 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Generate Reliable Test Case Generators? A Study on Competition-Level Programming Problems
Jun 07, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in code generation, capable of tackling complex tasks during inference. However, the extent to which LLMs can be utilized for code checking or debugging through test case generation remains largely unexplored. We investigate this problem from the perspective of competition-level programming (CP) programs and propose TCGBench, a Benchmark for (LLM generation of) Test Case Generators. This benchmark comprises two tasks, aimed at studying the capabilities of LLMs in (1) generating valid test case generators for a given CP problem, and further (2) generating targeted test case generators that expose bugs in human-written code. Experimental results indicate that while state-of-the-art LLMs can generate valid test case generators in most cases, most LLMs struggle to generate targeted test cases that reveal flaws in human code effectively. Especially, even advanced reasoning models (e.g., o3-mini) fall significantly short of human performance in the task of generating targeted generators. Furthermore, we construct a high-quality, manually curated dataset of instructions for generating targeted generators. Analysis demonstrates that the performance of LLMs can be enhanced with the aid of this dataset, by both prompting and fine-tuning.
LLM4FS: Leveraging Large Language Models for Feature Selection and How to Improve It
Mar 31, 2025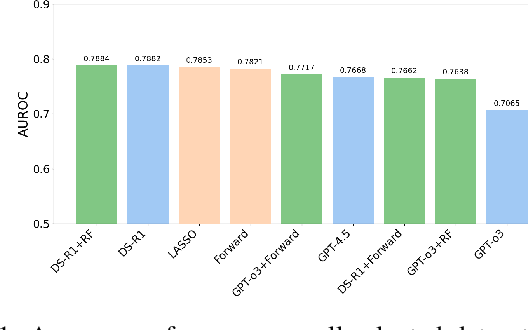
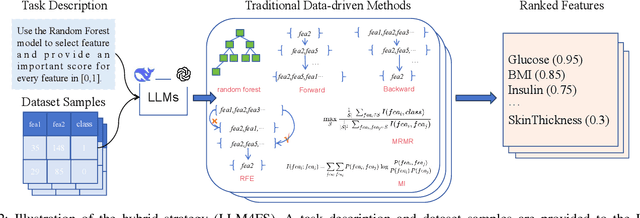
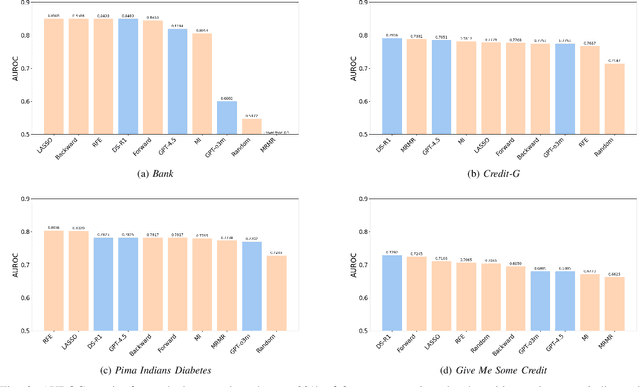
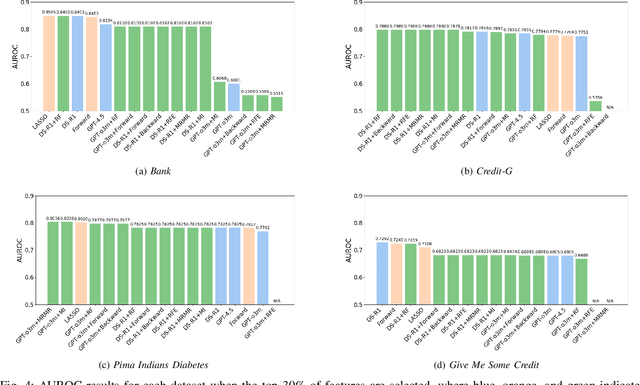
Recent advances in large language models (LLMs) have provided new opportunities for decision-making, particularly in the task of automated feature selection. In this paper, we first comprehensively evaluate LLM-based feature selection methods, covering the state-of-the-art DeepSeek-R1, GPT-o3-mini, and GPT-4.5. Then, we propose a novel hybrid strategy called LLM4FS that integrates LLMs with traditional data-driven methods. Specifically, input data samples into LLMs, and directly call traditional data-driven techniques such as random forest and forward sequential selection. Notably, our analysis reveals that the hybrid strategy leverages the contextual understanding of LLMs and the high statistical reliability of traditional data-driven methods to achieve excellent feature selection performance, even surpassing LLMs and traditional data-driven methods. Finally, we point out the limitations of its application in decision-making.
