 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenLight: Precise Lighting Control in Images using Attribute Tokens
Apr 16, 2026This paper presents a method for image relighting that enables precise and continuous control over multiple illumination attributes in a photograph. We formulate relighting as a conditional image generation task and introduce attribute tokens to encode distinct lighting factors such as intensity, color, ambient illumination, diffuse level, and 3D light positions. The model is trained on a large-scale synthetic dataset with ground-truth lighting annotations, supplemented by a small set of real captures to enhance realism and generalization. We validate our approach across a variety of relighting tasks, including controlling in-scene lighting fixtures and editing environment illumination using virtual light sources, on synthetic and real images. Our method achieves state-of-the-art quantitative and qualitative performance compared to prior work. Remarkably, without explicit inverse rendering supervision, the model exhibits an inherent understanding of how light interacts with scene geometry, occlusion, and materials, yielding convincing lighting effects even in traditionally challenging scenarios such as placing lights within objects or relighting transparent materials plausibly. Project page: vrroom.github.io/tokenlight/
Structure From Tracking: Distilling Structure-Preserving Motion for Video Generation
Dec 12, 2025
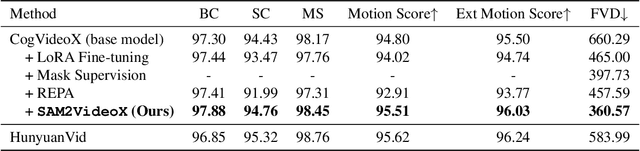
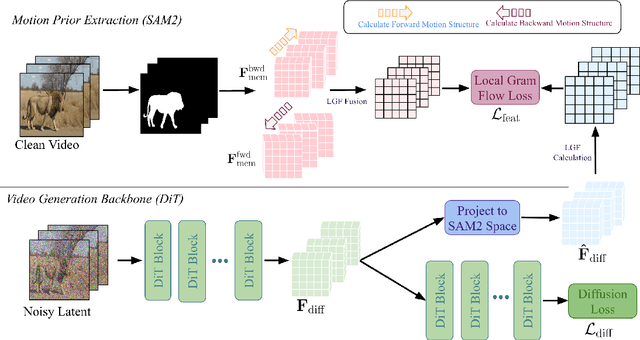
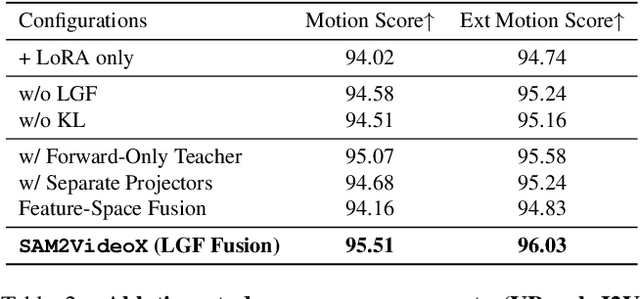
Reality is a dance between rigid constraints and deformable structures. For video models, that means generating motion that preserves fidelity as well as structure. Despite progress in diffusion models, producing realistic structure-preserving motion remains challenging, especially for articulated and deformable objects such as humans and animals. Scaling training data alone, so far, has failed to resolve physically implausible transitions. Existing approaches rely on conditioning with noisy motion representations, such as optical flow or skeletons extracted using an external imperfect model. To address these challenges, we introduce an algorithm to distill structure-preserving motion priors from an autoregressive video tracking model (SAM2) into a bidirectional video diffusion model (CogVideoX). With our method, we train SAM2VideoX, which contains two innovations: (1) a bidirectional feature fusion module that extracts global structure-preserving motion priors from a recurrent model like SAM2; (2) a Local Gram Flow loss that aligns how local features move together. Experiments on VBench and in human studies show that SAM2VideoX delivers consistent gains (+2.60\% on VBench, 21-22\% lower FVD, and 71.4\% human preference) over prior baselines. Specifically, on VBench, we achieve 95.51\%, surpassing REPA (92.91\%) by 2.60\%, and reduce FVD to 360.57, a 21.20\% and 22.46\% improvement over REPA- and LoRA-finetuning, respectively. The project website can be found at https://sam2videox.github.io/ .
