 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAC: Pronunciation-Aware Contextualized Large Language Model-based Automatic Speech Recognition
Sep 16, 2025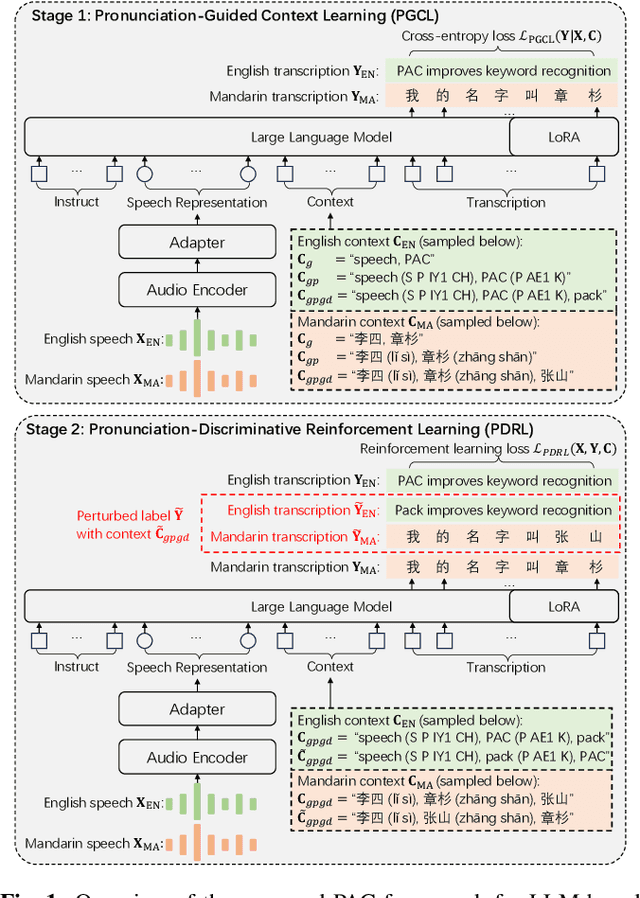
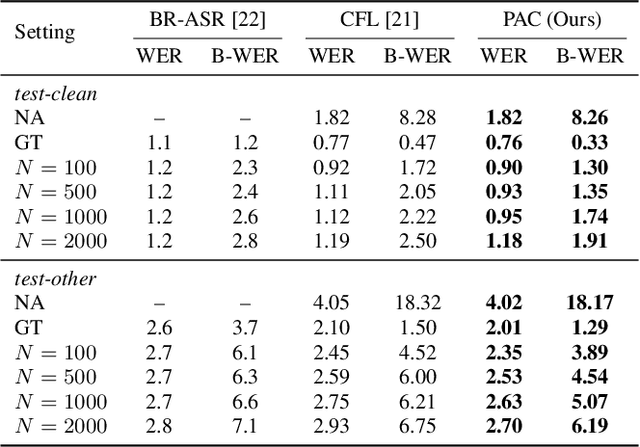
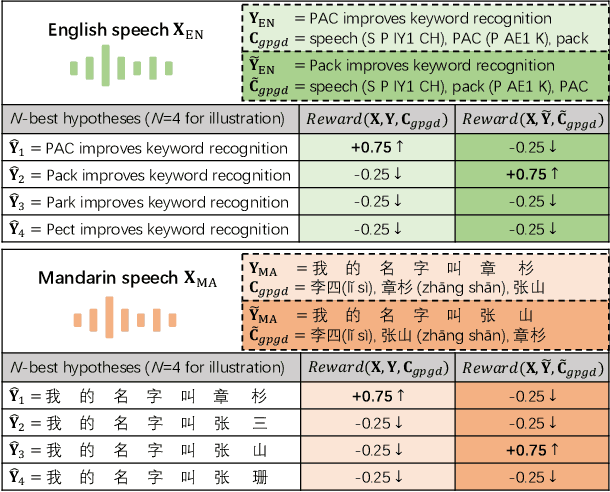
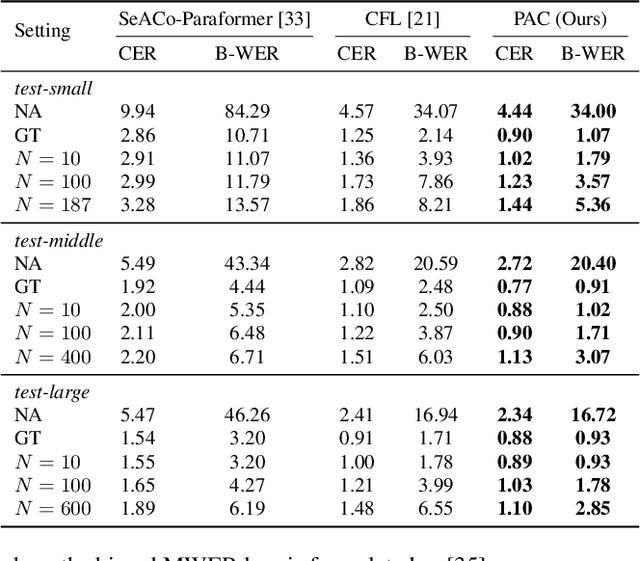
This paper presents a Pronunciation-Aware Contextualized (PAC) framework to address two key challenges in Large Language Model (LLM)-based Automatic Speech Recognition (ASR) systems: effective pronunciation modeling and robust homophone discrimination. Both are essential for raw or long-tail word recognition. The proposed approach adopts a two-stage learning paradigm. First, we introduce a pronunciation-guided context learning method. It employs an interleaved grapheme-phoneme context modeling strategy that incorporates grapheme-only distractors, encouraging the model to leverage phonemic cues for accurate recognition. Then, we propose a pronunciation-discriminative reinforcement learning method with perturbed label sampling to further enhance the model\'s ability to distinguish contextualized homophones. Experimental results on the public English Librispeech and Mandarin AISHELL-1 datasets indicate that PAC: (1) reduces relative Word Error Rate (WER) by 30.2% and 53.8% compared to pre-trained LLM-based ASR models, and (2) achieves 31.8% and 60.5% relative reductions in biased WER for long-tail words compared to strong baselines, respectively.
Bridging Theory and Experiment in Materials Discovery: Machine-Learning-Assisted Prediction of Synthesizable Structures
