 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAPPI: Interactive Optimization with LLM-Assisted Preference-Based Problem Instantiation
Dec 16, 2025Many real-world tasks, such as trip planning or meal planning, can be formulated as combinatorial optimization problems. However, using optimization solvers is difficult for end users because it requires problem instantiation: defining candidate items, assigning preference scores, and specifying constraints. We introduce LAPPI (LLM-Assisted Preference-based Problem Instantiation), an interactive approach that uses large language models (LLMs) to support users in this instantiation process. Through natural language conversations, the system helps users transform vague preferences into well-defined optimization problems. These instantiated problems are then passed to existing optimization solvers to generate solutions. In a user study on trip planning, our method successfully captured user preferences and generated feasible plans that outperformed both conventional and prompt-engineering approaches. We further demonstrate LAPPI's versatility by adapting it to an additional use case.
Constrained Preferential Bayesian Optimization and Its Application in Banner Ad Design
May 16, 2025Preferential Bayesian optimization (PBO) is a variant of Bayesian optimization that observes relative preferences (e.g., pairwise comparisons) instead of direct objective values, making it especially suitable for human-in-the-loop scenarios. However, real-world optimization tasks often involve inequality constraints, which existing PBO methods have not yet addressed. To fill this gap, we propose constrained preferential Bayesian optimization (CPBO), an extension of PBO that incorporates inequality constraints for the first time. Specifically, we present a novel acquisition function for this purpose. Our technical evaluation shows that our CPBO method successfully identifies optimal solutions by focusing on exploring feasible regions. As a practical application, we also present a designer-in-the-loop system for banner ad design using CPBO, where the objective is the designer's subjective preference, and the constraint ensures a target predicted click-through rate. We conducted a user study with professional ad designers, demonstrating the potential benefits of our approach in guiding creative design under real-world constraints.
* 17 pages, 15 figures
FontCLIP: A Semantic Typography Visual-Language Model for Multilingual Font Applications
Mar 11, 2024Acquiring the desired font for various design tasks can be challenging and requires professional typographic knowledge. While previous font retrieval or generation works have alleviated some of these difficulties, they often lack support for multiple languages and semantic attributes beyond the training data domains. To solve this problem, we present FontCLIP: a model that connects the semantic understanding of a large vision-language model with typographical knowledge. We integrate typography-specific knowledge into the comprehensive vision-language knowledge of a pretrained CLIP model through a novel finetuning approach. We propose to use a compound descriptive prompt that encapsulates adaptively sampled attributes from a font attribute dataset focusing on Roman alphabet characters. FontCLIP's semantic typographic latent space demonstrates two unprecedented generalization abilities. First, FontCLIP generalizes to different languages including Chinese, Japanese, and Korean (CJK), capturing the typographical features of fonts across different languages, even though it was only finetuned using fonts of Roman characters. Second, FontCLIP can recognize the semantic attributes that are not presented in the training data. FontCLIP's dual-modality and generalization abilities enable multilingual and cross-lingual font retrieval and letter shape optimization, reducing the burden of obtaining desired fonts.
Vitreoretinal Surgical Robotic System with Autonomous Orbital Manipulation using Vector-Field Inequalities
Feb 11, 2023Vitreoretinal surgery pertains to the treatment of delicate tissues on the fundus of the eye using thin instruments. Surgeons frequently rotate the eye during surgery, which is called orbital manipulation, to observe regions around the fundus without moving the patient. In this paper, we propose the autonomous orbital manipulation of the eye in robot-assisted vitreoretinal surgery with our tele-operated surgical system. In a simulation study, we preliminarily investigated the increase in the manipulability of our system using orbital manipulation. Furthermore, we demonstrated the feasibility of our method in experiments with a physical robot and a realistic eye model, showing an increase in the view-able area of the fundus when compared to a conventional technique. Source code and minimal example available at https://github.com/mmmarinho/icra2023_orbitalmanipulation.
A Structure-Guided Diffusion Model for Large-Hole Diverse Image Completion
Nov 18, 2022

