 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiveSVG: Zero-Shot SVG Animation via Video Generation
May 28, 2026We introduce LiveSVG, a zero-shot approach for generating Scalable Vector Graphics (SVG) animations using video diffusion models. Current SVG animation methods struggle with complex motions: LLM-based code synthesis fails to express fine, non-rigid Bézier deformations, while Score Distillation Sampling (SDS) provides noisy gradients and often requires category-specific priors like skeletons. In contrast, LiveSVG fits vector geometry directly to an explicitly generated target video. Given an input SVG image and a motion prompt, we generate a previewable target video using a frozen image-to-video model, then fit the original SVG to this video via differentiable rendering. Our fitting stage is skeleton-free, utilizing a dual-level motion representation that combines per-group homographies for coarse articulation with per-path Bézier control-point offsets for local deformations. To resolve color-induced correspondence ambiguities during pixel-wise fitting, we introduce a novel sphere-packing recolorization strategy. We also present ChallengeSVG, a benchmark of complex, multi-object scenes that exposes the limitations of prior work. Evaluations demonstrate that LiveSVG significantly outperforms existing methods on both AniClipart and ChallengeSVG, establishing direct reference-video fitting as a practical, robust route to prompt-aligned and fully editable vector animation.
Progressive Photorealistic Simplification
May 11, 2026Existing image simplification techniques often rely on Non-Photorealistic Rendering (NPR), transforming photographs into stylized sketches, cartoons, or paintings. While effective at reducing visual complexity, such approaches typically sacrifice photographic realism. In this work, we explore a complementary direction: simplifying images while preserving their photorealistic appearance. We introduce progressive semantic image simplification, a framework that iteratively reduces scene complexity by removing and inpainting elements in a controlled manner. At each step, the resulting image remains a plausible natural photograph. Our method combines semantic understanding with generative editing, leveraging Vision-Language Models (VLMs) to identify and prioritize elements for removal, and a learned verifier to ensure photorealism and coherence throughout the process. This is implemented via an iterative Select-Remove-Verify pipeline that produces high-quality simplification trajectories. To improve efficiency, we further distill this process into an image-to-video generation model that directly predicts coherent simplification sequences from a single input image. Beyond generating cleaner and more focused compositions, our approach enables applications such as content-aware decluttering, semantic layer decomposition, and interactive editing. More broadly, our work suggests that simplification through structured content removal can serve as a practical mechanism for guiding visual interpretation within the photorealistic domain, complementing traditional abstraction methods.
Mocap Anywhere: Towards Pairwise-Distance based Motion Capture in the Wild (for the Wild)
Jan 27, 2026We introduce a novel motion capture system that reconstructs full-body 3D motion using only sparse pairwise distance (PWD) measurements from body-mounted(UWB) sensors. Using time-of-flight ranging between wireless nodes, our method eliminates the need for external cameras, enabling robust operation in uncontrolled and outdoor environments. Unlike traditional optical or inertial systems, our approach is shape-invariant and resilient to environmental constraints such as lighting and magnetic interference. At the core of our system is Wild-Poser (WiP for short), a compact, real-time Transformer-based architecture that directly predicts 3D joint positions from noisy or corrupted PWD measurements, which can later be used for joint rotation reconstruction via learned methods. WiP generalizes across subjects of varying morphologies, including non-human species, without requiring individual body measurements or shape fitting. Operating in real time, WiP achieves low joint position error and demonstrates accurate 3D motion reconstruction for both human and animal subjects in-the-wild. Our empirical analysis highlights its potential for scalable, low-cost, and general purpose motion capture in real-world settings.
Alterbute: Editing Intrinsic Attributes of Objects in Images
Jan 15, 2026We introduce Alterbute, a diffusion-based method for editing an object's intrinsic attributes in an image. We allow changing color, texture, material, and even the shape of an object, while preserving its perceived identity and scene context. Existing approaches either rely on unsupervised priors that often fail to preserve identity or use overly restrictive supervision that prevents meaningful intrinsic variations. Our method relies on: (i) a relaxed training objective that allows the model to change both intrinsic and extrinsic attributes conditioned on an identity reference image, a textual prompt describing the target intrinsic attributes, and a background image and object mask defining the extrinsic context. At inference, we restrict extrinsic changes by reusing the original background and object mask, thereby ensuring that only the desired intrinsic attributes are altered; (ii) Visual Named Entities (VNEs) - fine-grained visual identity categories (e.g., ''Porsche 911 Carrera'') that group objects sharing identity-defining features while allowing variation in intrinsic attributes. We use a vision-language model to automatically extract VNE labels and intrinsic attribute descriptions from a large public image dataset, enabling scalable, identity-preserving supervision. Alterbute outperforms existing methods on identity-preserving object intrinsic attribute editing.