Zero-Shot Hashing Based on Reconstruction With Part Alignment
Mar 10, 2025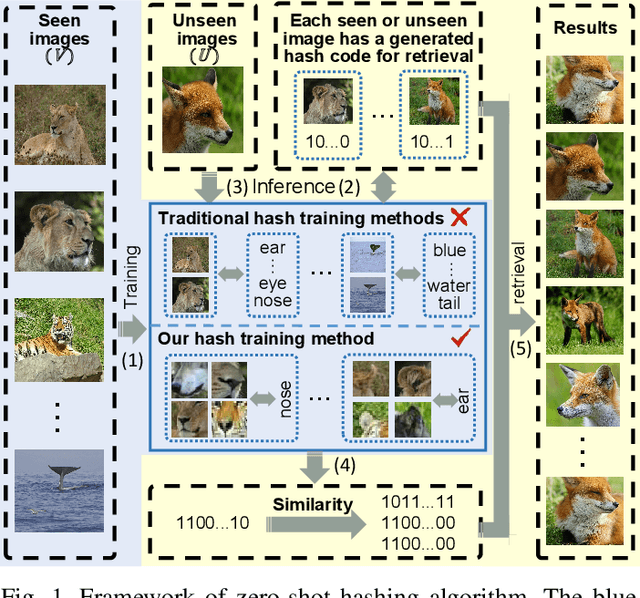
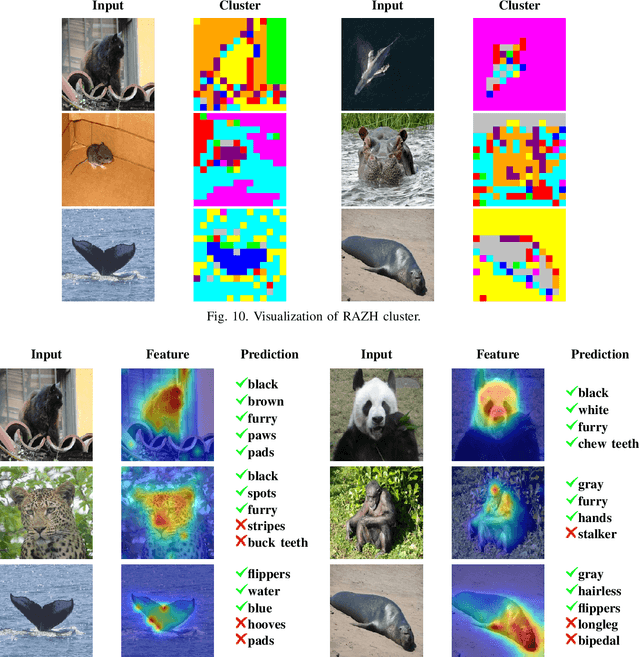
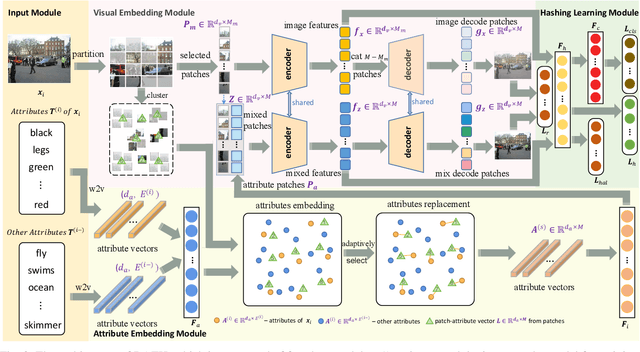
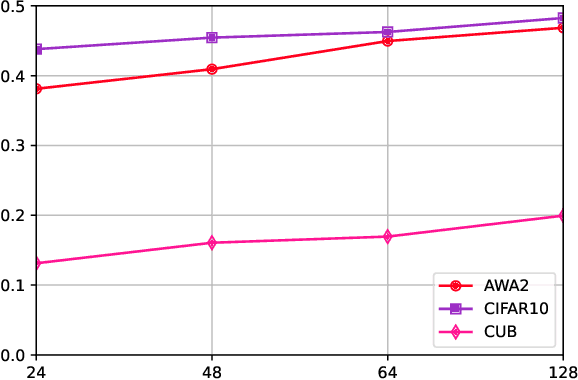
Hashing algorithms have been widely used in large-scale image retrieval tasks, especially for seen class data. Zero-shot hashing algorithms have been proposed to handle unseen class data. The key technique in these algorithms involves learning features from seen classes and transferring them to unseen classes, that is, aligning the feature embeddings between the seen and unseen classes. Most existing zero-shot hashing algorithms use the shared attributes between the two classes of interest to complete alignment tasks. However, the attributes are always described for a whole image, even though they represent specific parts of the image. Hence, these methods ignore the importance of aligning attributes with the corresponding image parts, which explicitly introduces noise and reduces the accuracy achieved when aligning the features of seen and unseen classes. To address this problem, we propose a new zero-shot hashing method called RAZH. We first use a clustering algorithm to group similar patches to image parts for attribute matching and then replace the image parts with the corresponding attribute vectors, gradually aligning each part with its nearest attribute. Extensive evaluation results demonstrate the superiority of the RAZH method over several state-of-the-art methods.