May 14, 2025Even though thermodynamic energy-based crystal structure prediction (CSP) has revolutionized materials discovery, the energy-driven CSP approaches often struggle to identify experimentally realizable metastable materials synthesized through kinetically controlled pathways, creating a critical gap between theoretical predictions and experimental synthesis. Here, we propose a synthesizability-driven CSP framework that integrates symmetry-guided structure derivation with a Wyckoff encode-based machine-learning model, allowing for the efficient localization of subspaces likely to yield highly synthesizable structures. Within the identified promising subspaces, a structure-based synthesizability evaluation model, fine-tuned using recently synthesized structures to enhance predictive accuracy, is employed in conjunction with ab initio calculations to systematically identify synthesizable candidates. The framework successfully reproduces 13 experimentally known XSe (X = Sc, Ti, Mn, Fe, Ni, Cu, Zn) structures, demonstrating its effectiveness in predicting synthesizable structures. Notably, 92,310 structures are filtered from the 554,054 candidates predicted by GNoME, exhibiting great potential for promising synthesizability. Additionally, eight thermodynamically favorable Hf-X-O (X = Ti, V, and Mn) structures have been identified, among which three HfV$_2$O$_7$ candidates exhibit high synthesizability, presenting viable candidates for experimental realization and potentially associated with experimentally observed temperature-induced phase transitions. This work establishes a data-driven paradigm for machine-learning-assisted inorganic materials synthesis, highlighting its potential to bridge the gap between computational predictions and experimental realization while unlocking new opportunities for the targeted discovery of novel functional materials.
