 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXEmoRAG: Cross-Lingual Emotion Transfer with Controllable Intensity Using Retrieval-Augmented Generation
Aug 12, 2025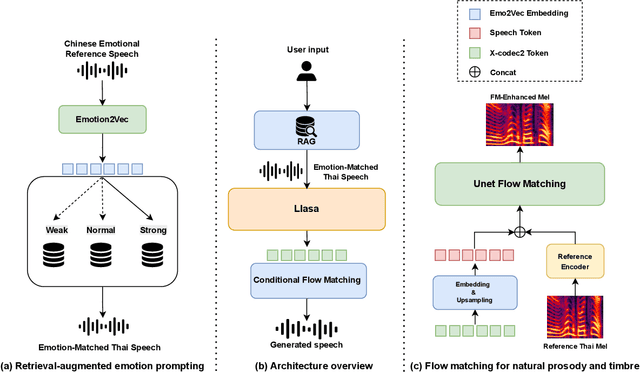
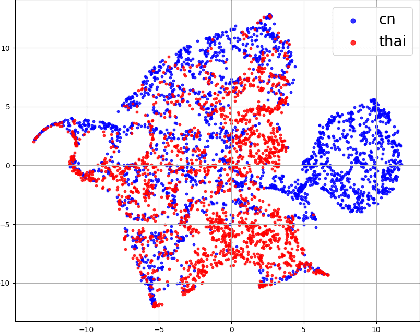
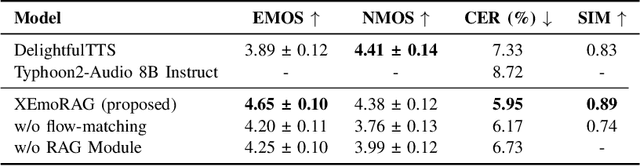
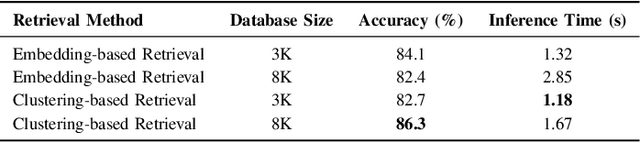
Zero-shot emotion transfer in cross-lingual speech synthesis refers to generating speech in a target language, where the emotion is expressed based on reference speech from a different source language. However, this task remains challenging due to the scarcity of parallel multilingual emotional corpora, the presence of foreign accent artifacts, and the difficulty of separating emotion from language-specific prosodic features. In this paper, we propose XEmoRAG, a novel framework to enable zero-shot emotion transfer from Chinese to Thai using a large language model (LLM)-based model, without relying on parallel emotional data. XEmoRAG extracts language-agnostic emotional embeddings from Chinese speech and retrieves emotionally matched Thai utterances from a curated emotional database, enabling controllable emotion transfer without explicit emotion labels. Additionally, a flow-matching alignment module minimizes pitch and duration mismatches, ensuring natural prosody. It also blends Chinese timbre into the Thai synthesis, enhancing rhythmic accuracy and emotional expression, while preserving speaker characteristics and emotional consistency. Experimental results show that XEmoRAG synthesizes expressive and natural Thai speech using only Chinese reference audio, without requiring explicit emotion labels. These results highlight XEmoRAG's capability to achieve flexible and low-resource emotional transfer across languages. Our demo is available at https://tlzuo-lesley.github.io/Demo-page/ .
Weakly Supervised Data Refinement and Flexible Sequence Compression for Efficient Thai LLM-based ASR
May 28, 2025Despite remarkable achievements, automatic speech recognition (ASR) in low-resource scenarios still faces two challenges: high-quality data scarcity and high computational demands. This paper proposes EThai-ASR, the first to apply large language models (LLMs) to Thai ASR and create an efficient LLM-based ASR system. EThai-ASR comprises a speech encoder, a connection module and a Thai LLM decoder. To address the data scarcity and obtain a powerful speech encoder, EThai-ASR introduces a self-evolving data refinement strategy to refine weak labels, yielding an enhanced speech encoder. Moreover, we propose a pluggable sequence compression module used in the connection module with three modes designed to reduce the sequence length, thus decreasing computational demands while maintaining decent performance. Extensive experiments demonstrate that EThai-ASR has achieved state-of-the-art accuracy in multiple datasets. We release our refined text transcripts to promote further research.