Temporal-Aware Spiking Transformer Hashing Based on 3D-DWT
Jan 12, 2025With the rapid growth of dynamic vision sensor (DVS) data, constructing a low-energy, efficient data retrieval system has become an urgent task. Hash learning is one of the most important retrieval technologies which can keep the distance between hash codes consistent with the distance between DVS data. As spiking neural networks (SNNs) can encode information through spikes, they demonstrate great potential in promoting energy efficiency. Based on the binary characteristics of SNNs, we first propose a novel supervised hashing method named Spikinghash with a hierarchical lightweight structure. Spiking WaveMixer (SWM) is deployed in shallow layers, utilizing a multilevel 3D discrete wavelet transform (3D-DWT) to decouple spatiotemporal features into various low-frequency and high frequency components, and then employing efficient spectral feature fusion. SWM can effectively capture the temporal dependencies and local spatial features. Spiking Self-Attention (SSA) is deployed in deeper layers to further extract global spatiotemporal information. We also design a hash layer utilizing binary characteristic of SNNs, which integrates information over multiple time steps to generate final hash codes. Furthermore, we propose a new dynamic soft similarity loss for SNNs, which utilizes membrane potentials to construct a learnable similarity matrix as soft labels to fully capture the similarity differences between classes and compensate information loss in SNNs, thereby improving retrieval performance. Experiments on multiple datasets demonstrate that Spikinghash can achieve state-of-the-art results with low energy consumption and fewer parameters.
Efficient 3D Perception on Multi-Sweep Point Cloud with Gumbel Spatial Pruning
Nov 12, 2024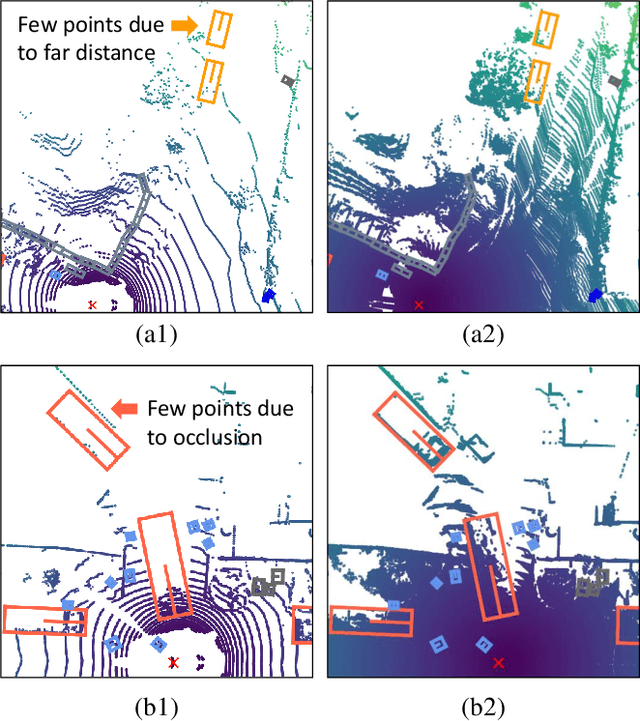
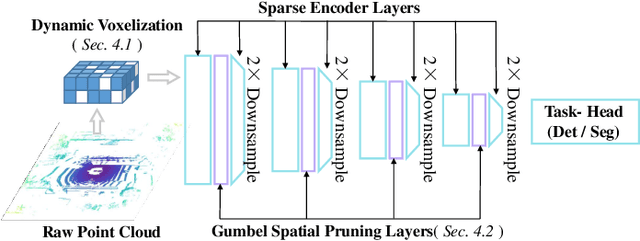
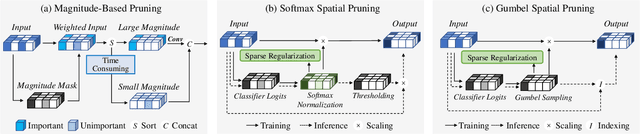
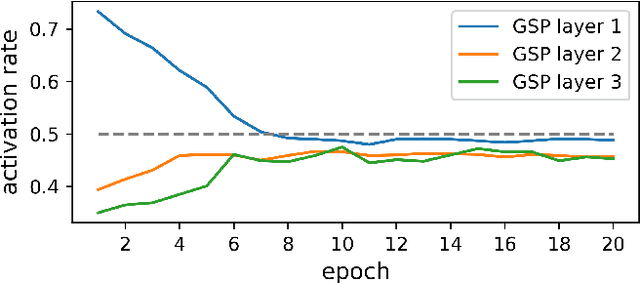
This paper studies point cloud perception within outdoor environments. Existing methods face limitations in recognizing objects located at a distance or occluded, due to the sparse nature of outdoor point clouds. In this work, we observe a significant mitigation of this problem by accumulating multiple temporally consecutive LiDAR sweeps, resulting in a remarkable improvement in perception accuracy. However, the computation cost also increases, hindering previous approaches from utilizing a large number of LiDAR sweeps. To tackle this challenge, we find that a considerable portion of points in the accumulated point cloud is redundant, and discarding these points has minimal impact on perception accuracy. We introduce a simple yet effective Gumbel Spatial Pruning (GSP) layer that dynamically prunes points based on a learned end-to-end sampling. The GSP layer is decoupled from other network components and thus can be seamlessly integrated into existing point cloud network architectures. Without incurring additional computational overhead, we increase the number of LiDAR sweeps from 10, a common practice, to as many as 40. Consequently, there is a significant enhancement in perception performance. For instance, in nuScenes 3D object detection and BEV map segmentation tasks, our pruning strategy improves the vanilla TransL baseline and other baseline methods.
