 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Particles: A 2D--3D Symmetric Garment Representation for Generation and Editing
May 27, 2026Practical garment design spans two modes: intuitive creation from high-level intent, such as a reference image or text description, and complex low-level editing across 2D sewing patterns and 3D draped geometry, which requires professional training to navigate their complex interdependencies. Yet existing frameworks address only part of this challenge, offering either garment generation from casual inputs or direct editing on sewing patterns. To support both ends of the spectrum, we propose Garment Particles, a 5D point-cloud representation that jointly encodes 2D sewing patterns and 3D geometry. This representation enables Garment Particles Flow (GPF), a rectified flow framework that supports intuitive generation from high-level inputs (text, images, sketches) and various editing operations on 2D sewing patterns and 3D geometries via diffusion posterior sampling. Finally, we introduce Particles-to-Pattern Flow that converts generated garment particles into curved-based patterns for simulation. We validate our model's generation ability on multiple datasets, achieving state-of-the-art garment generation results against competitive baselines. Our model also enables many garment editing scenarios, including garment interpolation, sewing pattern editing, point-cloud- and silhouette-conditioned garment generation. Our project website is at https://garment-particles.github.io .
Dropping Anchor and Spherical Harmonics for Sparse-view Gaussian Splatting
Feb 24, 2026Recent 3D Gaussian Splatting (3DGS) Dropout methods address overfitting under sparse-view conditions by randomly nullifying Gaussian opacities. However, we identify a neighbor compensation effect in these approaches: dropped Gaussians are often compensated by their neighbors, weakening the intended regularization. Moreover, these methods overlook the contribution of high-degree spherical harmonic coefficients (SH) to overfitting. To address these issues, we propose DropAnSH-GS, a novel anchor-based Dropout strategy. Rather than dropping Gaussians independently, our method randomly selects certain Gaussians as anchors and simultaneously removes their spatial neighbors. This effectively disrupts local redundancies near anchors and encourages the model to learn more robust, globally informed representations. Furthermore, we extend the Dropout to color attributes by randomly dropping higher-degree SH to concentrate appearance information in lower-degree SH. This strategy further mitigates overfitting and enables flexible post-training model compression via SH truncation. Experimental results demonstrate that DropAnSH-GS substantially outperforms existing Dropout methods with negligible computational overhead, and can be readily integrated into various 3DGS variants to enhance their performances. Project Website: https://sk-fun.fun/DropAnSH-GS
Real-Time Per-Garment Virtual Try-On with Temporal Consistency for Loose-Fitting Garments
Jun 14, 2025Per-garment virtual try-on methods collect garment-specific datasets and train networks tailored to each garment to achieve superior results. However, these approaches often struggle with loose-fitting garments due to two key limitations: (1) They rely on human body semantic maps to align garments with the body, but these maps become unreliable when body contours are obscured by loose-fitting garments, resulting in degraded outcomes; (2) They train garment synthesis networks on a per-frame basis without utilizing temporal information, leading to noticeable jittering artifacts. To address these challenges, we propose a two-stage approach for robust semantic map estimation. First, we extract a garment-invariant representation from the raw input image. This representation is then passed through an auxiliary network to estimate the semantic map. This enhances the robustness of semantic map estimation under loose-fitting garments during garment-specific dataset generation. Furthermore, we introduce a recurrent garment synthesis framework that incorporates temporal dependencies to improve frame-to-frame coherence while maintaining real-time performance. We conducted qualitative and quantitative evaluations to demonstrate that our method outperforms existing approaches in both image quality and temporal coherence. Ablation studies further validate the effectiveness of the garment-invariant representation and the recurrent synthesis framework.
