 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGATS: Gaussian Aware Temporal Scaling Transformer for Invariant 4D Spatio-Temporal Point Cloud Representation
Mar 17, 2026Understanding 4D point cloud videos is essential for enabling intelligent agents to perceive dynamic environments. However, temporal scale bias across varying frame rates and distributional uncertainty in irregular point clouds make it highly challenging to design a unified and robust 4D backbone. Existing CNN or Transformer based methods are constrained either by limited receptive fields or by quadratic computational complexity, while neglecting these implicit distortions. To address this problem, we propose a novel dual invariant framework, termed \textbf{Gaussian Aware Temporal Scaling (GATS)}, which explicitly resolves both distributional inconsistencies and temporal. The proposed \emph{Uncertainty Guided Gaussian Convolution (UGGC)} incorporates local Gaussian statistics and uncertainty aware gating into point convolution, thereby achieving robust neighborhood aggregation under density variation, noise, and occlusion. In parallel, the \emph{Temporal Scaling Attention (TSA)} introduces a learnable scaling factor to normalize temporal distances, ensuring frame partition invariance and consistent velocity estimation across different frame rates. These two modules are complementary: temporal scaling normalizes time intervals prior to Gaussian estimation, while Gaussian modeling enhances robustness to irregular distributions. Our experiments on mainstream benchmarks MSR-Action3D (\textbf{+6.62\%} accuracy), NTU RGBD (\textbf{+1.4\%} accuracy), and Synthia4D (\textbf{+1.8\%} mIoU) demonstrate significant performance gains, offering a more efficient and principled paradigm for invariant 4D point cloud video understanding with superior accuracy, robustness, and scalability compared to Transformer based counterparts.
Tensor-Compressed and Fully-Quantized Training of Neural PDE Solvers
Dec 10, 2025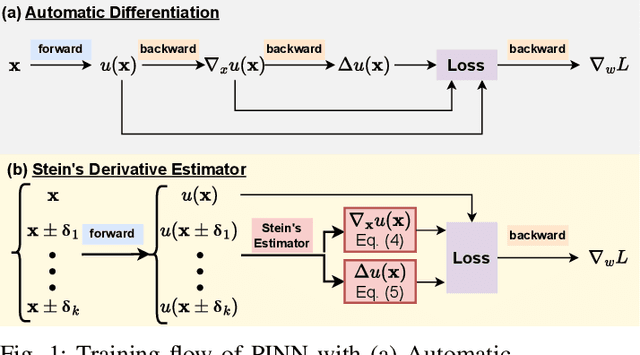
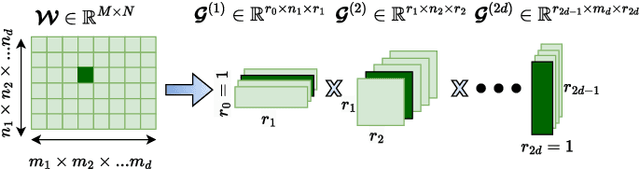
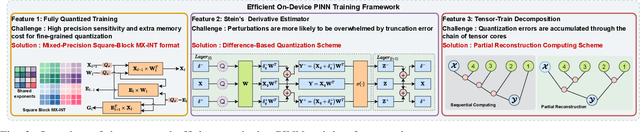
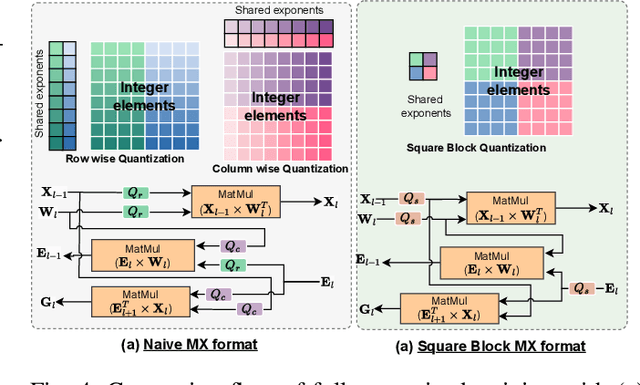
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.
SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025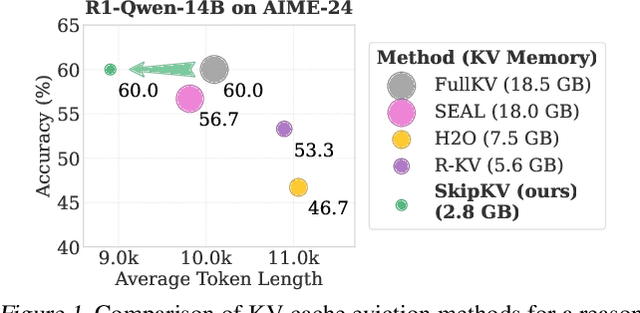
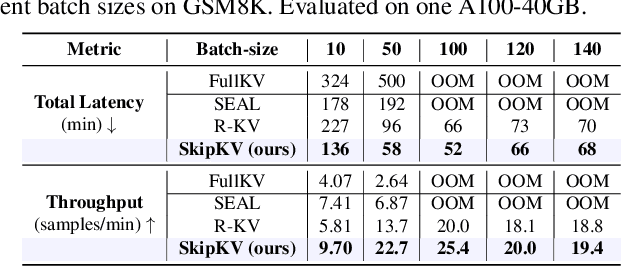
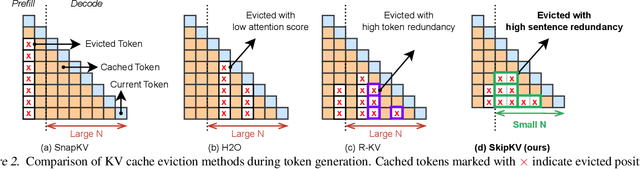
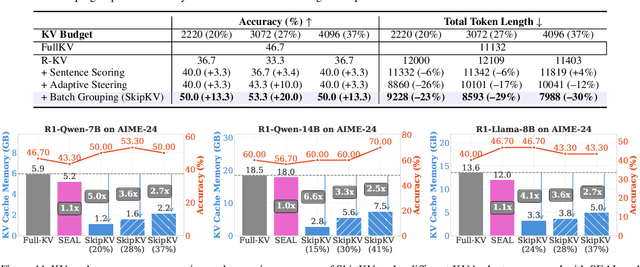
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
FLAT-LLM: Fine-grained Low-rank Activation Space Transformation for Large Language Model Compression
May 29, 2025Large Language Models (LLMs) have enabled remarkable progress in natural language processing, yet their high computational and memory demands pose challenges for deployment in resource-constrained environments. Although recent low-rank decomposition methods offer a promising path for structural compression, they often suffer from accuracy degradation, expensive calibration procedures, and result in inefficient model architectures that hinder real-world inference speedups. In this paper, we propose FLAT-LLM, a fast and accurate, training-free structural compression method based on fine-grained low-rank transformations in the activation space. Specifically, we reduce the hidden dimension by transforming the weights using truncated eigenvectors computed via head-wise Principal Component Analysis (PCA), and employ an importance-based metric to adaptively allocate ranks across decoders. FLAT-LLM achieves efficient and effective weight compression without recovery fine-tuning, which could complete the calibration within a few minutes. Evaluated across 4 models and 11 datasets, FLAT-LLM outperforms structural pruning baselines in generalization and downstream performance, while delivering inference speedups over decomposition-based methods.
Ultra Memory-Efficient On-FPGA Training of Transformers via Tensor-Compressed Optimization
Jan 11, 2025Transformer models have achieved state-of-the-art performance across a wide range of machine learning tasks. There is growing interest in training transformers on resource-constrained edge devices due to considerations such as privacy, domain adaptation, and on-device scientific machine learning. However, the significant computational and memory demands required for transformer training often exceed the capabilities of an edge device. Leveraging low-rank tensor compression, this paper presents the first on-FPGA accelerator for end-to-end transformer training. On the algorithm side, we present a bi-directional contraction flow for tensorized transformer training, significantly reducing the computational FLOPS and intra-layer memory costs compared to existing tensor operations. On the hardware side, we store all highly compressed model parameters and gradient information on chip, creating an on-chip-memory-only framework for each stage in training. This reduces off-chip communication and minimizes latency and energy costs. Additionally, we implement custom computing kernels for each training stage and employ intra-layer parallelism and pipe-lining to further enhance run-time and memory efficiency. Through experiments on transformer models within $36.7$ to $93.5$ MB using FP-32 data formats on the ATIS dataset, our tensorized FPGA accelerator could conduct single-batch end-to-end training on the AMD Alevo U50 FPGA, with a memory budget of less than $6$-MB BRAM and $22.5$-MB URAM. Compared to uncompressed training on the NVIDIA RTX 3090 GPU, our on-FPGA training achieves a memory reduction of $30\times$ to $51\times$. Our FPGA accelerator also achieves up to $3.6\times$ less energy cost per epoch compared with tensor Transformer training on an NVIDIA RTX 3090 GPU.
3D-QueryIS: A Query-based Framework for 3D Instance Segmentation
Nov 17, 2022Previous top-performing methods for 3D instance segmentation often maintain inter-task dependencies and the tendency towards a lack of robustness. Besides, inevitable variations of different datasets make these methods become particularly sensitive to hyper-parameter values and manifest poor generalization capability. In this paper, we address the aforementioned challenges by proposing a novel query-based method, termed as 3D-QueryIS, which is detector-free, semantic segmentation-free, and cluster-free. Specifically, we propose to generate representative points in an implicit manner, and use them together with the initial queries to generate the informative instance queries. Then, the class and binary instance mask predictions can be produced by simply applying MLP layers on top of the instance queries and the extracted point cloud embeddings. Thus, our 3D-QueryIS is free from the accumulated errors caused by the inter-task dependencies. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness and efficiency of our proposed 3D-QueryIS method.