Offline Clustering of Preference Learning with Active-data Augmentation
Oct 30, 2025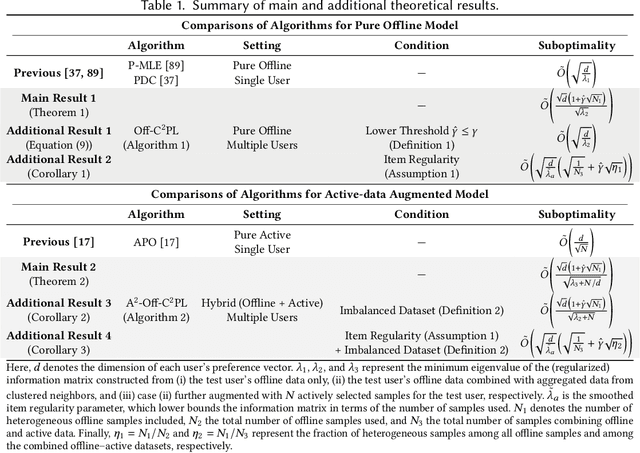
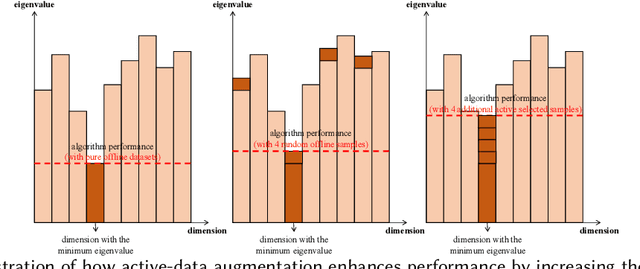

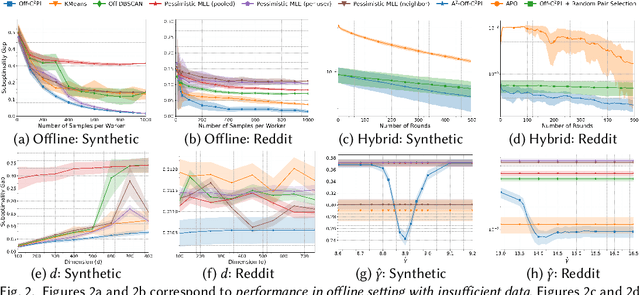
Preference learning from pairwise feedback is a widely adopted framework in applications such as reinforcement learning with human feedback and recommendations. In many practical settings, however, user interactions are limited or costly, making offline preference learning necessary. Moreover, real-world preference learning often involves users with different preferences. For example, annotators from different backgrounds may rank the same responses differently. This setting presents two central challenges: (1) identifying similarity across users to effectively aggregate data, especially under scenarios where offline data is imbalanced across dimensions, and (2) handling the imbalanced offline data where some preference dimensions are underrepresented. To address these challenges, we study the Offline Clustering of Preference Learning problem, where the learner has access to fixed datasets from multiple users with potentially different preferences and aims to maximize utility for a test user. To tackle the first challenge, we first propose Off-C$^2$PL for the pure offline setting, where the learner relies solely on offline data. Our theoretical analysis provides a suboptimality bound that explicitly captures the tradeoff between sample noise and bias. To address the second challenge of inbalanced data, we extend our framework to the setting with active-data augmentation where the learner is allowed to select a limited number of additional active-data for the test user based on the cluster structure learned by Off-C$^2$PL. In this setting, our second algorithm, A$^2$-Off-C$^2$PL, actively selects samples that target the least-informative dimensions of the test user's preference. We prove that these actively collected samples contribute more effectively than offline ones. Finally, we validate our theoretical results through simulations on synthetic and real-world datasets.
