 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA: Accelerating LLM Decoding via an Efficient Vector Quantization Architecture
May 22, 2026Large Language Models (LLMs) have achieved impressive performance across diverse domains but remain inefficient during the autoregressive decoding phase. Unlike the prefill stage, which employs compute-bound GEMM operations, decoding executes a sequence of small GEMV-like computations that are memory-bound and underutilize modern accelerators. Weight-only vector quantization (VQ) has emerged as an effective compression technique that clusters model weights into a shared codebook and replaces the original weight matrix with low-precision indices, enabling 2-bit-level weight compression. While this approach substantially reduces model size and memory bandwidth, it still suffers from two critical inefficiencies: the low utilization of GEMV computation and frequent memory conflicts during codebook lookups. This paper presents EVA, an efficient vector-quantization-based architecture that addresses both computational and memory bottlenecks in LLM decoding. EVA builds on a simple yet effective insight that combines input-codebook computation with conflict-free memory access. Instead of reconstructing quantized weights from indices, EVA directly performs dot products between input vectors and the weight codebook, transforming LLM decoding from GEMV to GEMM computation. It then performs structured lookups from an intermediate output buffer, eliminating memory bank conflicts. We further design a hardware-software co-optimized architecture specialized for LLM decoding while remaining compatible with conventional prefill execution. Evaluations show that EVA achieves up to 11.17$\times$ speedup and 7.17$\times$ higher energy efficiency compared with the SOTA lookup-based architecture, while preserving arithmetic precision after vector quantization. Our code is available at https://github.com/dbw6/Eva.git.
Latent Bridge: Feature Delta Prediction for Efficient Dual-System Vision-Language-Action Model Inference
May 04, 2026Dual-system Vision-Language-Action (VLA) models achieve state-of-the-art robotic manipulation but are bottlenecked by the VLM backbone, which must execute at every control step while producing temporally redundant features. We propose Latent Bridge, a lightweight model that predicts VLM output deltas between timesteps, enabling the action head to operate on predicted outputs while the expensive VLM backbone is called only periodically. We instantiate Latent Bridge on two architecturally distinct VLAs: GR00T-N1.6 (feature-space bridge) and π0.5 (KV-cache bridge), demonstrating that the approach generalizes across VLA designs. Our task-agnostic DAgger training pipeline transfers across benchmarks without modification. Across four LIBERO suites, 24 RoboCasa kitchen tasks, and the ALOHA sim transfer-cube task, Latent Bridge achieves 95-100% performance retention while reducing VLM calls by 50-75%, yielding 1.65-1.73x net per-episode speedup.
ZEUS: Accelerating Diffusion Models with Only Second-Order Predictor
Apr 02, 2026Denoising generative models deliver high-fidelity generation but remain bottlenecked by inference latency due to the many iterative denoiser calls required during sampling. Training-free acceleration methods reduce latency by either sparsifying the model architecture or shortening the sampling trajectory. Current training-free acceleration methods are more complex than necessary: higher-order predictors amplify error under aggressive speedups, and architectural modifications hinder deployment. Beyond 2x acceleration, step skipping creates structural scarcity -- at most one fresh evaluation per local window -- leaving the computed output and its backward difference as the only causally grounded information. Based on this, we propose ZEUS, an acceleration method that predicts reduced denoiser evaluations using a second-order predictor, and stabilizes aggressive consecutive skipping with an interleaved scheme that avoids back-to-back extrapolations. ZEUS adds essentially zero overhead, no feature caches, and no architectural modifications, and it is compatible with different backbones, prediction objectives, and solver choices. Across image and video generation, ZEUS consistently improves the speed-fidelity performance over recent training-free baselines, achieving up to 3.2x end-to-end speedup while maintaining perceptual quality. Our code is available at: https://github.com/Ting-Justin-Jiang/ZEUS.
Compressed-Domain-Aware Online Video Super-Resolution
Mar 08, 2026In bandwidth-limited online video streaming, videos are usually downsampled and compressed. Although recent online video super-resolution (online VSR) approaches achieve promising results, they are still compute-intensive and fall short of real-time processing at higher resolutions, due to complex motion estimation for alignment and redundant processing of consecutive frames. To address these issues, we propose a compressed-domain-aware network (CDA-VSR) for online VSR, which utilizes compressed-domain information, including motion vectors, residual maps, and frame types to balance quality and efficiency. Specifically, we propose a motion-vector-guided deformable alignment module that uses motion vectors for coarse warping and learns only local residual offsets for fine-tuned adjustments, thereby maintaining accuracy while reducing computation. Then, we utilize a residual map gated fusion module to derive spatial weights from residual maps, suppressing mismatched regions and emphasizing reliable details. Further, we design a frame-type-aware reconstruction module for adaptive compute allocation across frame types, balancing accuracy and efficiency. On the REDS4 dataset, our CDA-VSR surpasses the state-of-the-art method TMP, with a maximum PSNR improvement of 0.13 dB while delivering more than double the inference speed. The code will be released at https://github.com/sspBIT/CDA-VSR.