FBRT-YOLO: Faster and Better for Real-Time Aerial Image Detection
Apr 29, 2025Embedded flight devices with visual capabilities have become essential for a wide range of applications. In aerial image detection, while many existing methods have partially addressed the issue of small target detection, challenges remain in optimizing small target detection and balancing detection accuracy with efficiency. These issues are key obstacles to the advancement of real-time aerial image detection. In this paper, we propose a new family of real-time detectors for aerial image detection, named FBRT-YOLO, to address the imbalance between detection accuracy and efficiency. Our method comprises two lightweight modules: Feature Complementary Mapping Module (FCM) and Multi-Kernel Perception Unit(MKP), designed to enhance object perception for small targets in aerial images. FCM focuses on alleviating the problem of information imbalance caused by the loss of small target information in deep networks. It aims to integrate spatial positional information of targets more deeply into the network,better aligning with semantic information in the deeper layers to improve the localization of small targets. We introduce MKP, which leverages convolutions with kernels of different sizes to enhance the relationships between targets of various scales and improve the perception of targets at different scales. Extensive experimental results on three major aerial image datasets, including Visdrone, UAVDT, and AI-TOD,demonstrate that FBRT-YOLO outperforms various real-time detectors in terms of performance and speed.
MASH: Masked Anchored SpHerical Distances for 3D Shape Representation and Generation
Apr 12, 2025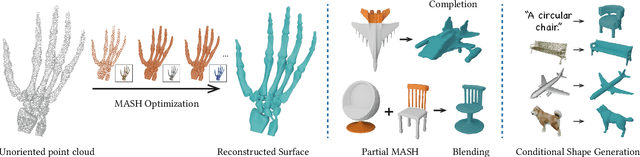
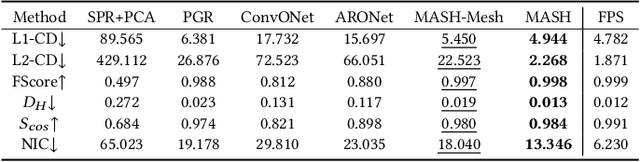
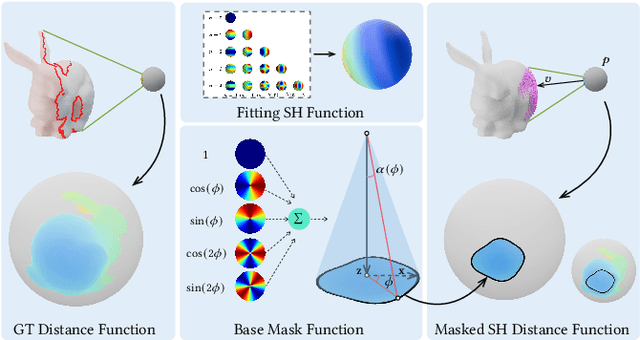

We introduce Masked Anchored SpHerical Distances (MASH), a novel multi-view and parametrized representation of 3D shapes. Inspired by multi-view geometry and motivated by the importance of perceptual shape understanding for learning 3D shapes, MASH represents a 3D shape as a collection of observable local surface patches, each defined by a spherical distance function emanating from an anchor point. We further leverage the compactness of spherical harmonics to encode the MASH functions, combined with a generalized view cone with a parameterized base that masks the spatial extent of the spherical function to attain locality. We develop a differentiable optimization algorithm capable of converting any point cloud into a MASH representation accurately approximating ground-truth surfaces with arbitrary geometry and topology. Extensive experiments demonstrate that MASH is versatile for multiple applications including surface reconstruction, shape generation, completion, and blending, achieving superior performance thanks to its unique representation encompassing both implicit and explicit features.
Med3DVLM: An Efficient Vision-Language Model for 3D Medical Image Analysis
Mar 25, 2025Vision-language models (VLMs) have shown promise in 2D medical image analysis, but extending them to 3D remains challenging due to the high computational demands of volumetric data and the difficulty of aligning 3D spatial features with clinical text. We present Med3DVLM, a 3D VLM designed to address these challenges through three key innovations: (1) DCFormer, an efficient encoder that uses decomposed 3D convolutions to capture fine-grained spatial features at scale; (2) SigLIP, a contrastive learning strategy with pairwise sigmoid loss that improves image-text alignment without relying on large negative batches; and (3) a dual-stream MLP-Mixer projector that fuses low- and high-level image features with text embeddings for richer multi-modal representations. We evaluate our model on the M3D dataset, which includes radiology reports and VQA data for 120,084 3D medical images. Results show that Med3DVLM achieves superior performance across multiple benchmarks. For image-text retrieval, it reaches 61.00% R@1 on 2,000 samples, significantly outperforming the current state-of-the-art M3D model (19.10%). For report generation, it achieves a METEOR score of 36.42% (vs. 14.38%). In open-ended visual question answering (VQA), it scores 36.76% METEOR (vs. 33.58%), and in closed-ended VQA, it achieves 79.95% accuracy (vs. 75.78%). These results highlight Med3DVLM's ability to bridge the gap between 3D imaging and language, enabling scalable, multi-task reasoning across clinical applications. Our code is publicly available at https://github.com/mirthAI/Med3DVLM.