Distributed Multi-Agent Bandits Over Erdős-Rényi Random Networks
Oct 26, 2025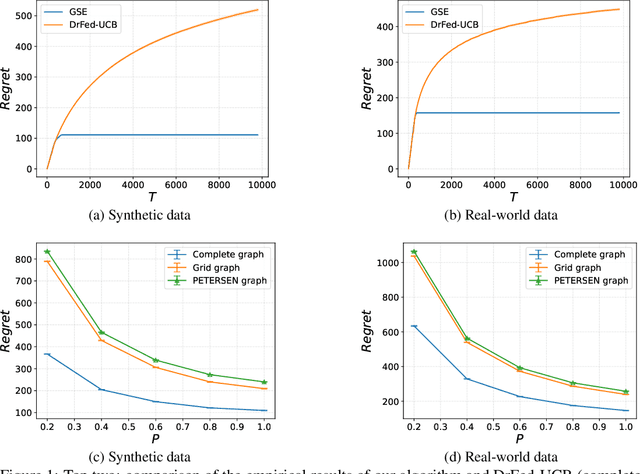

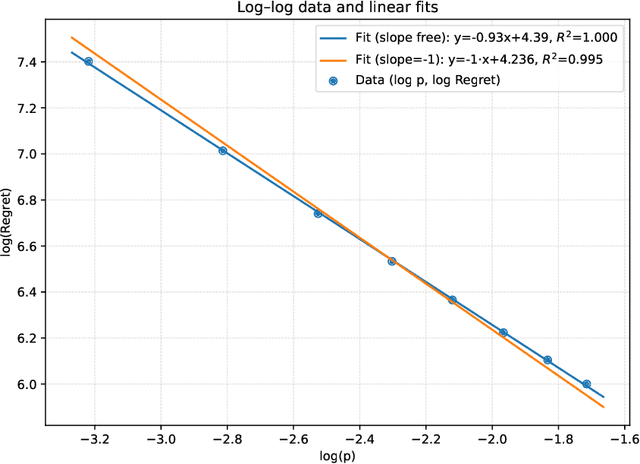
We study the distributed multi-agent multi-armed bandit problem with heterogeneous rewards over random communication graphs. Uniquely, at each time step $t$ agents communicate over a time-varying random graph $G_t$ generated by applying the Erd\H{o}s-R\'enyi model to a fixed connected base graph $G$ (for classical Erd\H{o}s-R\'enyi graphs, $G$ is a complete graph), where each potential edge in $G$ is randomly and independently present with the link probability $p$. Notably, the resulting random graph is not necessarily connected at each time step. Each agent's arm rewards follow time-invariant distributions, and the reward distribution for the same arm may differ across agents. The goal is to minimize the cumulative expected regret relative to the global mean reward of each arm, defined as the average of that arm's mean rewards across all agents. To this end, we propose a fully distributed algorithm that integrates the arm elimination strategy with the random gossip algorithm. We theoretically show that the regret upper bound is of order $\log T$ and is highly interpretable, where $T$ is the time horizon. It includes the optimal centralized regret $O\left(\sum_{k: \Delta_k>0} \frac{\log T}{\Delta_k}\right)$ and an additional term $O\left(\frac{N^2 \log T}{p \lambda_{N-1}(Lap(G))} + \frac{KN^2 \log T}{p}\right)$ where $N$ and $K$ denote the total number of agents and arms, respectively. This term reflects the impact of $G$'s algebraic connectivity $\lambda_{N-1}(Lap(G))$ and the link probability $p$, and thus highlights a fundamental trade-off between communication efficiency and regret. As a by-product, we show a nearly optimal regret lower bound. Finally, our numerical experiments not only show the superiority of our algorithm over existing benchmarks, but also validate the theoretical regret scaling with problem complexity.