Evaluating Accounting Reasoning Capabilities of Large Language Models
Jan 10, 2026Large language models are transforming learning, cognition, and research across many fields. Effectively integrating them into professional domains, such as accounting, is a key challenge for enterprise digital transformation. To address this, we define vertical domain accounting reasoning and propose evaluation criteria derived from an analysis of the training data characteristics of representative GLM models. These criteria support systematic study of accounting reasoning and provide benchmarks for performance improvement. Using this framework, we evaluate GLM-6B, GLM-130B, GLM-4, and OpenAI GPT-4 on accounting reasoning tasks. Results show that prompt design significantly affects performance, with GPT-4 demonstrating the strongest capability. Despite these gains, current models remain insufficient for real-world enterprise accounting, indicating the need for further optimization to unlock their full practical value.
LLaViDA: A Large Language Vision Driving Assistant for Explicit Reasoning and Enhanced Trajectory Planning
Dec 20, 2025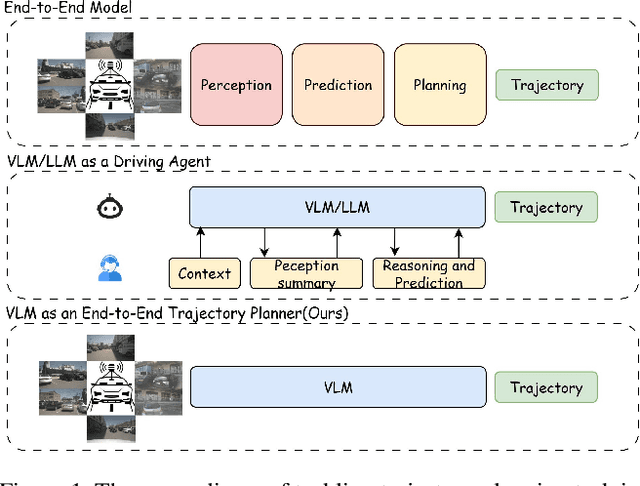
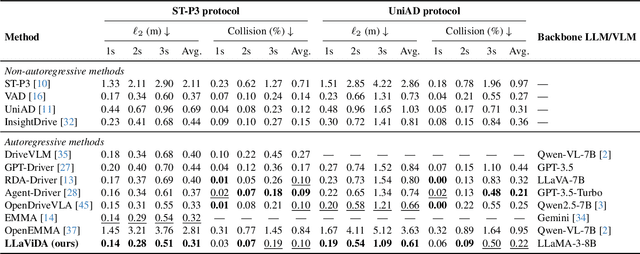
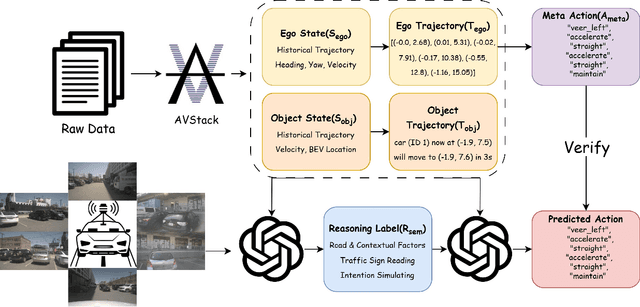
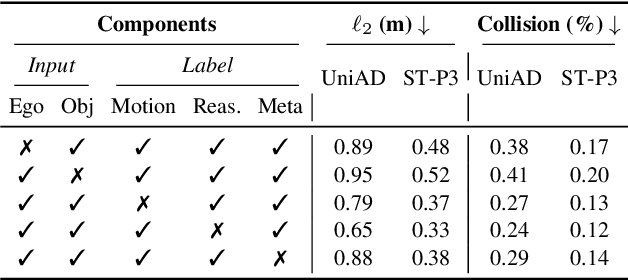
Trajectory planning is a fundamental yet challenging component of autonomous driving. End-to-end planners frequently falter under adverse weather, unpredictable human behavior, or complex road layouts, primarily because they lack strong generalization or few-shot capabilities beyond their training data. We propose LLaViDA, a Large Language Vision Driving Assistant that leverages a Vision-Language Model (VLM) for object motion prediction, semantic grounding, and chain-of-thought reasoning for trajectory planning in autonomous driving. A two-stage training pipeline--supervised fine-tuning followed by Trajectory Preference Optimization (TPO)--enhances scene understanding and trajectory planning by injecting regression-based supervision, produces a powerful "VLM Trajectory Planner for Autonomous Driving." On the NuScenes benchmark, LLaViDA surpasses state-of-the-art end-to-end and other recent VLM/LLM-based baselines in open-loop trajectory planning task, achieving an average L2 trajectory error of 0.31 m and a collision rate of 0.10% on the NuScenes test set. The code for this paper is available at GitHub.
