 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElmes*: Automated Construction of Fine-Grained Evaluation Rubrics for Large Language Models in Long-Tail Educational Scenarios
Jun 04, 2026Evaluating large language models (LLMs) for education requires measuring how models teach, not only what they know. Existing benchmarks emphasize domain-general correctness or depend on manually designed rubrics that scale poorly to long-tail pedagogical scenarios. We introduce Elmes*, an end-to-end framework for constructing, refining, and applying fine-grained scenario-specific rubrics. Elmes* combines a declarative multi-agent engine for teacher--student--judge interactions with SceneGen, a self-evolving module that co-optimizes evaluation criteria and test data from expert-defined pedagogical dimensions. Using Elmes*, we build Edu-330, covering 330 scenarios across 11 subjects, 3 grade bands, and 10 task types, with over 1{,}000 second-level indicators. Experiments on Edu-330 and four expert-authored gold-standard scenarios show that educational capability is multidimensional: top-tier LLMs differ mainly in creativity and values integration, knowledge-strong models may fail at Socratic scaffolding, and the education-specialized InnoSpark achieves the best human-evaluated average score. LLM judges preserve human-comparable rankings with much lower scoring variance, but exhibit judge-specific biases such as self-preference. Ablations show that expert-scored few-shot anchoring improves human--LLM alignment, while reasoning enforcement and greedy decoding are model-dependent. Elmes* thus provides scalable diagnostic infrastructure for pedagogically grounded LLM evaluation.
AcademiClaw: When Students Set Challenges for AI Agents
May 04, 2026Benchmarks within the OpenClaw ecosystem have thus far evaluated exclusively assistant-level tasks, leaving the academic-level capabilities of OpenClaw largely unexamined. We introduce AcademiClaw, a bilingual benchmark of 80 complex, long-horizon tasks sourced directly from university students' real academic workflows -- homework, research projects, competitions, and personal projects -- that they found current AI agents unable to solve effectively. Curated from 230 student-submitted candidates through rigorous expert review, the final task set spans 25+ professional domains, ranging from olympiad-level mathematics and linguistics problems to GPU-intensive reinforcement learning and full-stack system debugging, with 16 tasks requiring CUDA GPU execution. Each task executes in an isolated Docker sandbox and is scored on task completion by multi-dimensional rubrics combining six complementary techniques, with an independent five-category safety audit providing additional behavioral analysis. Experiments on six frontier models show that even the best achieves only a 55\% pass rate. Further analysis uncovers sharp capability boundaries across task domains, divergent behavioral strategies among models, and a disconnect between token consumption and output quality, providing fine-grained diagnostic signals beyond what aggregate metrics reveal. We hope that AcademiClaw and its open-sourced data and code can serve as a useful resource for the OpenClaw community, driving progress toward agents that are more capable and versatile across the full breadth of real-world academic demands. All data and code are available at https://github.com/GAIR-NLP/AcademiClaw.
Accelerating Diffusion-based Video Editing via Heterogeneous Caching: Beyond Full Computing at Sampled Denoising Timestep
Mar 25, 2026Diffusion-based video editing has emerged as an important paradigm for high-quality and flexible content generation. However, despite their generality and strong modeling capacity, Diffusion Transformers (DiT) remain computationally expensive due to the iterative denoising process, posing challenges for practical deployment. Existing video diffusion acceleration methods primarily exploit denoising timestep-level feature reuse, which mitigates the redundancy in denoising process, but overlooks the architectural redundancy within the DiT that many attention operations over spatio-temporal tokens are redundantly executed, offering little to no incremental contribution to the model output. This work introduces HetCache, a training-free diffusion acceleration framework designed to exploit the inherent heterogeneity in diffusion-based masked video-to-video (MV2V) generation and editing. Instead of uniformly reuse or randomly sampling tokens, HetCache assesses the contextual relevance and interaction strength among various types of tokens in designated computing steps. Guided by spatial priors, it divides the spatial-temporal tokens in DiT model into context and generative tokens, and selectively caches the context tokens that exhibit the strongest correlation and most representative semantics with generative ones. This strategy reduces redundant attention operations while maintaining editing consistency and fidelity. Experiments show that HetCache achieves a noticeable acceleration, including a 2.67$\times$ latency speedup and FLOPs reduction over commonly used foundation models, with negligible degradation in editing quality.
