 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMLF: Multi-modal Multi-class Late Fusion for Object Detection with Uncertainty Estimation
Oct 11, 2024Autonomous driving necessitates advanced object detection techniques that integrate information from multiple modalities to overcome the limitations associated with single-modal approaches. The challenges of aligning diverse data in early fusion and the complexities, along with overfitting issues introduced by deep fusion, underscore the efficacy of late fusion at the decision level. Late fusion ensures seamless integration without altering the original detector's network structure. This paper introduces a pioneering Multi-modal Multi-class Late Fusion method, designed for late fusion to enable multi-class detection. Fusion experiments conducted on the KITTI validation and official test datasets illustrate substantial performance improvements, presenting our model as a versatile solution for multi-modal object detection in autonomous driving. Moreover, our approach incorporates uncertainty analysis into the classification fusion process, rendering our model more transparent and trustworthy and providing more reliable insights into category predictions.
The syntax-semantics interface in a child's path: A study of 3- to 11-year-olds' elicited production of Mandarin recursive relative clauses
Jun 06, 2024

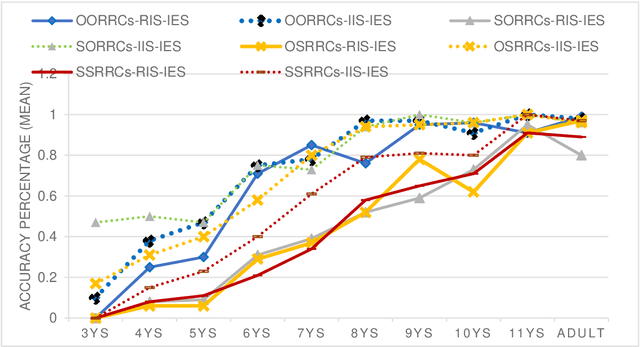
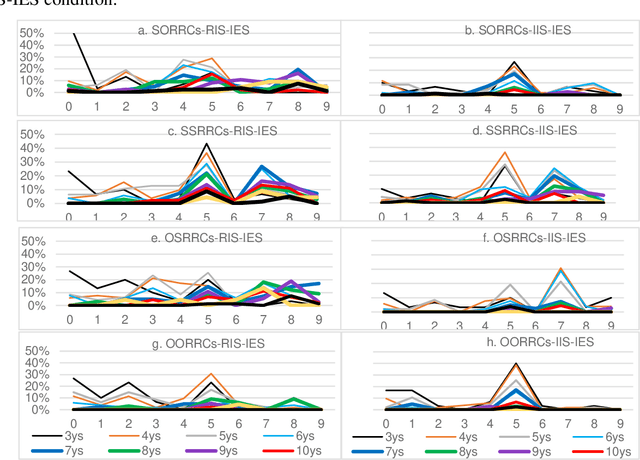
There have been apparently conflicting claims over the syntax-semantics relationship in child acquisition. However, few of them have assessed the child's path toward the acquisition of recursive relative clauses (RRCs). The authors of the current paper did experiments to investigate 3- to 11-year-olds' most-structured elicited production of eight Mandarin RRCs in a 4 (syntactic types)*2 (semantic conditions) design. The four syntactic types were RRCs with a subject-gapped RC embedded in an object-gapped RC (SORRCs), RRCs with an object-gapped RC embedded in another object-gapped RC (OORRCs), RRCs with an object-gapped RC embedded in a subject-gapped RC (OSRRCs), and RRCs with a subject-gapped RC embedded in another subject-gapped RC (SSRRCs). Each syntactic type was put in two conditions differing in internal semantics: irreversible internal semantics (IIS) and reversible internal semantics (RIS). For example, "the balloon that [the girl that _ eats the banana] holds _" is SORRCs in the IIS condition; "the monkey that [the dog that _ bites the pig] hits_" is SORRCs in the RIS condition. For each target, the participants were provided with a speech-visual stimulus constructing a condition of irreversible external semantics (IES). The results showed that SSRRCs, OSRRCs and SORRCs in the IIS-IES condition were produced two years earlier than their counterparts in the RIS-IES condition. Thus, a 2-stage development path is proposed: the language acquisition device starts with the interface between (irreversible) syntax and IIS, and ends with the interface between syntax and IES, both abiding by the syntax-semantic interface principle.