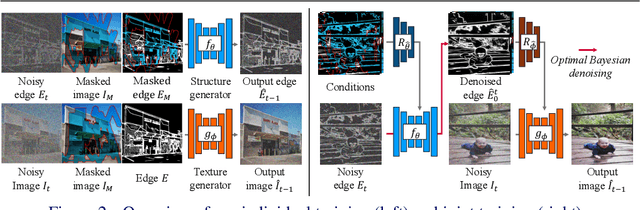

Diverse image completion, a problem of generating various ways of filling incomplete regions (i.e. holes) of an image, has made remarkable success. However, managing input images with large holes is still a challenging problem due to the corruption of semantically important structures. In this paper, we tackle this problem by incorporating explicit structural guidance. We propose a structure-guided diffusion model (SGDM) for the large-hole diverse completion problem. Our proposed SGDM consists of a structure generator and a texture generator, which are both diffusion probabilistic models (DMs). The structure generator generates an edge image representing a plausible structure within the holes, which is later used to guide the texture generation process. To jointly train these two generators, we design a strategy that combines optimal Bayesian denoising and a momentum framework. In addition to the quality improvement, auxiliary edge images generated by the structure generator can be manually edited to allow user-guided image editing. Our experiments using datasets of faces (CelebA-HQ) and natural scenes (Places) show that our method achieves a comparable or superior trade-off between visual quality and diversity compared to other state-of-the-art methods.
Autonomous Coordinated Control of the Light Guide for Positioning in Vitreoretinal Surgery
Jul 26, 2021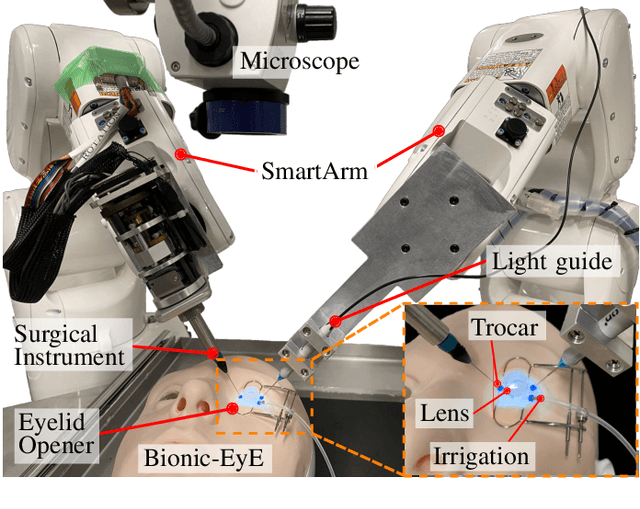
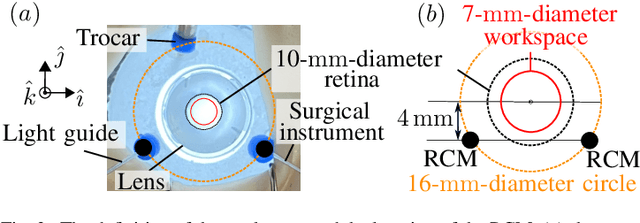
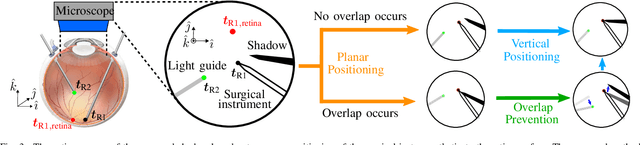
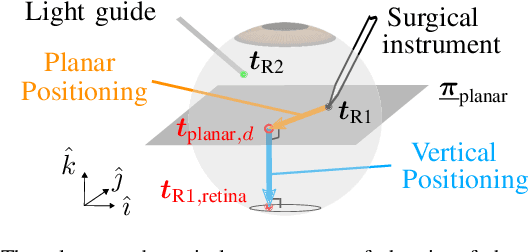
Vitreoretinal surgery is challenging even for expert surgeons owing to the delicate target tissues and the diminutive 7-mm-diameter workspace in the retina. In addition to improved dexterity and accuracy, robot assistance allows for (partial) task automation. In this work, we propose a strategy to automate the motion of the light guide with respect to the surgical instrument. This automation allows the instrument's shadow to always be inside the microscopic view, which is an important cue for the accurate positioning of the instrument in the retina. We show simulations and experiments demonstrating that the proposed strategy is effective in a 700-point grid in the retina of a surgical phantom.
Tool- and Domain-Agnostic Parameterization of Style Transfer Effects Leveraging Pretrained Perceptual Metrics
May 19, 2021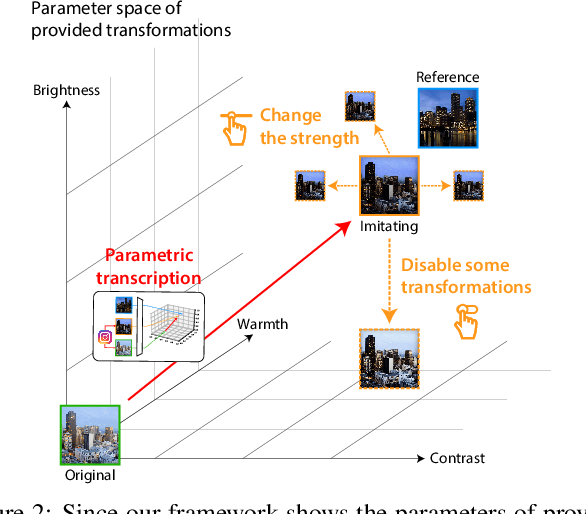


Current deep learning techniques for style transfer would not be optimal for design support since their "one-shot" transfer does not fit exploratory design processes. To overcome this gap, we propose parametric transcription, which transcribes an end-to-end style transfer effect into parameter values of specific transformations available in an existing content editing tool. With this approach, users can imitate the style of a reference sample in the tool that they are familiar with and thus can easily continue further exploration by manipulating the parameters. To enable this, we introduce a framework that utilizes an existing pretrained model for style transfer to calculate a perceptual style distance to the reference sample and uses black-box optimization to find the parameters that minimize this distance. Our experiments with various third-party tools, such as Instagram and Blender, show that our framework can effectively leverage deep learning techniques for computational design support.
Sequential Gallery for Interactive Visual Design Optimization
May 08, 2020
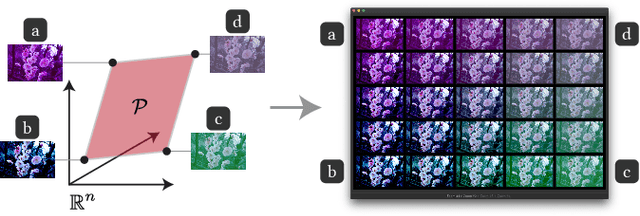


