 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGarment Particles: A 2D--3D Symmetric Garment Representation for Generation and Editing
May 27, 2026Practical garment design spans two modes: intuitive creation from high-level intent, such as a reference image or text description, and complex low-level editing across 2D sewing patterns and 3D draped geometry, which requires professional training to navigate their complex interdependencies. Yet existing frameworks address only part of this challenge, offering either garment generation from casual inputs or direct editing on sewing patterns. To support both ends of the spectrum, we propose Garment Particles, a 5D point-cloud representation that jointly encodes 2D sewing patterns and 3D geometry. This representation enables Garment Particles Flow (GPF), a rectified flow framework that supports intuitive generation from high-level inputs (text, images, sketches) and various editing operations on 2D sewing patterns and 3D geometries via diffusion posterior sampling. Finally, we introduce Particles-to-Pattern Flow that converts generated garment particles into curved-based patterns for simulation. We validate our model's generation ability on multiple datasets, achieving state-of-the-art garment generation results against competitive baselines. Our model also enables many garment editing scenarios, including garment interpolation, sewing pattern editing, point-cloud- and silhouette-conditioned garment generation. Our project website is at https://garment-particles.github.io .
Dropping Anchor and Spherical Harmonics for Sparse-view Gaussian Splatting
Feb 24, 2026Recent 3D Gaussian Splatting (3DGS) Dropout methods address overfitting under sparse-view conditions by randomly nullifying Gaussian opacities. However, we identify a neighbor compensation effect in these approaches: dropped Gaussians are often compensated by their neighbors, weakening the intended regularization. Moreover, these methods overlook the contribution of high-degree spherical harmonic coefficients (SH) to overfitting. To address these issues, we propose DropAnSH-GS, a novel anchor-based Dropout strategy. Rather than dropping Gaussians independently, our method randomly selects certain Gaussians as anchors and simultaneously removes their spatial neighbors. This effectively disrupts local redundancies near anchors and encourages the model to learn more robust, globally informed representations. Furthermore, we extend the Dropout to color attributes by randomly dropping higher-degree SH to concentrate appearance information in lower-degree SH. This strategy further mitigates overfitting and enables flexible post-training model compression via SH truncation. Experimental results demonstrate that DropAnSH-GS substantially outperforms existing Dropout methods with negligible computational overhead, and can be readily integrated into various 3DGS variants to enhance their performances. Project Website: https://sk-fun.fun/DropAnSH-GS
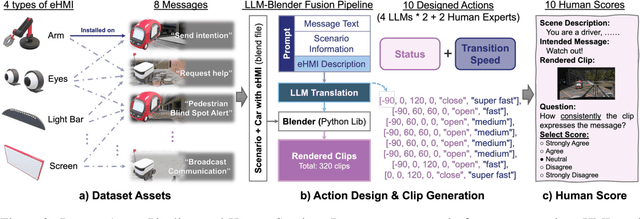
See2Refine: Vision-Language Feedback Improves LLM-Based eHMI Action Designers
Feb 02, 2026Automated vehicles lack natural communication channels with other road users, making external Human-Machine Interfaces (eHMIs) essential for conveying intent and maintaining trust in shared environments. However, most eHMI studies rely on developer-crafted message-action pairs, which are difficult to adapt to diverse and dynamic traffic contexts. A promising alternative is to use Large Language Models (LLMs) as action designers that generate context-conditioned eHMI actions, yet such designers lack perceptual verification and typically depend on fixed prompts or costly human-annotated feedback for improvement. We present See2Refine, a human-free, closed-loop framework that uses vision-language model (VLM) perceptual evaluation as automated visual feedback to improve an LLM-based eHMI action designer. Given a driving context and a candidate eHMI action, the VLM evaluates the perceived appropriateness of the action, and this feedback is used to iteratively revise the designer's outputs, enabling systematic refinement without human supervision. We evaluate our framework across three eHMI modalities (lightbar, eyes, and arm) and multiple LLM model sizes. Across settings, our framework consistently outperforms prompt-only LLM designers and manually specified baselines in both VLM-based metrics and human-subject evaluations. Results further indicate that the improvements generalize across modalities and that VLM evaluations are well aligned with human preferences, supporting the robustness and effectiveness of See2Refine for scalable action design.