Segment, Lift and Fit: Automatic 3D Shape Labeling from 2D Prompts
Jul 16, 2024

This paper proposes an algorithm for automatically labeling 3D objects from 2D point or box prompts, especially focusing on applications in autonomous driving. Unlike previous arts, our auto-labeler predicts 3D shapes instead of bounding boxes and does not require training on a specific dataset. We propose a Segment, Lift, and Fit (SLF) paradigm to achieve this goal. Firstly, we segment high-quality instance masks from the prompts using the Segment Anything Model (SAM) and transform the remaining problem into predicting 3D shapes from given 2D masks. Due to the ill-posed nature of this problem, it presents a significant challenge as multiple 3D shapes can project into an identical mask. To tackle this issue, we then lift 2D masks to 3D forms and employ gradient descent to adjust their poses and shapes until the projections fit the masks and the surfaces conform to surrounding LiDAR points. Notably, since we do not train on a specific dataset, the SLF auto-labeler does not overfit to biased annotation patterns in the training set as other methods do. Thus, the generalization ability across different datasets improves. Experimental results on the KITTI dataset demonstrate that the SLF auto-labeler produces high-quality bounding box annotations, achieving an AP@0.5 IoU of nearly 90\%. Detectors trained with the generated pseudo-labels perform nearly as well as those trained with actual ground-truth annotations. Furthermore, the SLF auto-labeler shows promising results in detailed shape predictions, providing a potential alternative for the occupancy annotation of dynamic objects.
MS-Net: A Multi-modal Self-supervised Network for Fine-Grained Classification of Aircraft in SAR Images
Aug 28, 2023



Synthetic aperture radar (SAR) imaging technology is commonly used to provide 24-hour all-weather earth observation. However, it still has some drawbacks in SAR target classification, especially in fine-grained classification of aircraft: aircrafts in SAR images have large intra-class diversity and inter-class similarity; the number of effective samples is insufficient and it's hard to annotate. To address these issues, this article proposes a novel multi-modal self-supervised network (MS-Net) for fine-grained classification of aircraft. Firstly, in order to entirely exploit the potential of multi-modal information, a two-sided path feature extraction network (TSFE-N) is constructed to enhance the image feature of the target and obtain the domain knowledge feature of text mode. Secondly, a contrastive self-supervised learning (CSSL) framework is employed to effectively learn useful label-independent feature from unbalanced data, a similarity per-ception loss (SPloss) is proposed to avoid network overfitting. Finally, TSFE-N is used as the encoder of CSSL to obtain the classification results. Through a large number of experiments, our MS-Net can effectively reduce the difficulty of classifying similar types of aircrafts. In the case of no label, the proposed algorithm achieves an accuracy of 88.46% for 17 types of air-craft classification task, which has pioneering significance in the field of fine-grained classification of aircraft in SAR images.
