse generation scenarios. Extensive experiments demonstrate that MTV achieves state-of-the-art performance across six standard metrics spanning video quality, text-video consistency, and audio-video alignment. Project page: https://hjzheng.net/projects/MTV/.
Deploying Large AI Models on Resource-Limited Devices with Split Federated Learning
Apr 12, 2025Large Artificial Intelligence Models (LAMs) powered by massive datasets, extensive parameter scales, and extensive computational resources, leading to significant transformations across various industries. Yet, their practical deployment on resource-limited mobile edge devices is hindered by critical challenges such as data privacy, constrained resources, and high overhead costs. Addressing this gap, this paper proposes a novel framework, named Quantized Split Federated Fine-Tuning Large AI Model (SFLAM). By partitioning the training load between edge devices and servers using a split learning paradigm, SFLAM can facilitate the operation of large models on devices and significantly lowers the memory requirements on edge devices. Additionally, SFLAM incorporates quantization management, power control, and bandwidth allocation strategies to enhance training efficiency while concurrently reducing energy consumption and communication latency. A theoretical analysis exploring the latency-energy trade-off is presented, and the framework's efficacy is validated via comprehensive simulations. The findings indicate that SFLAM achieves superior performance in terms of learning efficiency and scalability compared to conventional methods, thereby providing a valuable approach for enabling advanced AI services in resource-constrained scenarios.
AIGC-assisted Federated Learning for Edge Intelligence: Architecture Design, Research Challenges and Future Directions
Mar 26, 2025



Federated learning (FL) can fully leverage large-scale terminal data while ensuring privacy and security, and is considered as a distributed alternative for the centralized machine learning. However, the issue of data heterogeneity poses limitations on FL's performance. To address this challenge, artificial intelligence-generated content (AIGC) which is an innovative data synthesis technique emerges as one potential solution. In this article, we first provide an overview of the system architecture, performance metrics, and challenges associated with AIGC-assistant FL system design. We then propose the Generative federated learning (GenFL) architecture and present its workflow, including the design of aggregation and weight policy. Finally, using the CIFAR10 and CIFAR100 datasets, we employ diffusion models to generate dataset and improve FL performance. Experiments conducted under various non-independent and identically distributed (non-IID) data distributions demonstrate the effectiveness of GenFL on overcoming the bottlenecks in FL caused by data heterogeneity. Open research directions in the research of AIGC-assisted FL are also discussed.
IIMedGPT: Promoting Large Language Model Capabilities of Medical Tasks by Efficient Human Preference Alignment
Jan 06, 2025Recent researches of large language models(LLM), which is pre-trained on massive general-purpose corpora, have achieved breakthroughs in responding human queries. However, these methods face challenges including limited data insufficiency to support extensive pre-training and can not align responses with users' instructions. To address these issues, we introduce a medical instruction dataset, CMedINS, containing six medical instructions derived from actual medical tasks, which effectively fine-tunes LLM in conjunction with other data. Subsequently, We launch our medical model, IIMedGPT, employing an efficient preference alignment method, Direct preference Optimization(DPO). The results show that our final model outperforms existing medical models in medical dialogue.Datsets, Code and model checkpoints will be released upon acceptance.
Age-Based Device Selection and Transmit Power Optimization in Over-the-Air Federated Learning
Jan 03, 2025



