 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Out-of-Distribution Detection via Test-Time Calibration with Dual Dynamic Dictionaries
Nov 17, 2025A key challenge in graph out-of-distribution (OOD) detection lies in the absence of ground-truth OOD samples during training. Existing methods are typically optimized to capture features within the in-distribution (ID) data and calculate OOD scores, which often limits pre-trained models from representing distributional boundaries, leading to unreliable OOD detection. Moreover, the latent structure of graph data is often governed by multiple underlying factors, which remains less explored. To address these challenges, we propose a novel test-time graph OOD detection method, termed BaCa, that calibrates OOD scores using dual dynamically updated dictionaries without requiring fine-tuning the pre-trained model. Specifically, BaCa estimates graphons and applies a mix-up strategy solely with test samples to generate diverse boundary-aware discriminative topologies, eliminating the need for exposing auxiliary datasets as outliers. We construct dual dynamic dictionaries via priority queues and attention mechanisms to adaptively capture latent ID and OOD representations, which are then utilized for boundary-aware OOD score calibration. To the best of our knowledge, extensive experiments on real-world datasets show that BaCa significantly outperforms existing state-of-the-art methods in OOD detection.
Toward Robust Signed Graph Learning through Joint Input-Target Denoising
Oct 26, 2025Signed Graph Neural Networks (SGNNs) are widely adopted to analyze complex patterns in signed graphs with both positive and negative links. Given the noisy nature of real-world connections, the robustness of SGNN has also emerged as a pivotal research area. Under the supervision of empirical properties, graph structure learning has shown its robustness on signed graph representation learning, however, there remains a paucity of research investigating a robust SGNN with theoretical guidance. Inspired by the success of graph information bottleneck (GIB) in information extraction, we propose RIDGE, a novel framework for Robust sI gned graph learning through joint Denoising of Graph inputs and supervision targEts. Different from the basic GIB, we extend the GIB theory with the capability of target space denoising as the co-existence of noise in both input and target spaces. In instantiation, RIDGE effectively cleanses input data and supervision targets via a tractable objective function produced by reparameterization mechanism and variational approximation. We extensively validate our method on four prevalent signed graph datasets, and the results show that RIDGE clearly improves the robustness of popular SGNN models under various levels of noise.
Structural Entropy Guided Unsupervised Graph Out-Of-Distribution Detection
Mar 05, 2025With the emerging of huge amount of unlabeled data, unsupervised out-of-distribution (OOD) detection is vital for ensuring the reliability of graph neural networks (GNNs) by identifying OOD samples from in-distribution (ID) ones during testing, where encountering novel or unknown data is inevitable. Existing methods often suffer from compromised performance due to redundant information in graph structures, which impairs their ability to effectively differentiate between ID and OOD data. To address this challenge, we propose SEGO, an unsupervised framework that integrates structural entropy into OOD detection regarding graph classification. Specifically, within the architecture of contrastive learning, SEGO introduces an anchor view in the form of coding tree by minimizing structural entropy. The obtained coding tree effectively removes redundant information from graphs while preserving essential structural information, enabling the capture of distinct graph patterns between ID and OOD samples. Furthermore, we present a multi-grained contrastive learning scheme at local, global, and tree levels using triplet views, where coding trees with essential information serve as the anchor view. Extensive experiments on real-world datasets validate the effectiveness of SEGO, demonstrating superior performance over state-of-the-art baselines in OOD detection. Specifically, our method achieves the best performance on 9 out of 10 dataset pairs, with an average improvement of 3.7\% on OOD detection datasets, significantly surpassing the best competitor by 10.8\% on the FreeSolv/ToxCast dataset pair.