LUIVITON: Learned Universal Interoperable VIrtual Try-ON
Sep 05, 2025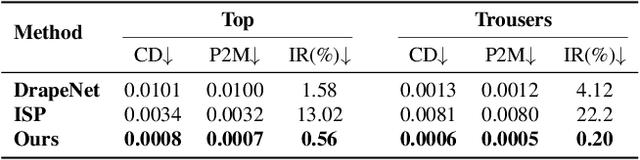
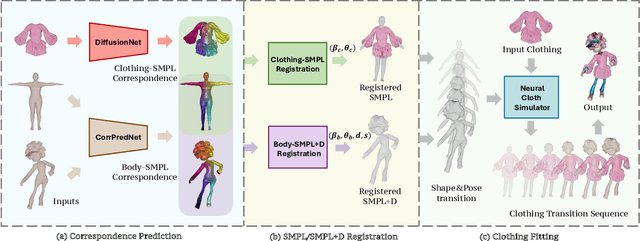
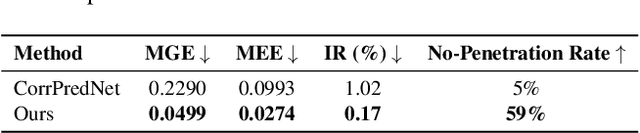
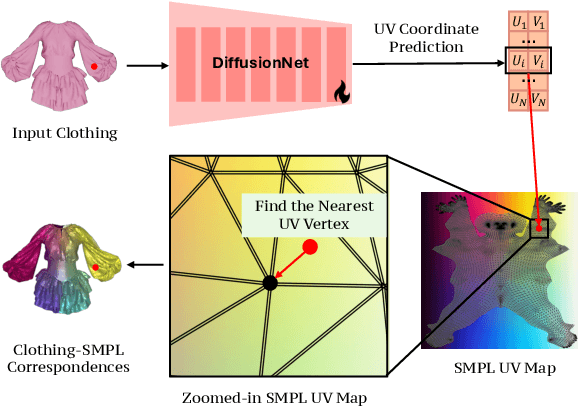
We present LUIVITON, an end-to-end system for fully automated virtual try-on, capable of draping complex, multi-layer clothing onto diverse and arbitrarily posed humanoid characters. To address the challenge of aligning complex garments with arbitrary and highly diverse body shapes, we use SMPL as a proxy representation and separate the clothing-to-body draping problem into two correspondence tasks: 1) clothing-to-SMPL and 2) body-to-SMPL correspondence, where each has its unique challenges. While we address the clothing-to-SMPL fitting problem using a geometric learning-based approach for partial-to-complete shape correspondence prediction, we introduce a diffusion model-based approach for body-to-SMPL correspondence using multi-view consistent appearance features and a pre-trained 2D foundation model. Our method can handle complex geometries, non-manifold meshes, and generalizes effectively to a wide range of humanoid characters -- including humans, robots, cartoon subjects, creatures, and aliens, while maintaining computational efficiency for practical adoption. In addition to offering a fully automatic fitting solution, LUIVITON supports fast customization of clothing size, allowing users to adjust clothing sizes and material properties after they have been draped. We show that our system can produce high-quality 3D clothing fittings without any human labor, even when 2D clothing sewing patterns are not available.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
Low-Barrier Dataset Collection with Real Human Body for Interactive Per-Garment Virtual Try-On
Jun 12, 2025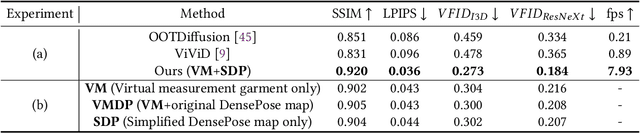


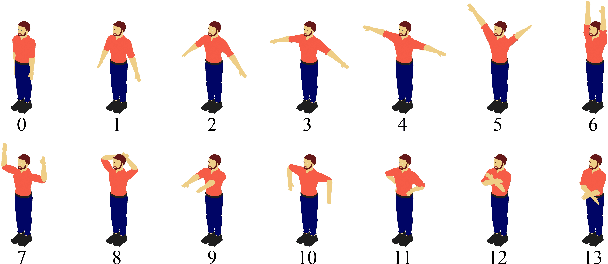
Existing image-based virtual try-on methods are often limited to the front view and lack real-time performance. While per-garment virtual try-on methods have tackled these issues by capturing per-garment datasets and training per-garment neural networks, they still encounter practical limitations: (1) the robotic mannequin used to capture per-garment datasets is prohibitively expensive for widespread adoption and fails to accurately replicate natural human body deformation; (2) the synthesized garments often misalign with the human body. To address these challenges, we propose a low-barrier approach for collecting per-garment datasets using real human bodies, eliminating the necessity for a customized robotic mannequin. We also introduce a hybrid person representation that enhances the existing intermediate representation with a simplified DensePose map. This ensures accurate alignment of synthesized garment images with the human body and enables human-garment interaction without the need for customized wearable devices. We performed qualitative and quantitative evaluations against other state-of-the-art image-based virtual try-on methods and conducted ablation studies to demonstrate the superiority of our method regarding image quality and temporal consistency. Finally, our user study results indicated that most participants found our virtual try-on system helpful for making garment purchasing decisions.