Recently, over-the-air federated learning (FL) has attracted significant attention for its ability to enhance communication efficiency. However, the performance of over-the-air FL is often constrained by device selection strategies and signal aggregation errors. In particular, neglecting straggler devices in FL can lead to a decline in the fairness of model updates and amplify the global model's bias toward certain devices' data, ultimately impacting the overall system performance. To address this issue, we propose a joint device selection and transmit power optimization framework that ensures the appropriate participation of straggler devices, maintains efficient training performance, and guarantees timely updates. First, we conduct a theoretical analysis to quantify the convergence upper bound of over-the-air FL under age-of-information (AoI)-based device selection. Our analysis further reveals that both the number of selected devices and the signal aggregation errors significantly influence the convergence upper bound. To minimize the expected weighted sum peak age of information, we calculate device priorities for each communication round using Lyapunov optimization and select the highest-priority devices via a greedy algorithm. Then, we formulate and solve a transmit power and normalizing factor optimization problem for selected devices to minimize the time-average mean squared error (MSE). Experimental results demonstrate that our proposed method offers two significant advantages: (1) it reduces MSE and improves model performance compared to baseline methods, and (2) it strikes a balance between fairness and training efficiency while maintaining satisfactory timeliness, ensuring stable model performance.
Movable Antenna-Equipped UAV for Data Collection in Backscatter Sensor Networks: A Deep Reinforcement Learning-based Approach
Nov 21, 2024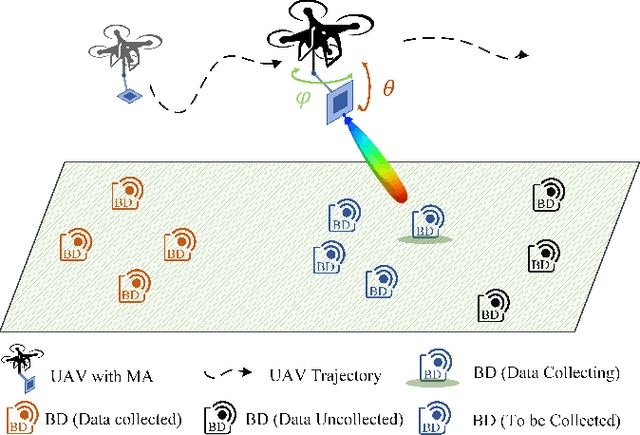
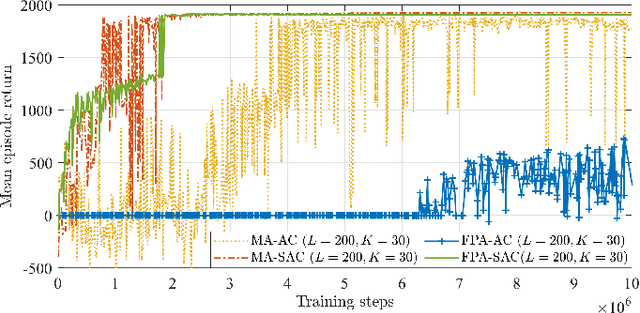
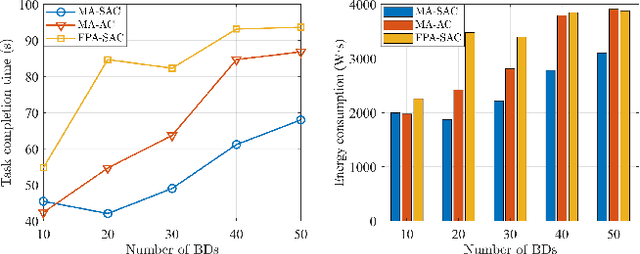

Backscatter communication (BC) becomes a promising energy-efficient solution for future wireless sensor networks (WSNs). Unmanned aerial vehicles (UAVs) enable flexible data collection from remote backscatter devices (BDs), yet conventional UAVs rely on omni-directional fixed-position antennas (FPAs), limiting channel gain and prolonging data collection time. To address this issue, we consider equipping a UAV with a directional movable antenna (MA) with high directivity and flexibility. The MA enhances channel gain by precisely aiming its main lobe at each BD, focusing transmission power for efficient communication. Our goal is to minimize the total data collection time by jointly optimizing the UAV's trajectory and the MA's orientation. We develop a deep reinforcement learning (DRL)-based strategy using the azimuth angle and distance between the UAV and each BD to simplify the agent's observation space. To ensure stability during training, we adopt Soft Actor-Critic (SAC) algorithm that balances exploration with reward maximization for efficient and reliable learning. Simulation results demonstrate that our proposed MA-equipped UAV with SAC outperforms both FPA-equipped UAVs and other RL methods, achieving significant reductions in both data collection time and energy consumption.
Model Partition and Resource Allocation for Split Learning in Vehicular Edge Networks
Nov 11, 2024