FreeV: Free Lunch For Vocoders Through Pseudo Inversed Mel Filter
Jun 12, 2024



Vocoders reconstruct speech waveforms from acoustic features and play a pivotal role in modern TTS systems. Frequent-domain GAN vocoders like Vocos and APNet2 have recently seen rapid advancements, outperforming time-domain models in inference speed while achieving comparable audio quality. However, these frequency-domain vocoders suffer from large parameter sizes, thus introducing extra memory burden. Inspired by PriorGrad and SpecGrad, we employ pseudo-inverse to estimate the amplitude spectrum as the initialization roughly. This simple initialization significantly mitigates the parameter demand for vocoder. Based on APNet2 and our streamlined Amplitude prediction branch, we propose our FreeV, compared with its counterpart APNet2, our FreeV achieves 1.8 times inference speed improvement with nearly half parameters. Meanwhile, our FreeV outperforms APNet2 in resynthesis quality, marking a step forward in pursuing real-time, high-fidelity speech synthesis. Code and checkpoints is available at: https://github.com/BakerBunker/FreeV
The syntax-semantics interface in a child's path: A study of 3- to 11-year-olds' elicited production of Mandarin recursive relative clauses
Jun 06, 2024

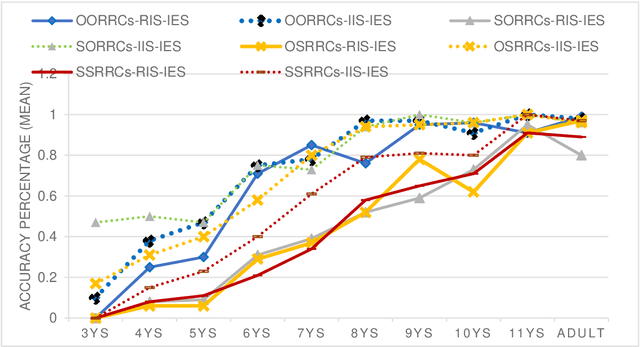
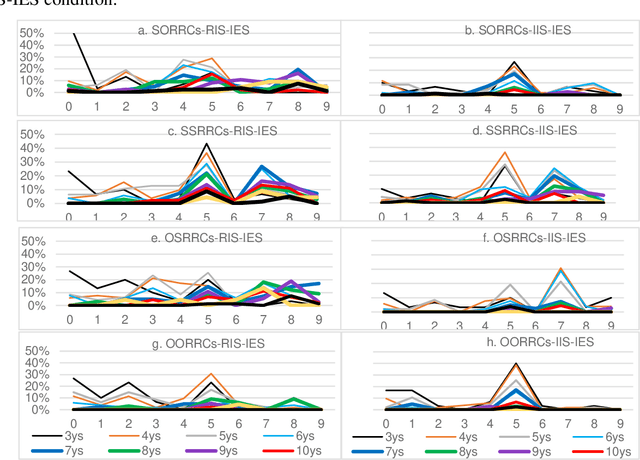
There have been apparently conflicting claims over the syntax-semantics relationship in child acquisition. However, few of them have assessed the child's path toward the acquisition of recursive relative clauses (RRCs). The authors of the current paper did experiments to investigate 3- to 11-year-olds' most-structured elicited production of eight Mandarin RRCs in a 4 (syntactic types)*2 (semantic conditions) design. The four syntactic types were RRCs with a subject-gapped RC embedded in an object-gapped RC (SORRCs), RRCs with an object-gapped RC embedded in another object-gapped RC (OORRCs), RRCs with an object-gapped RC embedded in a subject-gapped RC (OSRRCs), and RRCs with a subject-gapped RC embedded in another subject-gapped RC (SSRRCs). Each syntactic type was put in two conditions differing in internal semantics: irreversible internal semantics (IIS) and reversible internal semantics (RIS). For example, "the balloon that [the girl that _ eats the banana] holds _" is SORRCs in the IIS condition; "the monkey that [the dog that _ bites the pig] hits_" is SORRCs in the RIS condition. For each target, the participants were provided with a speech-visual stimulus constructing a condition of irreversible external semantics (IES). The results showed that SSRRCs, OSRRCs and SORRCs in the IIS-IES condition were produced two years earlier than their counterparts in the RIS-IES condition. Thus, a 2-stage development path is proposed: the language acquisition device starts with the interface between (irreversible) syntax and IIS, and ends with the interface between syntax and IES, both abiding by the syntax-semantic interface principle.