Offline Clustering of Linear Bandits: Unlocking the Power of Clusters in Data-Limited Environments
May 25, 2025Contextual linear multi-armed bandits are a learning framework for making a sequence of decisions, e.g., advertising recommendations for a sequence of arriving users. Recent works have shown that clustering these users based on the similarity of their learned preferences can significantly accelerate the learning. However, prior work has primarily focused on the online setting, which requires continually collecting user data, ignoring the offline data widely available in many applications. To tackle these limitations, we study the offline clustering of bandits (Off-ClusBand) problem, which studies how to use the offline dataset to learn cluster properties and improve decision-making across multiple users. The key challenge in Off-ClusBand arises from data insufficiency for users: unlike the online case, in the offline case, we have a fixed, limited dataset to work from and thus must determine whether we have enough data to confidently cluster users together. To address this challenge, we propose two algorithms: Off-C$^2$LUB, which we analytically show performs well for arbitrary amounts of user data, and Off-CLUB, which is prone to bias when data is limited but, given sufficient data, matches a theoretical lower bound that we derive for the offline clustered MAB problem. We experimentally validate these results on both real and synthetic datasets.
Kimi-VL Technical Report
Apr 10, 2025



We present Kimi-VL, an efficient open-source Mixture-of-Experts (MoE) vision-language model (VLM) that offers advanced multimodal reasoning, long-context understanding, and strong agent capabilities - all while activating only 2.8B parameters in its language decoder (Kimi-VL-A3B). Kimi-VL demonstrates strong performance across challenging domains: as a general-purpose VLM, Kimi-VL excels in multi-turn agent tasks (e.g., OSWorld), matching flagship models. Furthermore, it exhibits remarkable capabilities across diverse challenging vision language tasks, including college-level image and video comprehension, OCR, mathematical reasoning, and multi-image understanding. In comparative evaluations, it effectively competes with cutting-edge efficient VLMs such as GPT-4o-mini, Qwen2.5-VL-7B, and Gemma-3-12B-IT, while surpassing GPT-4o in several key domains. Kimi-VL also advances in processing long contexts and perceiving clearly. With a 128K extended context window, Kimi-VL can process diverse long inputs, achieving impressive scores of 64.5 on LongVideoBench and 35.1 on MMLongBench-Doc. Its native-resolution vision encoder, MoonViT, further allows it to see and understand ultra-high-resolution visual inputs, achieving 83.2 on InfoVQA and 34.5 on ScreenSpot-Pro, while maintaining lower computational cost for common tasks. Building upon Kimi-VL, we introduce an advanced long-thinking variant: Kimi-VL-Thinking. Developed through long chain-of-thought (CoT) supervised fine-tuning (SFT) and reinforcement learning (RL), this model exhibits strong long-horizon reasoning capabilities. It achieves scores of 61.7 on MMMU, 36.8 on MathVision, and 71.3 on MathVista while maintaining the compact 2.8B activated LLM parameters, setting a new standard for efficient multimodal thinking models. Code and models are publicly accessible at https://github.com/MoonshotAI/Kimi-VL.
Muon is Scalable for LLM Training
Feb 24, 2025Recently, the Muon optimizer based on matrix orthogonalization has demonstrated strong results in training small-scale language models, but the scalability to larger models has not been proven. We identify two crucial techniques for scaling up Muon: (1) adding weight decay and (2) carefully adjusting the per-parameter update scale. These techniques allow Muon to work out-of-the-box on large-scale training without the need of hyper-parameter tuning. Scaling law experiments indicate that Muon achieves $\sim\!2\times$ computational efficiency compared to AdamW with compute optimal training. Based on these improvements, we introduce Moonlight, a 3B/16B-parameter Mixture-of-Expert (MoE) model trained with 5.7T tokens using Muon. Our model improves the current Pareto frontier, achieving better performance with much fewer training FLOPs compared to prior models. We open-source our distributed Muon implementation that is memory optimal and communication efficient. We also release the pretrained, instruction-tuned, and intermediate checkpoints to support future research.