Real-Time Per-Garment Virtual Try-On with Temporal Consistency for Loose-Fitting Garments
Jun 14, 2025Per-garment virtual try-on methods collect garment-specific datasets and train networks tailored to each garment to achieve superior results. However, these approaches often struggle with loose-fitting garments due to two key limitations: (1) They rely on human body semantic maps to align garments with the body, but these maps become unreliable when body contours are obscured by loose-fitting garments, resulting in degraded outcomes; (2) They train garment synthesis networks on a per-frame basis without utilizing temporal information, leading to noticeable jittering artifacts. To address these challenges, we propose a two-stage approach for robust semantic map estimation. First, we extract a garment-invariant representation from the raw input image. This representation is then passed through an auxiliary network to estimate the semantic map. This enhances the robustness of semantic map estimation under loose-fitting garments during garment-specific dataset generation. Furthermore, we introduce a recurrent garment synthesis framework that incorporates temporal dependencies to improve frame-to-frame coherence while maintaining real-time performance. We conducted qualitative and quantitative evaluations to demonstrate that our method outperforms existing approaches in both image quality and temporal coherence. Ablation studies further validate the effectiveness of the garment-invariant representation and the recurrent synthesis framework.
Low-Barrier Dataset Collection with Real Human Body for Interactive Per-Garment Virtual Try-On
Jun 12, 2025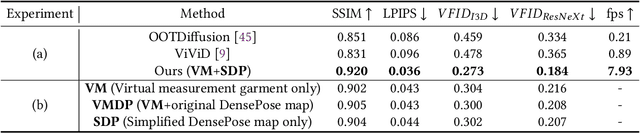


Existing image-based virtual try-on methods are often limited to the front view and lack real-time performance. While per-garment virtual try-on methods have tackled these issues by capturing per-garment datasets and training per-garment neural networks, they still encounter practical limitations: (1) the robotic mannequin used to capture per-garment datasets is prohibitively expensive for widespread adoption and fails to accurately replicate natural human body deformation; (2) the synthesized garments often misalign with the human body. To address these challenges, we propose a low-barrier approach for collecting per-garment datasets using real human bodies, eliminating the necessity for a customized robotic mannequin. We also introduce a hybrid person representation that enhances the existing intermediate representation with a simplified DensePose map. This ensures accurate alignment of synthesized garment images with the human body and enables human-garment interaction without the need for customized wearable devices. We performed qualitative and quantitative evaluations against other state-of-the-art image-based virtual try-on methods and conducted ablation studies to demonstrate the superiority of our method regarding image quality and temporal consistency. Finally, our user study results indicated that most participants found our virtual try-on system helpful for making garment purchasing decisions.
Automating eHMI Action Design with LLMs for Automated Vehicle Communication
May 27, 2025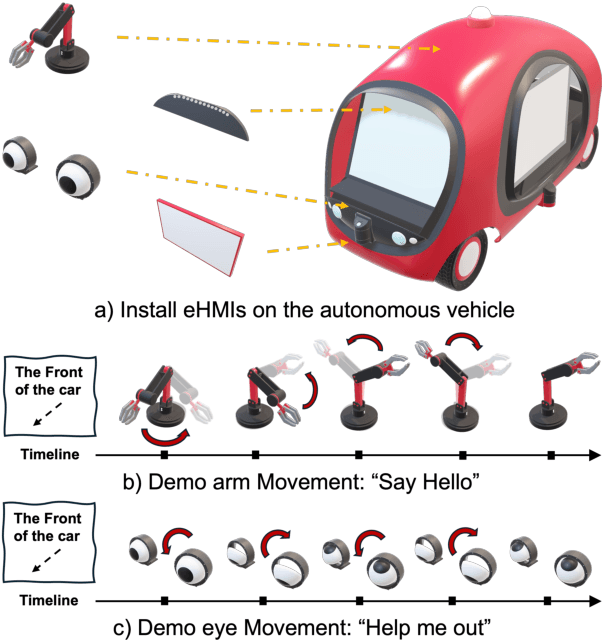

The absence of explicit communication channels between automated vehicles (AVs) and other road users requires the use of external Human-Machine Interfaces (eHMIs) to convey messages effectively in uncertain scenarios. Currently, most eHMI studies employ predefined text messages and manually designed actions to perform these messages, which limits the real-world deployment of eHMIs, where adaptability in dynamic scenarios is essential. Given the generalizability and versatility of large language models (LLMs), they could potentially serve as automated action designers for the message-action design task. To validate this idea, we make three contributions: (1) We propose a pipeline that integrates LLMs and 3D renderers, using LLMs as action designers to generate executable actions for controlling eHMIs and rendering action clips. (2) We collect a user-rated Action-Design Scoring dataset comprising a total of 320 action sequences for eight intended messages and four representative eHMI modalities. The dataset validates that LLMs can translate intended messages into actions close to a human level, particularly for reasoning-enabled LLMs. (3) We introduce two automated raters, Action Reference Score (ARS) and Vision-Language Models (VLMs), to benchmark 18 LLMs, finding that the VLM aligns with human preferences yet varies across eHMI modalities.