Visual design tasks often involve tuning many design parameters. For example, color grading of a photograph involves many parameters, some of which non-expert users might be unfamiliar with. We propose a novel user-in-the-loop optimization method that allows users to efficiently find an appropriate parameter set by exploring such a high-dimensional design space through much easier two-dimensional search subtasks. This method, called sequential plane search, is based on Bayesian optimization to keep necessary queries to users as few as possible. To help users respond to plane-search queries, we also propose using a gallery-based interface that provides options in the two-dimensional subspace arranged in an adaptive grid view. We call this interactive framework Sequential Gallery since users sequentially select the best option from the options provided by the interface. Our experiment with synthetic functions shows that our sequential plane search can find satisfactory solutions in fewer iterations than baselines. We also conducted a preliminary user study, results of which suggest that novices can effectively complete search tasks with Sequential Gallery in a photo-enhancement scenario.
* To be published at ACM Trans. Graph. (Proc. SIGGRAPH 2020); Project page available at https://koyama.xyz/project/sequential_gallery/
MirrorNet: A Deep Bayesian Approach to Reflective 2D Pose Estimation from Human Images
Apr 08, 2020

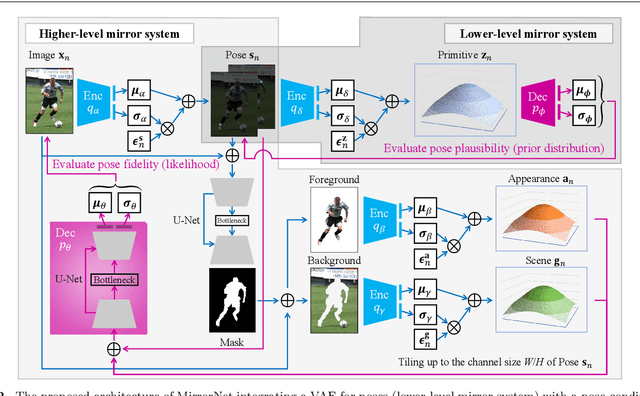
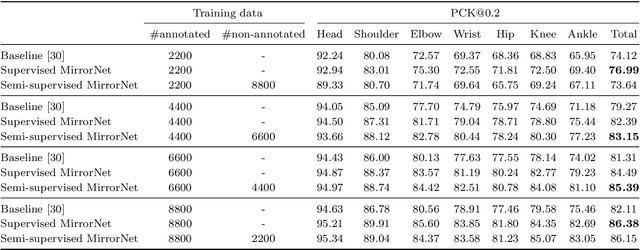
This paper proposes a statistical approach to 2D pose estimation from human images. The main problems with the standard supervised approach, which is based on a deep recognition (image-to-pose) model, are that it often yields anatomically implausible poses, and its performance is limited by the amount of paired data. To solve these problems, we propose a semi-supervised method that can make effective use of images with and without pose annotations. Specifically, we formulate a hierarchical generative model of poses and images by integrating a deep generative model of poses from pose features with that of images from poses and image features. We then introduce a deep recognition model that infers poses from images. Given images as observed data, these models can be trained jointly in a hierarchical variational autoencoding (image-to-pose-to-feature-to-pose-to-image) manner. The results of experiments show that the proposed reflective architecture makes estimated poses anatomically plausible, and the performance of pose estimation improved by integrating the recognition and generative models and also by feeding non-annotated images.
Computational Design with Crowds
Feb 20, 2020


Computational design is aimed at supporting or automating design processes using computational techniques. However, some classes of design tasks involve criteria that are difficult to handle only with computers. For example, visual design tasks seeking to fulfill aesthetic goals are difficult to handle purely with computers. One promising approach is to leverage human computation; that is, to incorporate human input into the computation process. Crowdsourcing platforms provide a convenient way to integrate such human computation into a working system. In this chapter, we discuss such computational design with crowds in the domain of parameter tweaking tasks in visual design. Parameter tweaking is often performed to maximize the aesthetic quality of designed objects. Computational design powered by crowds can solve this maximization problem by leveraging human computation. We discuss the opportunities and challenges of computational design with crowds with two illustrative examples: (1) estimating the objective function (specifically, preference learning from crowds' pairwise comparisons) to facilitate interactive design exploration by a designer and (2) directly searching for the optimal parameter setting that maximizes the objective function (specifically, crowds-in-the-loop Bayesian optimization).
* This book chapter was originally published in Computational Interaction edited by Antti Oulasvirta, Per Ola Kristensson, Xiaojun Bi, and Andrew Howes