Molecular Graph Contrastive Learning with Line Graph
Jan 15, 2025Trapped by the label scarcity in molecular property prediction and drug design, graph contrastive learning (GCL) came forward. Leading contrastive learning works show two kinds of view generators, that is, random or learnable data corruption and domain knowledge incorporation. While effective, the two ways also lead to molecular semantics altering and limited generalization capability, respectively. To this end, we relate the \textbf{L}in\textbf{E} graph with \textbf{MO}lecular graph co\textbf{N}trastive learning and propose a novel method termed \textit{LEMON}. Specifically, by contrasting the given graph with the corresponding line graph, the graph encoder can freely encode the molecular semantics without omission. Furthermore, we present a new patch with edge attribute fusion and two local contrastive losses enhance information transmission and tackle hard negative samples. Compared with state-of-the-art (SOTA) methods for view generation, superior performance on molecular property prediction suggests the effectiveness of our proposed framework.
Rumor Detection on Social Media with Temporal Propagation Structure Optimization
Dec 12, 2024



Traditional methods for detecting rumors on social media primarily focus on analyzing textual content, often struggling to capture the complexity of online interactions. Recent research has shifted towards leveraging graph neural networks to model the hierarchical conversation structure that emerges during rumor propagation. However, these methods tend to overlook the temporal aspect of rumor propagation and may disregard potential noise within the propagation structure. In this paper, we propose a novel approach that incorporates temporal information by constructing a weighted propagation tree, where the weight of each edge represents the time interval between connected posts. Drawing upon the theory of structural entropy, we transform this tree into a coding tree. This transformation aims to preserve the essential structure of rumor propagation while reducing noise. Finally, we introduce a recursive neural network to learn from the coding tree for rumor veracity prediction. Experimental results on two common datasets demonstrate the superiority of our approach.
NC-NCD: Novel Class Discovery for Node Classification
Jul 25, 2024

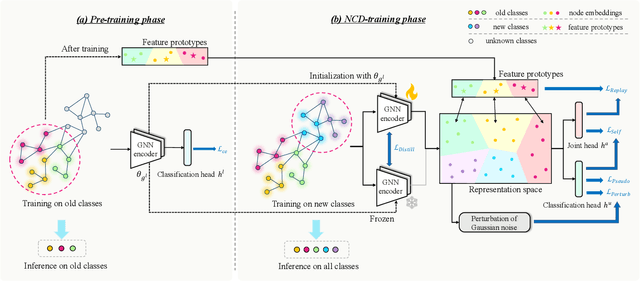
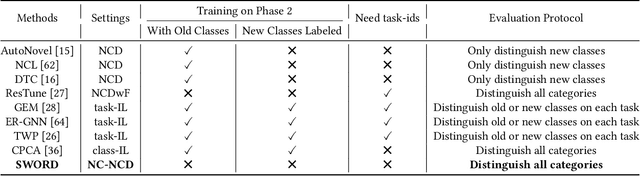
Novel Class Discovery (NCD) involves identifying new categories within unlabeled data by utilizing knowledge acquired from previously established categories. However, existing NCD methods often struggle to maintain a balance between the performance of old and new categories. Discovering unlabeled new categories in a class-incremental way is more practical but also more challenging, as it is frequently hindered by either catastrophic forgetting of old categories or an inability to learn new ones. Furthermore, the implementation of NCD on continuously scalable graph-structured data remains an under-explored area. In response to these challenges, we introduce for the first time a more practical NCD scenario for node classification (i.e., NC-NCD), and propose a novel self-training framework with prototype replay and distillation called SWORD, adopted to our NC-NCD setting. Our approach enables the model to cluster unlabeled new category nodes after learning labeled nodes while preserving performance on old categories without reliance on old category nodes. SWORD achieves this by employing a self-training strategy to learn new categories and preventing the forgetting of old categories through the joint use of feature prototypes and knowledge distillation. Extensive experiments on four common benchmarks demonstrate the superiority of SWORD over other state-of-the-art methods.