BEBERT: Efficient and robust binary ensemble BERT
Oct 28, 2022



Pre-trained BERT models have achieved impressive accuracy on natural language processing (NLP) tasks. However, their excessive amount of parameters hinders them from efficient deployment on edge devices. Binarization of the BERT models can significantly alleviate this issue but comes with a severe accuracy drop compared with their full-precision counterparts. In this paper, we propose an efficient and robust binary ensemble BERT (BEBERT) to bridge the accuracy gap. To the best of our knowledge, this is the first work employing ensemble techniques on binary BERTs, yielding BEBERT, which achieves superior accuracy while retaining computational efficiency. Furthermore, we remove the knowledge distillation procedures during ensemble to speed up the training process without compromising accuracy. Experimental results on the GLUE benchmark show that the proposed BEBERT significantly outperforms the existing binary BERT models in accuracy and robustness with a 2x speedup on training time. Moreover, our BEBERT has only a negligible accuracy loss of 0.3% compared to the full-precision baseline while saving 15x and 13x in FLOPs and model size, respectively. In addition, BEBERT also outperforms other compressed BERTs in accuracy by up to 6.7%.
VDM-DA: Virtual Domain Modeling for Source Data-free Domain Adaptation
Mar 26, 2021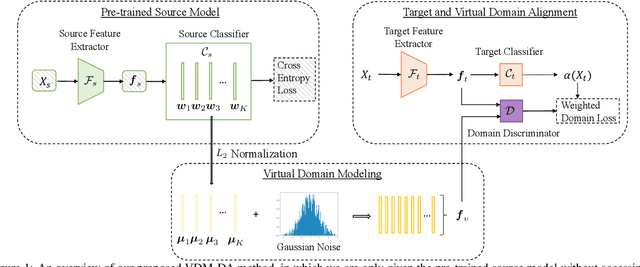
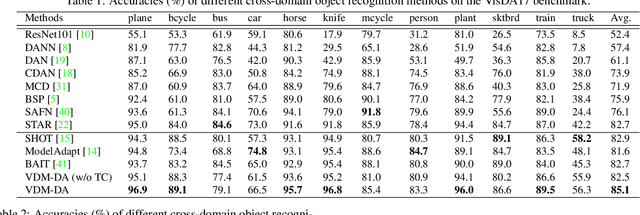
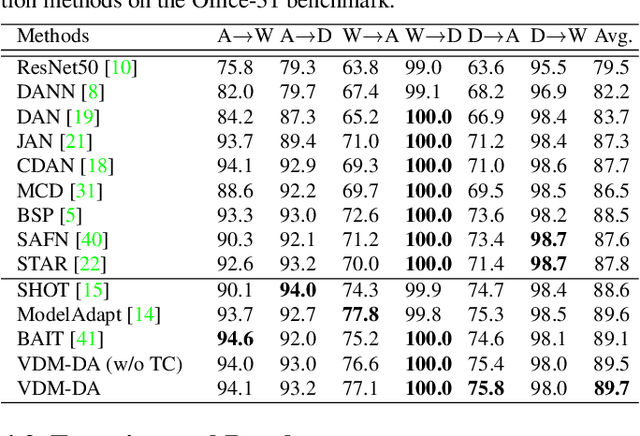
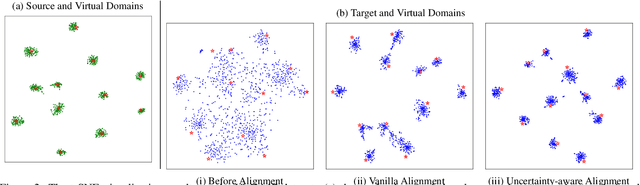
Domain adaptation aims to leverage a label-rich domain (the source domain) to help model learning in a label-scarce domain (the target domain). Most domain adaptation methods require the co-existence of source and target domain samples to reduce the distribution mismatch, however, access to the source domain samples may not always be feasible in the real world applications due to different problems (e.g., storage, transmission, and privacy issues). In this work, we deal with the source data-free unsupervised domain adaptation problem, and propose a novel approach referred to as Virtual Domain Modeling (VDM-DA). The virtual domain acts as a bridge between the source and target domains. On one hand, we generate virtual domain samples based on an approximated Gaussian Mixture Model (GMM) in the feature space with the pre-trained source model, such that the virtual domain maintains a similar distribution with the source domain without accessing to the original source data. On the other hand, we also design an effective distribution alignment method to reduce the distribution divergence between the virtual domain and the target domain by gradually improving the compactness of the target domain distribution through model learning. In this way, we successfully achieve the goal of distribution alignment between the source and target domains by training deep networks without accessing to the source domain data. We conduct extensive experiments on benchmark datasets for both 2D image-based and 3D point cloud-based cross-domain object recognition tasks, where the proposed method referred to Domain Adaptation with Virtual Domain Modeling (VDM-DA) achieves the state-of-the-art performances on all datasets.