Low-Barrier Dataset Collection with Real Human Body for Interactive Per-Garment Virtual Try-On
Jun 12, 2025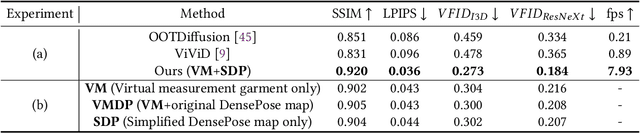


Existing image-based virtual try-on methods are often limited to the front view and lack real-time performance. While per-garment virtual try-on methods have tackled these issues by capturing per-garment datasets and training per-garment neural networks, they still encounter practical limitations: (1) the robotic mannequin used to capture per-garment datasets is prohibitively expensive for widespread adoption and fails to accurately replicate natural human body deformation; (2) the synthesized garments often misalign with the human body. To address these challenges, we propose a low-barrier approach for collecting per-garment datasets using real human bodies, eliminating the necessity for a customized robotic mannequin. We also introduce a hybrid person representation that enhances the existing intermediate representation with a simplified DensePose map. This ensures accurate alignment of synthesized garment images with the human body and enables human-garment interaction without the need for customized wearable devices. We performed qualitative and quantitative evaluations against other state-of-the-art image-based virtual try-on methods and conducted ablation studies to demonstrate the superiority of our method regarding image quality and temporal consistency. Finally, our user study results indicated that most participants found our virtual try-on system helpful for making garment purchasing decisions.
AutoSketch: VLM-assisted Style-Aware Vector Sketch Completion
Feb 07, 2025



The ability to automatically complete a partial sketch that depicts a complex scene, e.g., "a woman chatting with a man in the park", is very useful. However, existing sketch generation methods create sketches from scratch; they do not complete a partial sketch in the style of the original. To address this challenge, we introduce AutoSketch, a styleaware vector sketch completion method that accommodates diverse sketch styles. Our key observation is that the style descriptions of a sketch in natural language preserve the style during automatic sketch completion. Thus, we use a pretrained vision-language model (VLM) to describe the styles of the partial sketches in natural language and replicate these styles using newly generated strokes. We initially optimize the strokes to match an input prompt augmented by style descriptions extracted from the VLM. Such descriptions allow the method to establish a diffusion prior in close alignment with that of the partial sketch. Next, we utilize the VLM to generate an executable style adjustment code that adjusts the strokes to conform to the desired style. We compare our method with existing methods across various sketch styles and prompts, performed extensive ablation studies and qualitative and quantitative evaluations, and demonstrate that AutoSketch can support various sketch scenarios.
FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
Mar 11, 2024Acquiring the desired font for various design tasks can be challenging and requires professional typographic knowledge. While previous font retrieval or generation works have alleviated some of these difficulties, they often lack support for multiple languages and semantic attributes beyond the training data domains. To solve this problem, we present FontCLIP: a model that connects the semantic understanding of a large vision-language model with typographical knowledge. We integrate typography-specific knowledge into the comprehensive vision-language knowledge of a pretrained CLIP model through a novel finetuning approach. We propose to use a compound descriptive prompt that encapsulates adaptively sampled attributes from a font attribute dataset focusing on Roman alphabet characters. FontCLIP's semantic typographic latent space demonstrates two unprecedented generalization abilities. First, FontCLIP generalizes to different languages including Chinese, Japanese, and Korean (CJK), capturing the typographical features of fonts across different languages, even though it was only finetuned using fonts of Roman characters. Second, FontCLIP can recognize the semantic attributes that are not presented in the training data. FontCLIP's dual-modality and generalization abilities enable multilingual and cross-lingual font retrieval and letter shape optimization, reducing the burden of obtaining desired fonts.