Proactive Conversational Agents with Inner Thoughts
Dec 31, 2024One of the long-standing aspirations in conversational AI is to allow them to autonomously take initiatives in conversations, i.e., being proactive. This is especially challenging for multi-party conversations. Prior NLP research focused mainly on predicting the next speaker from contexts like preceding conversations. In this paper, we demonstrate the limitations of such methods and rethink what it means for AI to be proactive in multi-party, human-AI conversations. We propose that just like humans, rather than merely reacting to turn-taking cues, a proactive AI formulates its own inner thoughts during a conversation, and seeks the right moment to contribute. Through a formative study with 24 participants and inspiration from linguistics and cognitive psychology, we introduce the Inner Thoughts framework. Our framework equips AI with a continuous, covert train of thoughts in parallel to the overt communication process, which enables it to proactively engage by modeling its intrinsic motivation to express these thoughts. We instantiated this framework into two real-time systems: an AI playground web app and a chatbot. Through a technical evaluation and user studies with human participants, our framework significantly surpasses existing baselines on aspects like anthropomorphism, coherence, intelligence, and turn-taking appropriateness.
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jul 10, 2024



Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
Automatic Dance Video Segmentation for Understanding Choreography
May 30, 2024Segmenting dance video into short movements is a popular way to easily understand dance choreography. However, it is currently done manually and requires a significant amount of effort by experts. That is, even if many dance videos are available on social media (e.g., TikTok and YouTube), it remains difficult for people, especially novices, to casually watch short video segments to practice dance choreography. In this paper, we propose a method to automatically segment a dance video into each movement. Given a dance video as input, we first extract visual and audio features: the former is computed from the keypoints of the dancer in the video, and the latter is computed from the Mel spectrogram of the music in the video. Next, these features are passed to a Temporal Convolutional Network (TCN), and segmentation points are estimated by picking peaks of the network output. To build our training dataset, we annotate segmentation points to dance videos in the AIST Dance Video Database, which is a shared database containing original street dance videos with copyright-cleared dance music. The evaluation study shows that the proposed method (i.e., combining the visual and audio features) can estimate segmentation points with high accuracy. In addition, we developed an application to help dancers practice choreography using the proposed method.
FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
Mar 11, 2024Acquiring the desired font for various design tasks can be challenging and requires professional typographic knowledge. While previous font retrieval or generation works have alleviated some of these difficulties, they often lack support for multiple languages and semantic attributes beyond the training data domains. To solve this problem, we present FontCLIP: a model that connects the semantic understanding of a large vision-language model with typographical knowledge. We integrate typography-specific knowledge into the comprehensive vision-language knowledge of a pretrained CLIP model through a novel finetuning approach. We propose to use a compound descriptive prompt that encapsulates adaptively sampled attributes from a font attribute dataset focusing on Roman alphabet characters. FontCLIP's semantic typographic latent space demonstrates two unprecedented generalization abilities. First, FontCLIP generalizes to different languages including Chinese, Japanese, and Korean (CJK), capturing the typographical features of fonts across different languages, even though it was only finetuned using fonts of Roman characters. Second, FontCLIP can recognize the semantic attributes that are not presented in the training data. FontCLIP's dual-modality and generalization abilities enable multilingual and cross-lingual font retrieval and letter shape optimization, reducing the burden of obtaining desired fonts.