ArticulatedGS: Self-supervised Digital Twin Modeling of Articulated Objects using 3D Gaussian Splatting
Mar 11, 2025



We tackle the challenge of concurrent reconstruction at the part level with the RGB appearance and estimation of motion parameters for building digital twins of articulated objects using the 3D Gaussian Splatting (3D-GS) method. With two distinct sets of multi-view imagery, each depicting an object in separate static articulation configurations, we reconstruct the articulated object in 3D Gaussian representations with both appearance and geometry information at the same time. Our approach decoupled multiple highly interdependent parameters through a multi-step optimization process, thereby achieving a stable optimization procedure and high-quality outcomes. We introduce ArticulatedGS, a self-supervised, comprehensive framework that autonomously learns to model shapes and appearances at the part level and synchronizes the optimization of motion parameters, all without reliance on 3D supervision, motion cues, or semantic labels. Our experimental results demonstrate that, among comparable methodologies, our approach has achieved optimal outcomes in terms of part segmentation accuracy, motion estimation accuracy, and visual quality.
Zero-Shot Hashing Based on Reconstruction With Part Alignment
Mar 10, 2025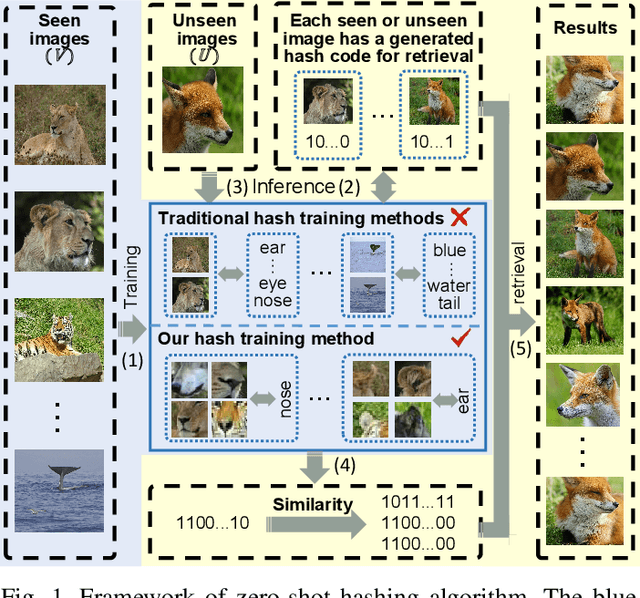
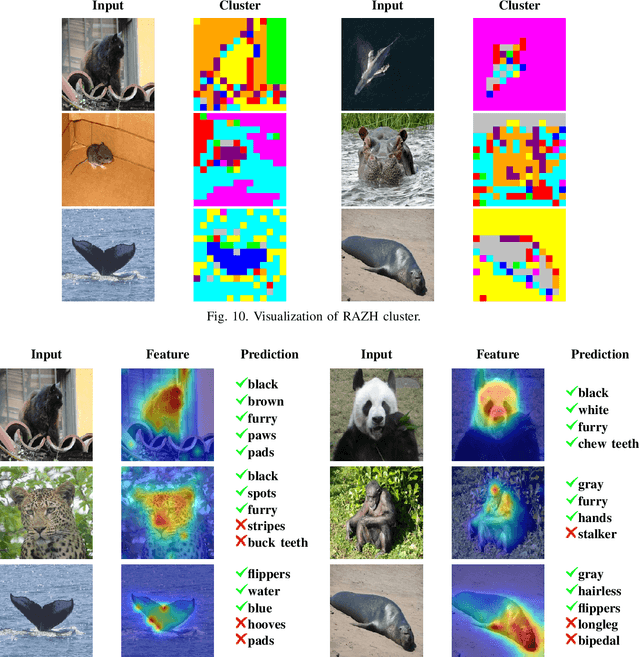
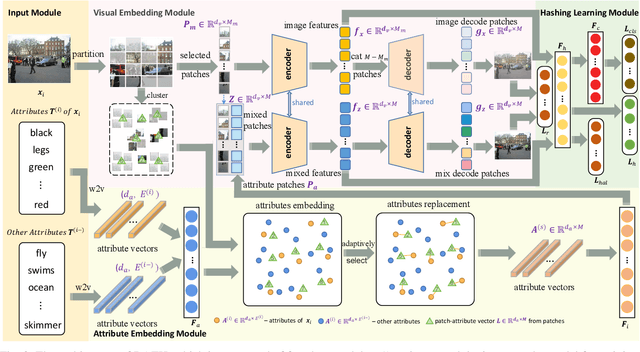
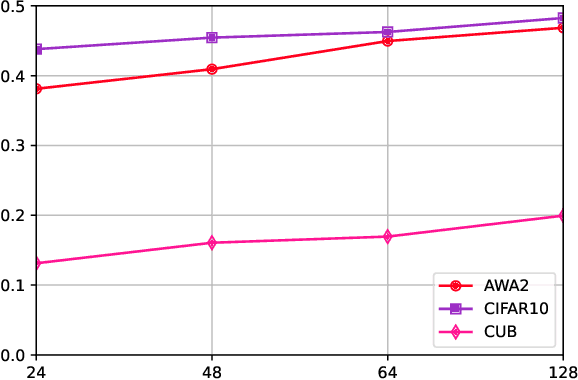
Hashing algorithms have been widely used in large-scale image retrieval tasks, especially for seen class data. Zero-shot hashing algorithms have been proposed to handle unseen class data. The key technique in these algorithms involves learning features from seen classes and transferring them to unseen classes, that is, aligning the feature embeddings between the seen and unseen classes. Most existing zero-shot hashing algorithms use the shared attributes between the two classes of interest to complete alignment tasks. However, the attributes are always described for a whole