NeRF-In: Free-Form NeRF Inpainting with RGB-D Priors
Jun 10, 2022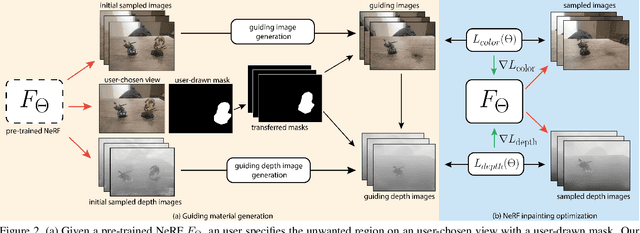
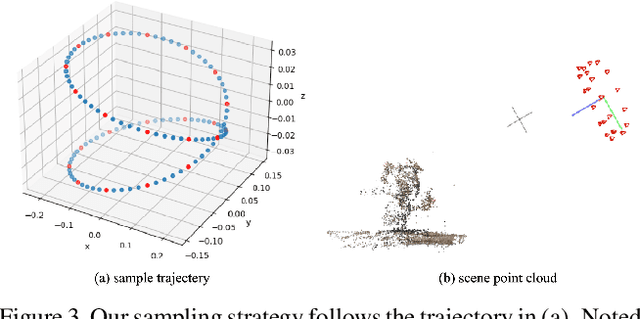


Though Neural Radiance Field (NeRF) demonstrates compelling novel view synthesis results, it is still unintuitive to edit a pre-trained NeRF because the neural network's parameters and the scene geometry/appearance are often not explicitly associated. In this paper, we introduce the first framework that enables users to remove unwanted objects or retouch undesired regions in a 3D scene represented by a pre-trained NeRF without any category-specific data and training. The user first draws a free-form mask to specify a region containing unwanted objects over a rendered view from the pre-trained NeRF. Our framework first transfers the user-provided mask to other rendered views and estimates guiding color and depth images within these transferred masked regions. Next, we formulate an optimization problem that jointly inpaints the image content in all masked regions across multiple views by updating the NeRF model's parameters. We demonstrate our framework on diverse scenes and show it obtained visual plausible and structurally consistent results across multiple views using shorter time and less user manual efforts.
AutoPoly: Predicting a Polygonal Mesh Construction Sequence from a Silhouette Image
Mar 29, 2022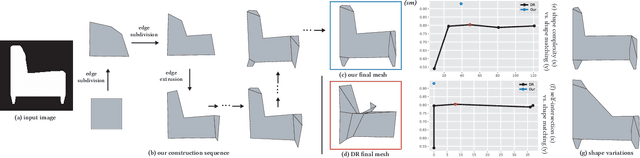
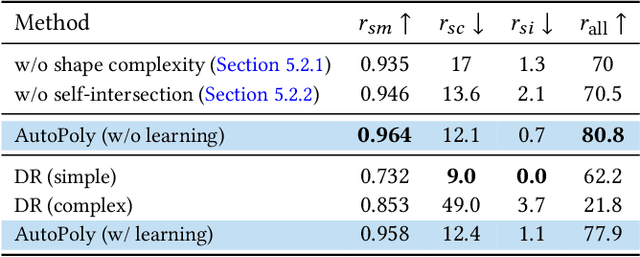
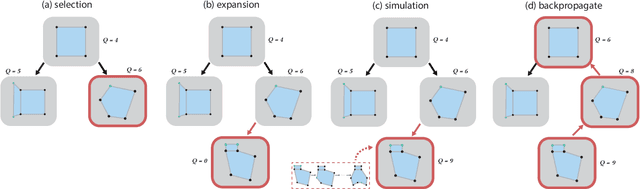
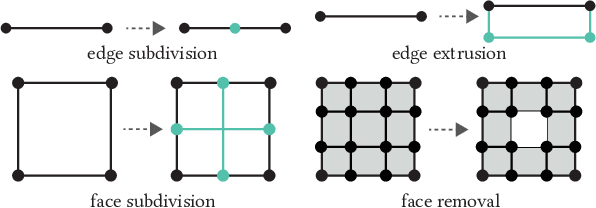
Polygonal modeling is a core task of content creation in Computer Graphics. The complexity of modeling, in terms of the number and the order of operations and time required to execute them makes it challenging to learn and execute. Our goal is to automatically derive a polygonal modeling sequence for a given target. Then, one can learn polygonal modeling by observing the resulting sequence and also expedite the modeling process by starting from the auto-generated result. As a starting point for building a system for 3D modeling in the future, we tackle the 2D shape modeling problem and present AutoPoly, a hybrid method that generates a polygonal mesh construction sequence from a silhouette image. The key idea of our method is the use of the Monte Carlo tree search (MCTS) algorithm and differentiable rendering to separately predict sequential topological actions and geometric actions. Our hybrid method can alter topology, whereas the recently proposed inverse shape estimation methods using differentiable rendering can only handle a fixed topology. Our novel reward function encourages MCTS to select topological actions that lead to a simpler shape without self-intersection. We further designed two deep learning-based methods to improve the expansion and simulation steps in the MCTS search process: an $n$-step "future action prediction" network (nFAP-Net) to generate candidates for potential topological actions, and a shape warping network (WarpNet) to predict polygonal shapes given the predicted rendered images and topological actions. We demonstrate the efficiency of our method on 2D polygonal shapes of multiple man-made object categories.