Grammaticality illusion or ambiguous interpretation? Event-related potentials reveal the nature of the missing-NP effect in Mandarin centre-embedded structures
Feb 17, 2024In several languages, omitting a verb phrase (VP) in double centre-embedded structures creates a grammaticality illusion. Similar illusion also exhibited in Mandarin missing-NP double centre-embedded structures. However, there is no consensus on its very nature. Instead of treating it as grammaticality illusion, we argue that ambiguous interpretations of verbs can best account for this phenomenon in Mandarin. To further support this hypothesis, we conducted two electroencephalography (EEG) experiments on quasi double centre-embedded structures whose complexity is reduced by placing the self-embedding relative clauses into the sentence's subject position. Experiment 1 showed that similar phenomenon even exhibited in this structure, evidenced by an absence of P600 effect and a presence of N400 effect. In Experiment 2, providing semantic cues to reduce ambiguity dispelled this illusion, as evidenced by a P600 effect. We interpret the results under garden-path theory and propose that word-order difference may account for this cross-linguistic variation.
EADNet: Efficient Asymmetric Dilated Network for Semantic Segmentation
Mar 16, 2021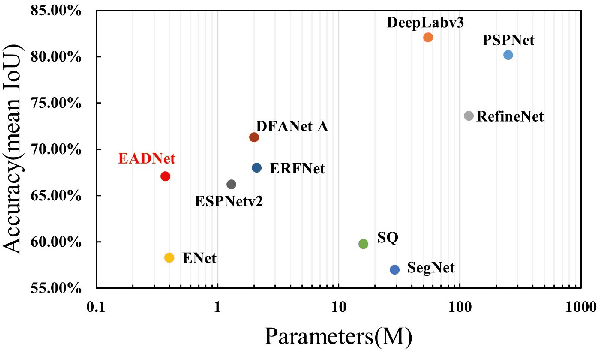
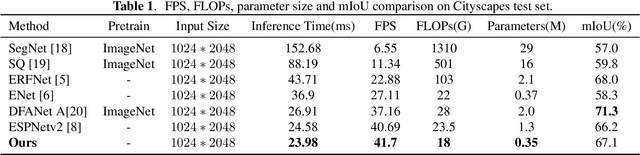
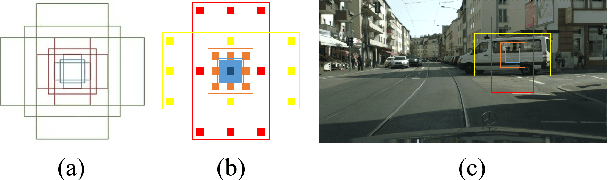
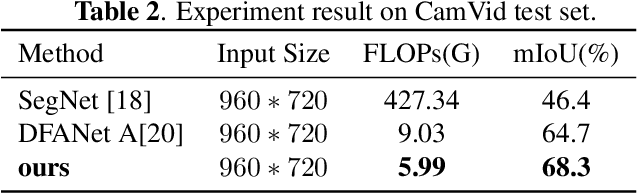
Due to real-time image semantic segmentation needs on power constrained edge devices, there has been an increasing desire to design lightweight semantic segmentation neural network, to simultaneously reduce computational cost and increase inference speed. In this paper, we propose an efficient asymmetric dilated semantic segmentation network, named EADNet, which consists of multiple developed asymmetric convolution branches with different dilation rates to capture the variable shapes and scales information of an image. Specially, a multi-scale multi-shape receptive field convolution (MMRFC) block with only a few parameters is designed to capture such information. Experimental results on the Cityscapes dataset demonstrate that our proposed EADNet achieves segmentation mIoU of 67.1 with smallest number of parameters (only 0.35M) among mainstream lightweight semantic segmentation networks.