Do LLMs Understand Visual Anomalies? Uncovering LLM Capabilities in Zero-shot Anomaly Detection
Apr 15, 2024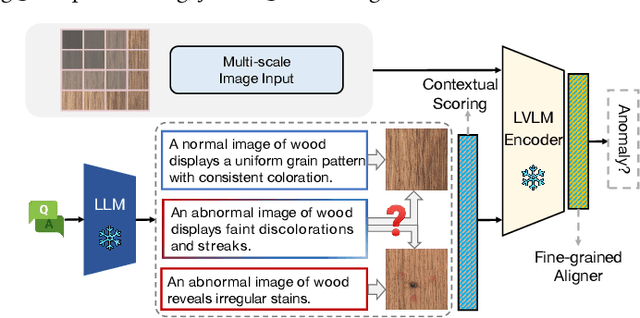
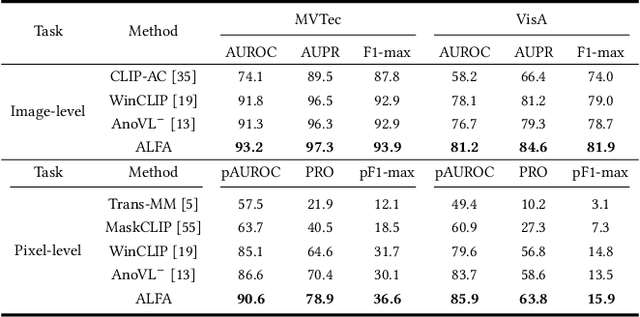
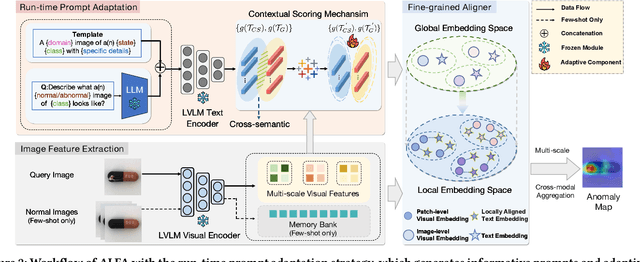
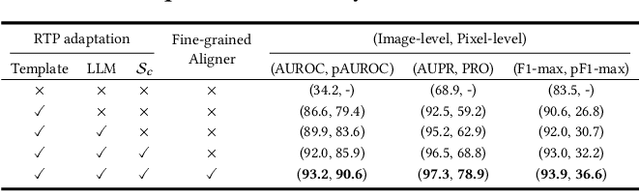
Large vision-language models (LVLMs) are markedly proficient in deriving visual representations guided by natural language. Recent explorations have utilized LVLMs to tackle zero-shot visual anomaly detection (VAD) challenges by pairing images with textual descriptions indicative of normal and abnormal conditions, referred to as anomaly prompts. However, existing approaches depend on static anomaly prompts that are prone to cross-semantic ambiguity, and prioritize global image-level representations over crucial local pixel-level image-to-text alignment that is necessary for accurate anomaly localization. In this paper, we present ALFA, a training-free approach designed to address these challenges via a unified model. We propose a run-time prompt adaptation strategy, which first generates informative anomaly prompts to leverage the capabilities of a large language model (LLM). This strategy is enhanced by a contextual scoring mechanism for per-image anomaly prompt adaptation and cross-semantic ambiguity mitigation. We further introduce a novel fine-grained aligner to fuse local pixel-level semantics for precise anomaly localization, by projecting the image-text alignment from global to local semantic spaces. Extensive evaluations on the challenging MVTec and VisA datasets confirm ALFA's effectiveness in harnessing the language potential for zero-shot VAD, achieving significant PRO improvements of 12.1% on MVTec AD and 8.9% on VisA compared to state-of-the-art zero-shot VAD approaches.