A Simple yet Effective Method for Graph Classification
Jun 06, 2022
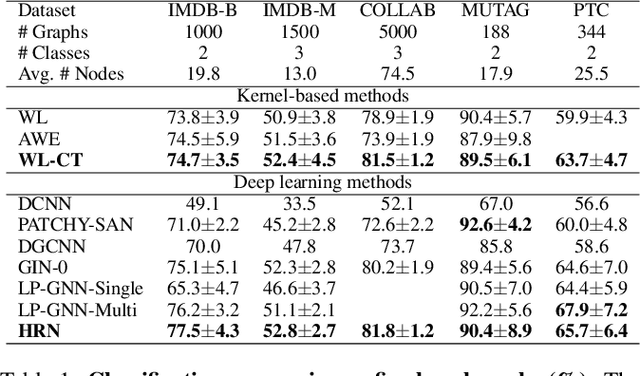
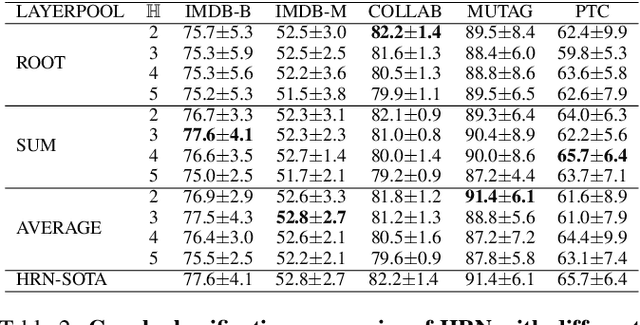
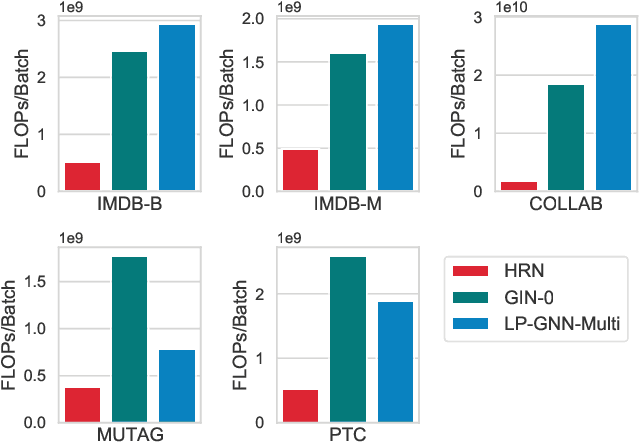
In deep neural networks, better results can often be obtained by increasing the complexity of previously developed basic models. However, it is unclear whether there is a way to boost performance by decreasing the complexity of such models. Intuitively, given a problem, a simpler data structure comes with a simpler algorithm. Here, we investigate the feasibility of improving graph classification performance while simplifying the learning process. Inspired by structural entropy on graphs, we transform the data sample from graphs to coding trees, which is a simpler but essential structure for graph data. Furthermore, we propose a novel message passing scheme, termed hierarchical reporting, in which features are transferred from leaf nodes to root nodes by following the hierarchical structure of coding trees. We then present a tree kernel and a convolutional network to implement our scheme for graph classification. With the designed message passing scheme, the tree kernel and convolutional network have a lower runtime complexity of $O(n)$ than Weisfeiler-Lehman subtree kernel and other graph neural networks of at least $O(hm)$. We empirically validate our methods with several graph classification benchmarks and demonstrate that they achieve better performance and lower computational consumption than competing approaches.