IQDUBBING: Prosody modeling based on discrete self-supervised speech representation for expressive voice conversion
Jan 02, 2022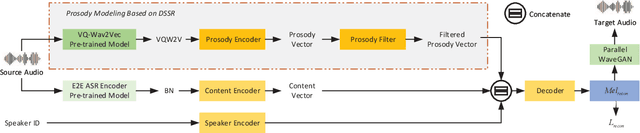
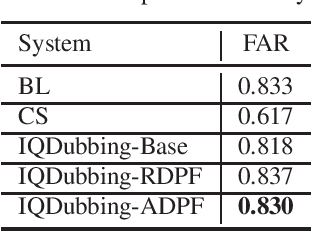
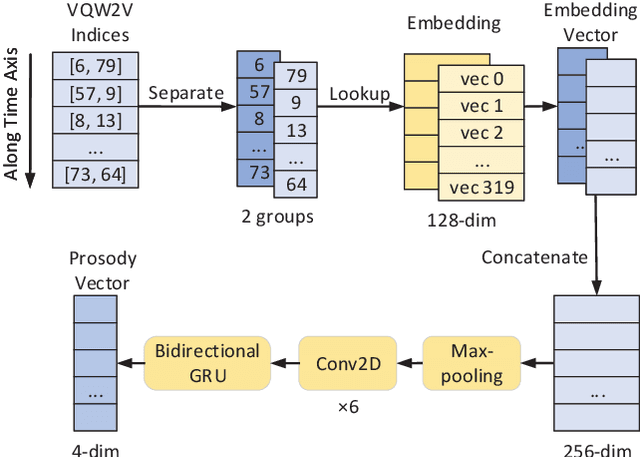
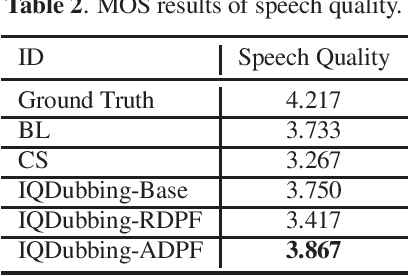
Prosody modeling is important, but still challenging in expressive voice conversion. As prosody is difficult to model, and other factors, e.g., speaker, environment and content, which are entangled with prosody in speech, should be removed in prosody modeling. In this paper, we present IQDubbing to solve this problem for expressive voice conversion. To model prosody, we leverage the recent advances in discrete self-supervised speech representation (DSSR). Specifically, prosody vector is first extracted from pre-trained VQ-Wav2Vec model, where rich prosody information is embedded while most speaker and environment information are removed effectively by quantization. To further filter out the redundant information except prosody, such as content and partial speaker information, we propose two kinds of prosody filters to sample prosody from the prosody vector. Experiments show that IQDubbing is superior to baseline and comparison systems in terms of speech quality while maintaining prosody consistency and speaker similarity.