HILL: Hierarchy-aware Information Lossless Contrastive Learning for Hierarchical Text Classification
Mar 26, 2024



Existing self-supervised methods in natural language processing (NLP), especially hierarchical text classification (HTC), mainly focus on self-supervised contrastive learning, extremely relying on human-designed augmentation rules to generate contrastive samples, which can potentially corrupt or distort the original information. In this paper, we tend to investigate the feasibility of a contrastive learning scheme in which the semantic and syntactic information inherent in the input sample is adequately reserved in the contrastive samples and fused during the learning process. Specifically, we propose an information lossless contrastive learning strategy for HTC, namely \textbf{H}ierarchy-aware \textbf{I}nformation \textbf{L}ossless contrastive \textbf{L}earning (HILL), which consists of a text encoder representing the input document, and a structure encoder directly generating the positive sample. The structure encoder takes the document embedding as input, extracts the essential syntactic information inherent in the label hierarchy with the principle of structural entropy minimization, and injects the syntactic information into the text representation via hierarchical representation learning. Experiments on three common datasets are conducted to verify the superiority of HILL.
HiTIN: Hierarchy-aware Tree Isomorphism Network for Hierarchical Text Classification
May 24, 2023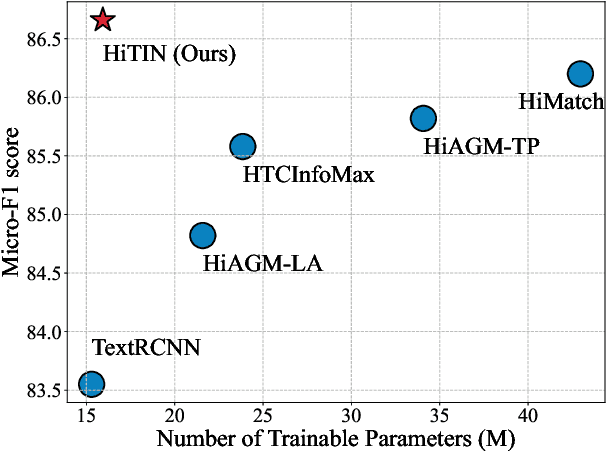

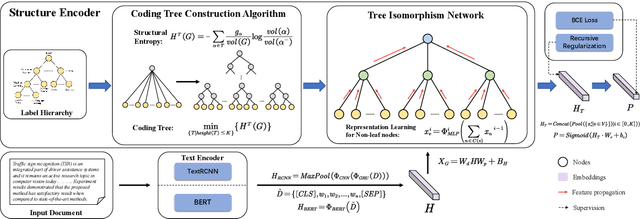

Hierarchical text classification (HTC) is a challenging subtask of multi-label classification as the labels form a complex hierarchical structure. Existing dual-encoder methods in HTC achieve weak performance gains with huge memory overheads and their structure encoders heavily rely on domain knowledge. Under such observation, we tend to investigate the feasibility of a memory-friendly model with strong generalization capability that could boost the performance of HTC without prior statistics or label semantics. In this paper, we propose Hierarchy-aware Tree Isomorphism Network (HiTIN) to enhance the text representations with only syntactic information of the label hierarchy. Specifically, we convert the label hierarchy into an unweighted tree structure, termed coding tree, with the guidance of structural entropy. Then we design a structure encoder to incorporate hierarchy-aware information in the coding tree into text representations. Besides the text encoder, HiTIN only contains a few multi-layer perceptions and linear transformations, which greatly saves memory. We conduct experiments on three commonly used datasets and the results demonstrate that HiTIN could achieve better test performance and less memory consumption than state-of-the-art (SOTA) methods.
SEGA: Structural Entropy Guided Anchor View for Graph Contrastive Learning
May 08, 2023In contrastive learning, the choice of ``view'' controls the information that the representation captures and influences the performance of the model. However, leading graph contrastive learning methods generally produce views via random corruption or learning, which could lead to the loss of essential information and alteration of semantic information. An anchor view that maintains the essential information of input graphs for contrastive learning has been hardly investigated. In this paper, based on the theory of graph information bottleneck, we deduce the definition of this anchor view; put differently, \textit{the anchor view with essential information of input graph is supposed to have the minimal structural uncertainty}. Furthermore, guided by structural entropy, we implement the anchor view, termed \textbf{SEGA}, for graph contrastive learning. We extensively validate the proposed anchor view on various benchmarks regarding graph classification under unsupervised, semi-supervised, and transfer learning and achieve significant performance boosts compared to the state-of-the-art methods.