Structural Optimization Makes Graph Classification Simpler and Better
Sep 05, 2021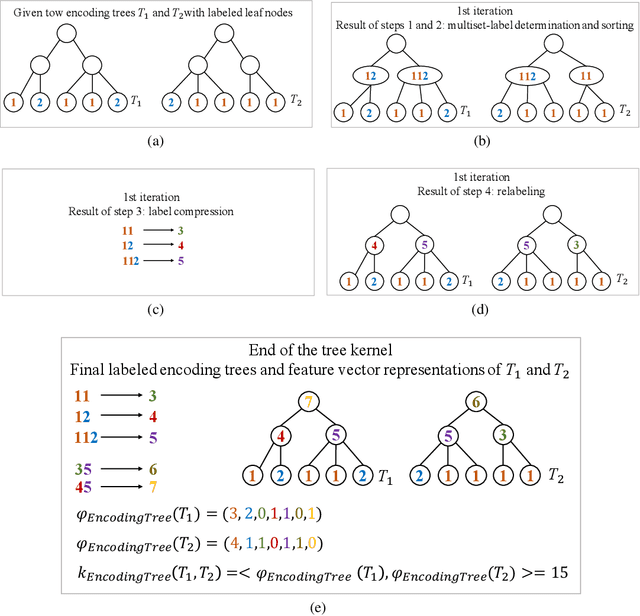
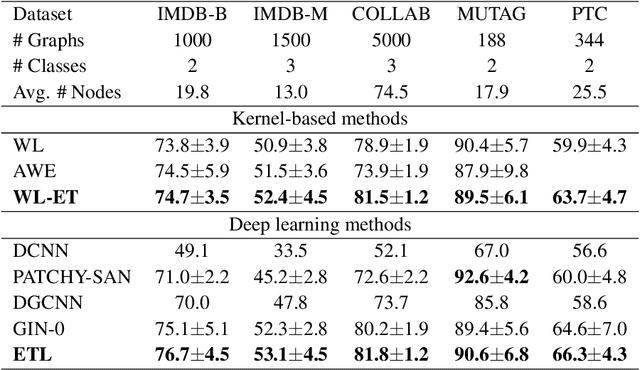
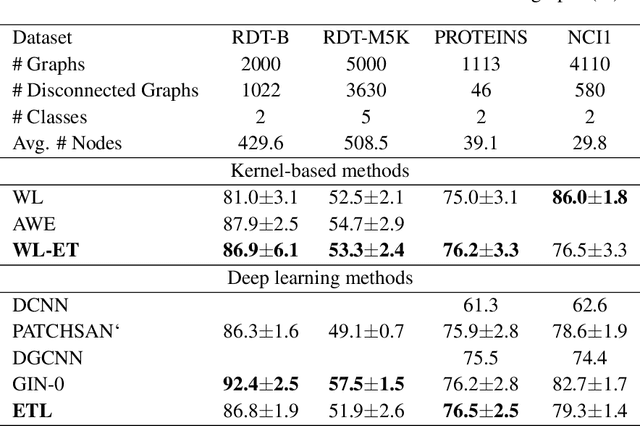
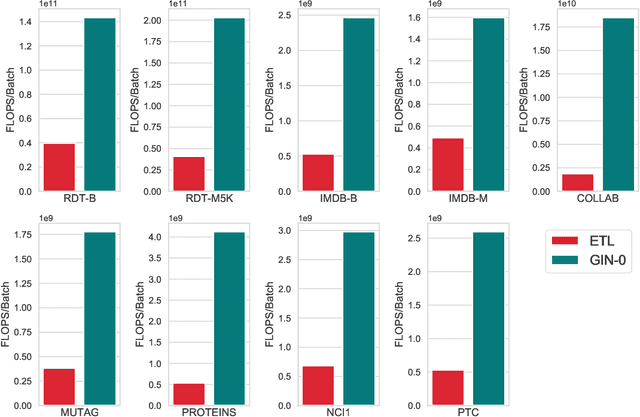
In deep neural networks, better results can often be obtained by increasing the complexity of previously developed basic models. However, it is unclear whether there is a way to boost performance by decreasing the complexity of such models. Here, based on an optimization method, we investigate the feasibility of improving graph classification performance while simplifying the model learning process. Inspired by progress in structural information assessment, we optimize the given data sample from graphs to encoding trees. In particular, we minimize the structural entropy of the transformed encoding tree to decode the key structure underlying a graph. This transformation is denoted as structural optimization. Furthermore, we propose a novel feature combination scheme, termed hierarchical reporting, for encoding trees. In this scheme, features are transferred from leaf nodes to root nodes by following the hierarchical structures of encoding trees. We then present an implementation of the scheme in a tree kernel and a convolutional network to perform graph classification. The tree kernel follows label propagation in the Weisfeiler-Lehman (WL) subtree kernel, but it has a lower runtime complexity $O(n)$. The convolutional network is a special implementation of our tree kernel in the deep learning field and is called Encoding Tree Learning (ETL). We empirically validate our tree kernel and convolutional network with several graph classification benchmarks and demonstrate that our methods achieve better performance and lower computational consumption than competing approaches.