Neural Image Abstraction Using Long Smoothing B-Splines
Nov 07, 2025We integrate smoothing B-splines into a standard differentiable vector graphics (DiffVG) pipeline through linear mapping, and show how this can be used to generate smooth and arbitrarily long paths within image-based deep learning systems. We take advantage of derivative-based smoothing costs for parametric control of fidelity vs. simplicity tradeoffs, while also enabling stylization control in geometric and image spaces. The proposed pipeline is compatible with recent vector graphics generation and vectorization methods. We demonstrate the versatility of our approach with four applications aimed at the generation of stylized vector graphics: stylized space-filling path generation, stroke-based image abstraction, closed-area image abstraction, and stylized text generation.
Mono4DEditor: Text-Driven 4D Scene Editing from Monocular Video via Point-Level Localization of Language-Embedded Gaussians
Oct 10, 2025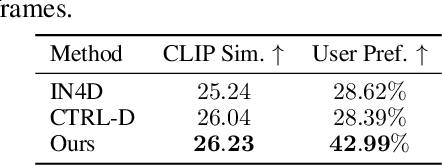
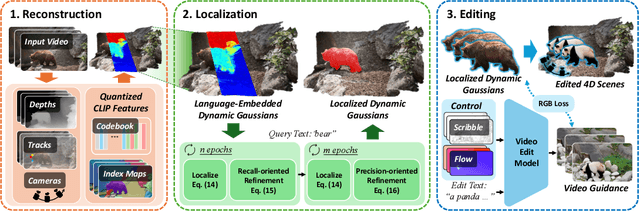
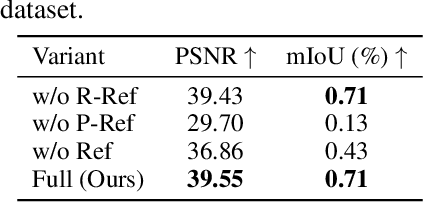

Editing 4D scenes reconstructed from monocular videos based on text prompts is a valuable yet challenging task with broad applications in content creation and virtual environments. The key difficulty lies in achieving semantically precise edits in localized regions of complex, dynamic scenes, while preserving the integrity of unedited content. To address this, we introduce Mono4DEditor, a novel framework for flexible and accurate text-driven 4D scene editing. Our method augments 3D Gaussians with quantized CLIP features to form a language-embedded dynamic representation, enabling efficient semantic querying of arbitrary spatial regions. We further propose a two-stage point-level localization strategy that first selects candidate Gaussians via CLIP similarity and then refines their spatial extent to improve accuracy. Finally, targeted edits are performed on localized regions using a diffusion-based video editing model, with flow and scribble guidance ensuring spatial fidelity and temporal coherence. Extensive experiments demonstrate that Mono4DEditor enables high-quality, text-driven edits across diverse scenes and object types, while preserving the appearance and geometry of unedited areas and surpassing prior approaches in both flexibility and visual fidelity.
LightLab: Controlling Light Sources in Images with Diffusion Models
May 14, 2025We present a simple, yet effective diffusion-based method for fine-grained, parametric control over light sources in an image. Existing relighting methods either rely on multiple input views to perform inverse rendering at inference time, or fail to provide explicit control over light changes. Our method fine-tunes a diffusion model on a small set of real raw photograph pairs, supplemented by synthetically rendered images at scale, to elicit its photorealistic prior for relighting. We leverage the linearity of light to synthesize image pairs depicting controlled light changes of either a target light source or ambient illumination. Using this data and an appropriate fine-tuning scheme, we train a model for precise illumination changes with explicit control over light intensity and color. Lastly, we show how our method can achieve compelling light editing results, and outperforms existing methods based on user preference.
REED-VAE: RE-Encode Decode Training for Iterative Image Editing with Diffusion Models
Apr 26, 2025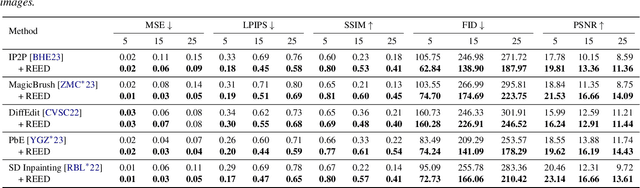