The integration of autonomous driving technologies with vehicular networks presents significant challenges in privacy preservation, communication efficiency, and resource allocation. This paper proposes a novel U-shaped split federated learning (U-SFL) framework to address these challenges on the way of realizing in vehicular edge networks. U-SFL is able to enhance privacy protection by keeping both raw data and labels on the vehicular user (VU) side while enabling parallel processing across multiple vehicles. To optimize communication efficiency, we introduce a semantic-aware auto-encoder (SAE) that significantly reduces the dimensionality of transmitted data while preserving essential semantic information. Furthermore, we develop a deep reinforcement learning (DRL) based algorithm to solve the NP-hard problem of dynamic resource allocation and split point selection. Our comprehensive evaluation demonstrates that U-SFL achieves comparable classification performance to traditional split learning (SL) while substantially reducing data transmission volume and communication latency. The proposed DRL-based optimization algorithm shows good convergence in balancing latency, energy consumption, and learning performance.
L-C4: Language-Based Video Colorization for Creative and Consistent Color
Oct 07, 2024



Automatic video colorization is inherently an ill-posed problem because each monochrome frame has multiple optional color candidates. Previous exemplar-based video colorization methods restrict the user's imagination due to the elaborate retrieval process. Alternatively, conditional image colorization methods combined with post-processing algorithms still struggle to maintain temporal consistency. To address these issues, we present Language-based video Colorization for Creative and Consistent Colors (L-C4) to guide the colorization process using user-provided language descriptions. Our model is built upon a pre-trained cross-modality generative model, leveraging its comprehensive language understanding and robust color representation abilities. We introduce the cross-modality pre-fusion module to generate instance-aware text embeddings, enabling the application of creative colors. Additionally, we propose temporally deformable attention to prevent flickering or color shifts, and cross-clip fusion to maintain long-term color consistency. Extensive experimental results demonstrate that L-C4 outperforms relevant methods, achieving semantically accurate colors, unrestricted creative correspondence, and temporally robust consistency.
Adaptive and Parallel Split Federated Learning in Vehicular Edge Computing
May 29, 2024



Vehicular edge intelligence (VEI) is a promising paradigm for enabling future intelligent transportation systems by accommodating artificial intelligence (AI) at the vehicular edge computing (VEC) system. Federated learning (FL) stands as one of the fundamental technologies facilitating collaborative model training locally and aggregation, while safeguarding the privacy of vehicle data in VEI. However, traditional FL faces challenges in adapting to vehicle heterogeneity, training large models on resource-constrained vehicles, and remaining susceptible to model weight privacy leakage. Meanwhile, split learning (SL) is proposed as a promising collaborative learning framework which can mitigate the risk of model wights leakage, and release the training workload on vehicles. SL sequentially trains a model between a vehicle and an edge cloud (EC) by dividing the entire model into a vehicle-side model and an EC-side model at a given cut layer. In this work, we combine the advantages of SL and FL to develop an Adaptive Split Federated Learning scheme for Vehicular Edge Computing (ASFV). The ASFV scheme adaptively splits the model and parallelizes the training process, taking into account mobile vehicle selection and resource allocation. Our extensive simulations, conducted on non-independent and identically distributed data, demonstrate that the proposed ASFV solution significantly reduces training latency compared to existing benchmarks, while adapting to network dynamics and vehicles' mobility.
L-CAD: Language-based Colorization with Any-level Descriptions
May 26, 2023
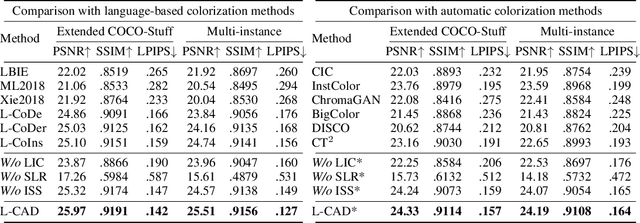


Language-based colorization produces plausible and visually pleasing colors under the guidance of user-friendly natural language descriptions. Previous methods implicitly assume that users provide comprehensive color descriptions for most of the objects in the image, which leads to suboptimal performance. In this paper, we propose a unified model to perform language-based colorization with any-level descriptions. We leverage the pretrained cross-modality generative model for its robust language understanding and rich color priors to handle the inherent ambiguity of any-level descriptions. We further design modules to align with input conditions to preserve local spatial structures and prevent the ghosting effect. With the proposed novel sampling strategy, our model achieves instance-aware colorization in diverse and complex scenarios. Extensive experimental results demonstrate our advantages of effectively handling any-level descriptions and outperforming both language-based and automatic colorization methods. The code and pretrained models are available at: https://github.com/changzheng123/L-CAD.