Tensor-Compressed and Fully-Quantized Training of Neural PDE Solvers
Dec 10, 2025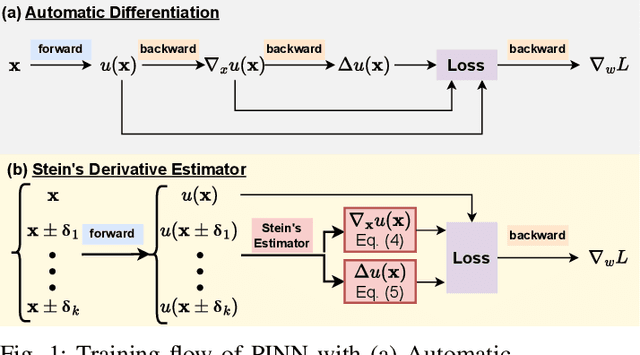
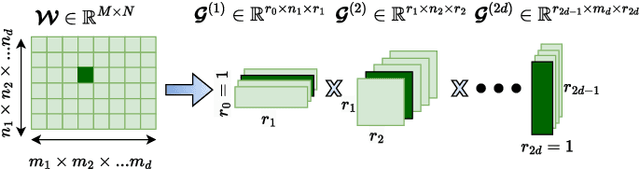
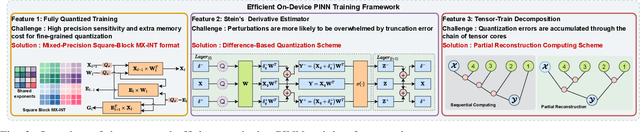
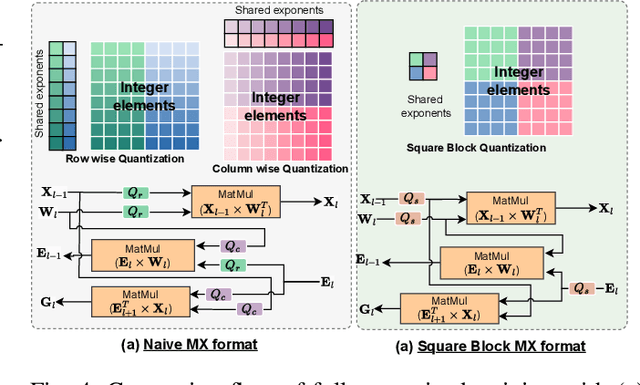
Physics-Informed Neural Networks (PINNs) have emerged as a promising paradigm for solving partial differential equations (PDEs) by embedding physical laws into neural network training objectives. However, their deployment on resource-constrained platforms is hindered by substantial computational and memory overhead, primarily stemming from higher-order automatic differentiation, intensive tensor operations, and reliance on full-precision arithmetic. To address these challenges, we present a framework that enables scalable and energy-efficient PINN training on edge devices. This framework integrates fully quantized training, Stein's estimator (SE)-based residual loss computation, and tensor-train (TT) decomposition for weight compression. It contributes three key innovations: (1) a mixed-precision training method that use a square-block MX (SMX) format to eliminate data duplication during backpropagation; (2) a difference-based quantization scheme for the Stein's estimator that mitigates underflow; and (3) a partial-reconstruction scheme (PRS) for TT-Layers that reduces quantization-error accumulation. We further design PINTA, a precision-scalable hardware accelerator, to fully exploit the performance of the framework. Experiments on the 2-D Poisson, 20-D Hamilton-Jacobi-Bellman (HJB), and 100-D Heat equations demonstrate that the proposed framework achieves accuracy comparable to or better than full-precision, uncompressed baselines while delivering 5.5x to 83.5x speedups and 159.6x to 2324.1x energy savings. This work enables real-time PDE solving on edge devices and paves the way for energy-efficient scientific computing at scale.
XEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Aug 12, 2025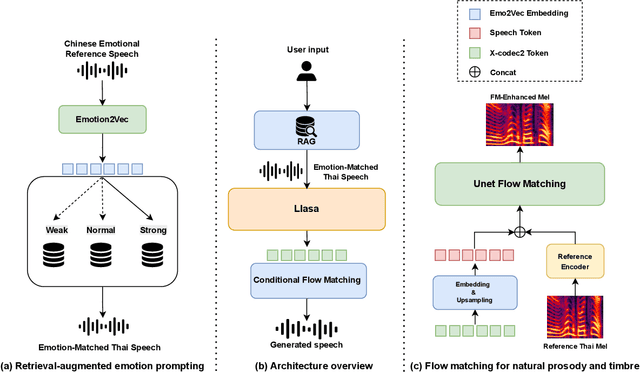
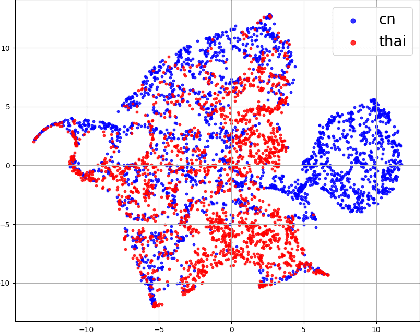
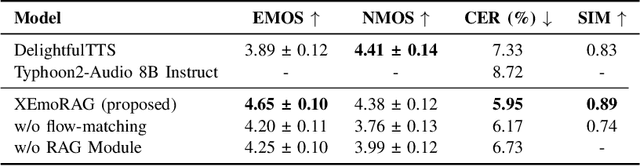
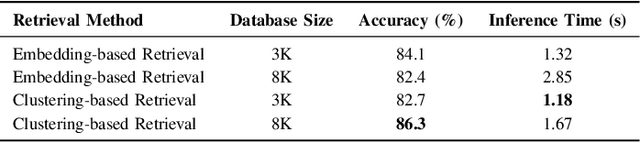
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language. However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features. In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data. XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency. Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels. These results highlight XEmoRAG's capability to achieve flexible and low-resource emotional transfer across languages. Our demo is available at https://tlzuo-lesley.github.io/Demo-page/ .
SADA: Stability-guided Adaptive Diffusion Acceleration
Jul 23, 2025Diffusion models have achieved remarkable success in generative tasks but suffer from high computational costs due to their iterative sampling process and quadratic attention costs. Existing training-free acceleration strategies that reduce per-step computation cost, while effectively reducing sampling time, demonstrate low faithfulness compared to the original baseline. We hypothesize that this fidelity gap arises because (a) different prompts correspond to varying denoising trajectory, and (b) such methods do not consider the underlying ODE formulation and its numerical solution. In this paper, we propose Stability-guided Adaptive Diffusion Acceleration (SADA), a novel paradigm that unifies step-wise and token-wise sparsity decisions via a single stability criterion to accelerate sampling of ODE-based generative models (Diffusion and Flow-matching). For (a), SADA adaptively allocates sparsity based on the sampling trajectory. For (b), SADA introduces principled approximation schemes that leverage the precise gradient information from the numerical ODE solver. Comprehensive evaluations on SD-2, SDXL, and Flux using both EDM and DPM++ solvers reveal consistent $\ge 1.8\times$ speedups with minimal fidelity degradation (LPIPS $\leq 0.10$ and FID $\leq 4.5$) compared to unmodified baselines, significantly outperforming prior methods. Moreover, SADA adapts seamlessly to other pipelines and modalities: It accelerates ControlNet without any modifications and speeds up MusicLDM by $1.8\times$ with $\sim 0.01$ spectrogram LPIPS.
FLAT-LLM: Fine-grained Low-rank Activation Space Transformation for Large Language Model Compression
May 29, 2025Large Language Models (LLMs) have enabled remarkable progress in natural language processing, yet their high computational and memory demands pose challenges for deployment in resource-constrained environments. Although recent low-rank decomposition methods offer a promising path for structural compression, they often suffer from accuracy degradation, expensive calibration procedures, and result in inefficient model architectures that hinder real-world inference speedups. In this paper, we propose FLAT-LLM, a fast and accurate, training-free structural compression method based on fine-grained low-rank transformations in the activation space. Specifically, we reduce the hidden dimension by transforming the weights using truncated eigenvectors computed via head-wise Principal Component Analysis (PCA), and employ an importance-based metric to adaptively allocate ranks across decoders. FLAT-LLM achieves efficient and effective weight compression without recovery fine-tuning, which could complete the calibration within a few minutes. Evaluated across 4 models and 11 datasets, FLAT-LLM outperforms structural pruning baselines in generalization and downstream performance, while delivering inference speedups over decomposition-based methods.