While latent diffusion models achieve impressive image editing results, their application to iterative editing of the same image is severely restricted. When trying to apply consecutive edit operations using current models, they accumulate artifacts and noise due to repeated transitions between pixel and latent spaces. Some methods have attempted to address this limitation by performing the entire edit chain within the latent space, sacrificing flexibility by supporting only a limited, predetermined set of diffusion editing operations. We present a RE-encode decode (REED) training scheme for variational autoencoders (VAEs), which promotes image quality preservation even after many iterations. Our work enables multi-method iterative image editing: users can perform a variety of iterative edit operations, with each operation building on the output of the previous one using both diffusion-based operations and conventional editing techniques. We demonstrate the advantage of REED-VAE across a range of image editing scenarios, including text-based and mask-based editing frameworks. In addition, we show how REED-VAE enhances the overall editability of images, increasing the likelihood of successful and precise edit operations. We hope that this work will serve as a benchmark for the newly introduced task of multi-method image editing. Our code and models will be available at https://github.com/galmog/REED-VAE
MASH: Masked Anchored SpHerical Distances for 3D Shape Representation and Generation
Apr 12, 2025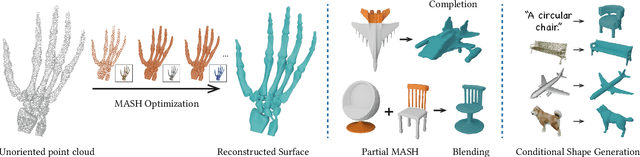
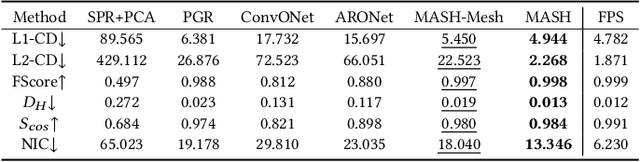
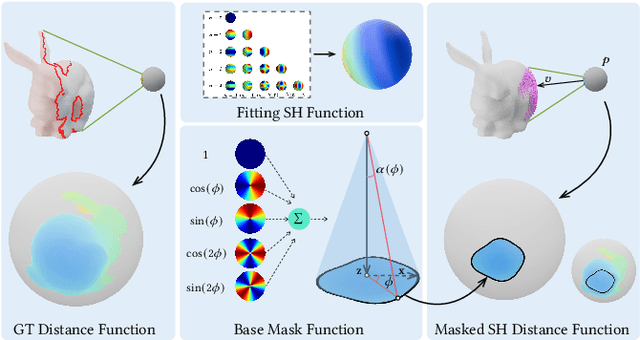

We introduce Masked Anchored SpHerical Distances (MASH), a novel multi-view and parametrized representation of 3D shapes. Inspired by multi-view geometry and motivated by the importance of perceptual shape understanding for learning 3D shapes, MASH represents a 3D shape as a collection of observable local surface patches, each defined by a spherical distance function emanating from an anchor point. We further leverage the compactness of spherical harmonics to encode the MASH functions, combined with a generalized view cone with a parameterized base that masks the spatial extent of the spherical function to attain locality. We develop a differentiable optimization algorithm capable of converting any point cloud into a MASH representation accurately approximating ground-truth surfaces with arbitrary geometry and topology. Extensive experiments demonstrate that MASH is versatile for multiple applications including surface reconstruction, shape generation, completion, and blending, achieving superior performance thanks to its unique representation encompassing both implicit and explicit features.
SwiftSketch: A Diffusion Model for Image-to-Vector Sketch Generation
Feb 12, 2025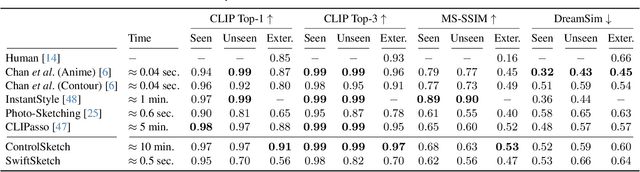
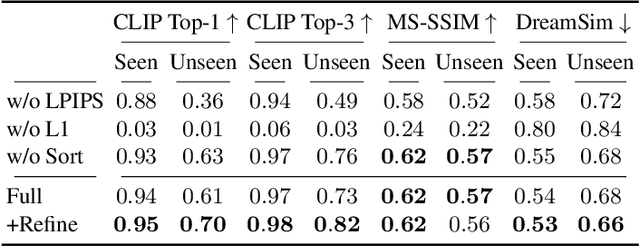
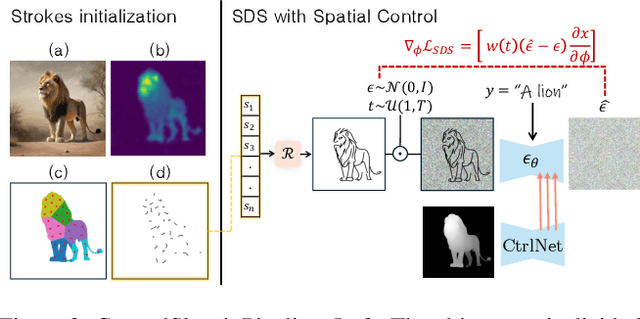
Recent advancements in large vision-language models have enabled highly expressive and diverse vector sketch generation. However, state-of-the-art methods rely on a time-consuming optimization process involving repeated feedback from a pretrained model to determine stroke placement. Consequently, despite producing impressive sketches, these methods are limited in practical applications. In this work, we introduce SwiftSketch, a diffusion model for image-conditioned vector sketch generation that can produce high-quality sketches in less than a second. SwiftSketch operates by progressively denoising stroke control points sampled from a Gaussian distribution. Its transformer-decoder architecture is designed to effectively handle the discrete nature of vector representation and capture the inherent global dependencies between strokes. To train SwiftSketch, we construct a synthetic dataset of image-sketch pairs, addressing the limitations of existing sketch datasets, which are often created by non-artists and lack professional quality. For generating these synthetic sketches, we introduce ControlSketch, a method that enhances SDS-based techniques by incorporating precise spatial control through a depth-aware ControlNet. We demonstrate that SwiftSketch generalizes across diverse concepts, efficiently producing sketches that combine high fidelity with a natural and visually appealing style.