image, even though they represent specific parts of the image. Hence, these methods ignore the importance of aligning attributes with the corresponding image parts, which explicitly introduces noise and reduces the accuracy achieved when aligning the features of seen and unseen classes. To address this problem, we propose a new zero-shot hashing method called RAZH. We first use a clustering algorithm to group similar patches to image parts for attribute matching and then replace the image parts with the corresponding attribute vectors, gradually aligning each part with its nearest attribute. Extensive evaluation results demonstrate the superiority of the RAZH method over several state-of-the-art methods.
BATseg: Boundary-aware Multiclass Spinal Cord Tumor Segmentation on 3D MRI Scans
Dec 09, 2024Spinal cord tumors significantly contribute to neurological morbidity and mortality. Precise morphometric quantification, encompassing the size, location, and type of such tumors, holds promise for optimizing treatment planning strategies. Although recent methods have demonstrated excellent performance in medical image segmentation, they primarily focus on discerning shapes with relatively large morphology such as brain tumors, ignoring the challenging problem of identifying spinal cord tumors which tend to have tiny sizes, diverse locations, and shapes. To tackle this hard problem of multiclass spinal cord tumor segmentation, we propose a new method, called BATseg, to learn a tumor surface distance field by applying our new multiclass boundary-aware loss function. To verify the effectiveness of our approach, we also introduce the first and large-scale spinal cord tumor dataset. It comprises gadolinium-enhanced T1-weighted 3D MRI scans from 653 patients and contains the four most common spinal cord tumor types: astrocytomas, ependymomas, hemangioblastomas, and spinal meningiomas. Extensive experiments on our dataset and another public kidney tumor segmentation dataset show that our proposed method achieves superior performance for multiclass tumor segmentation.