StylePart: Image-based Shape Part Manipulation
Nov 23, 2021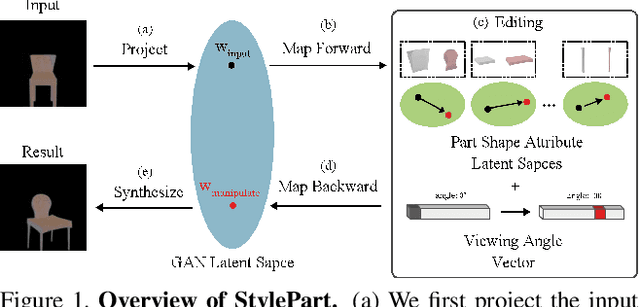
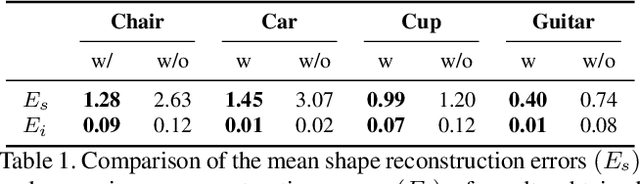
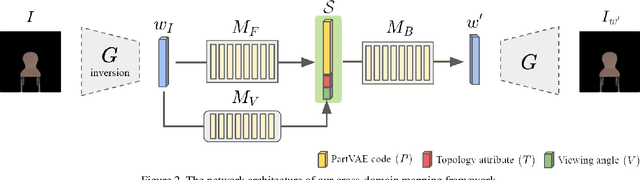

Due to a lack of image-based "part controllers", shape manipulation of man-made shape images, such as resizing the backrest of a chair or replacing a cup handle is not intuitive. To tackle this problem, we present StylePart, a framework that enables direct shape manipulation of an image by leveraging generative models of both images and 3D shapes. Our key contribution is a shape-consistent latent mapping function that connects the image generative latent space and the 3D man-made shape attribute latent space. Our method "forwardly maps" the image content to its corresponding 3D shape attributes, where the shape part can be easily manipulated. The attribute codes of the manipulated 3D shape are then "backwardly mapped" to the image latent code to obtain the final manipulated image. We demonstrate our approach through various manipulation tasks, including part replacement, part resizing, and viewpoint manipulation, and evaluate its effectiveness through extensive ablation studies.
Per Garment Capture and Synthesis for Real-time Virtual Try-on
Sep 10, 2021
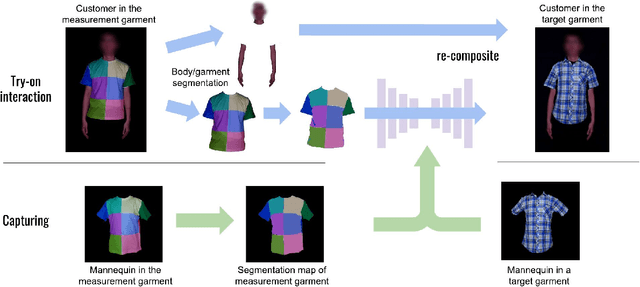


Virtual try-on is a promising application of computer graphics and human computer interaction that can have a profound real-world impact especially during this pandemic. Existing image-based works try to synthesize a try-on image from a single image of a target garment, but it inherently limits the ability to react to possible interactions. It is difficult to reproduce the change of wrinkles caused by pose and body size change, as well as pulling and stretching of the garment by hand. In this paper, we propose an alternative per garment capture and synthesis workflow to handle such rich interactions by training the model with many systematically captured images. Our workflow is composed of two parts: garment capturing and clothed person image synthesis. We designed an actuated mannequin and an efficient capturing process that collects the detailed deformations of the target garments under diverse body sizes and poses. Furthermore, we proposed to use a custom-designed measurement garment, and we captured paired images of the measurement garment and the target garments. We then learn a mapping between the measurement garment and the target garments using deep image-to-image translation. The customer can then try on the target garments interactively during online shopping.