Symphony: Optimized Model Serving using Centralized Orchestration
Aug 14, 2023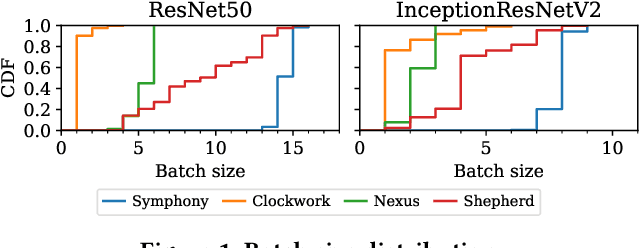
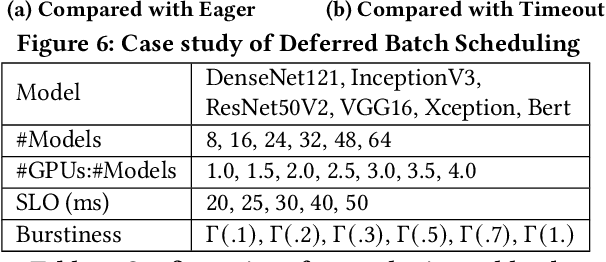
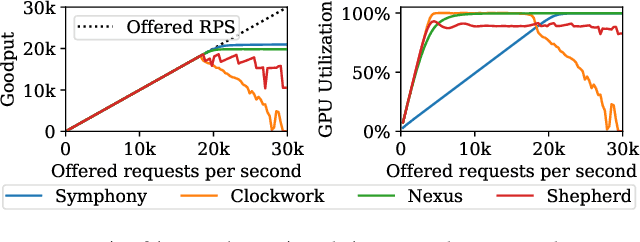
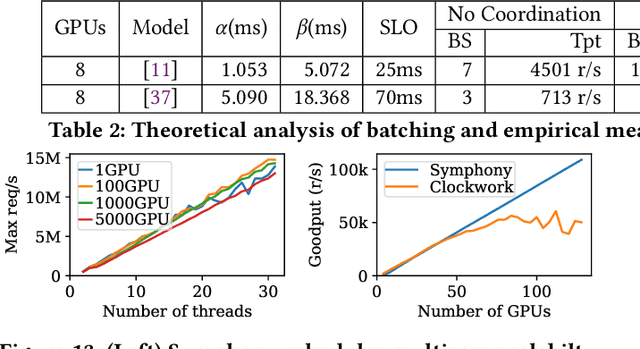
The orchestration of deep neural network (DNN) model inference on GPU clusters presents two significant challenges: achieving high accelerator efficiency given the batching properties of model inference while meeting latency service level objectives (SLOs), and adapting to workload changes both in terms of short-term fluctuations and long-term resource allocation. To address these challenges, we propose Symphony, a centralized scheduling system that can scale to millions of requests per second and coordinate tens of thousands of GPUs. Our system utilizes a non-work-conserving scheduling algorithm capable of achieving high batch efficiency while also enabling robust autoscaling. Additionally, we developed an epoch-scale algorithm that allocates models to sub-clusters based on the compute and memory needs of the models. Through extensive experiments, we demonstrate that Symphony outperforms prior systems by up to 4.7x higher goodput.
NeRF synthesis with shading guidance
Jun 20, 2023



The emerging Neural Radiance Field (NeRF) shows great potential in representing 3D scenes, which can render photo-realistic images from novel view with only sparse views given. However, utilizing NeRF to reconstruct real-world scenes requires images from different viewpoints, which limits its practical application. This problem can be even more pronounced for large scenes. In this paper, we introduce a new task called NeRF synthesis that utilizes the structural content of a NeRF patch exemplar to construct a new radiance field of large size. We propose a two-phase method for synthesizing new scenes that are continuous in geometry and appearance. We also propose a boundary constraint method to synthesize scenes of arbitrary size without artifacts. Specifically, we control the lighting effects of synthesized scenes using shading guidance instead of decoupling the scene. We have demonstrated that our method can generate high-quality results with consistent geometry and appearance, even for scenes with complex lighting. We can also synthesize new scenes on curved surface with arbitrary lighting effects, which enhances the practicality of our proposed NeRF synthesis approach.