FuXi-$γ$: Efficient Sequential Recommendation with Exponential-Power Temporal Encoder and Diagonal-Sparse Positional Mechanism
Dec 14, 2025Sequential recommendation aims to model users' evolving preferences based on their historical interactions. Recent advances leverage Transformer-based architectures to capture global dependencies, but existing methods often suffer from high computational overhead, primarily due to discontinuous memory access in temporal encoding and dense attention over long sequences. To address these limitations, we propose FuXi-$γ$, a novel sequential recommendation framework that improves both effectiveness and efficiency through principled architectural design. FuXi-$γ$ adopts a decoder-only Transformer structure and introduces two key innovations: (1) An exponential-power temporal encoder that encodes relative temporal intervals using a tunable exponential decay function inspired by the Ebbinghaus forgetting curve. This encoder enables flexible modeling of both short-term and long-term preferences while maintaining high efficiency through continuous memory access and pure matrix operations. (2) A diagonal-sparse positional mechanism that prunes low-contribution attention blocks using a diagonal-sliding strategy guided by the persymmetry of Toeplitz matrix. Extensive experiments on four real-world datasets demonstrate that FuXi-$γ$ achieves state-of-the-art performance in recommendation quality, while accelerating training by up to 4.74$\times$ and inference by up to 6.18$\times$, making it a practical and scalable solution for long-sequence recommendation. Our code is available at https://github.com/Yeedzhi/FuXi-gamma.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
Jul 27, 2025
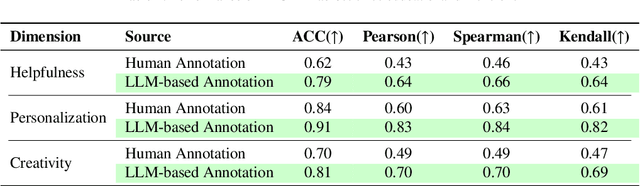

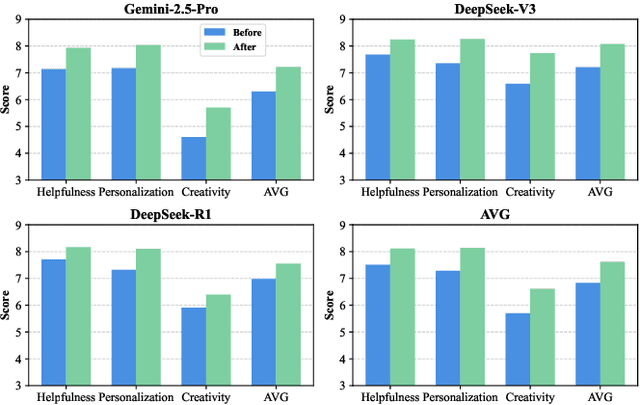
The integration of large language models (LLMs) into education presents unprecedented opportunities for scalable personalized learning. However, standard LLMs often function as generic information providers, lacking alignment with fundamental pedagogical principles such as helpfulness, student-centered personalization, and creativity cultivation. To bridge this gap, we propose EduAlign, a novel framework designed to guide LLMs toward becoming more effective and responsible educational assistants. EduAlign consists of two main stages. In the first stage, we curate a dataset of 8k educational interactions and annotate them-both manually and automatically-along three key educational dimensions: Helpfulness, Personalization, and Creativity (HPC). These annotations are used to train HPC-RM, a multi-dimensional reward model capable of accurately scoring LLM outputs according to these educational principles. We further evaluate the consistency and reliability of this reward model. In the second stage, we leverage HPC-RM as a reward signal to fine-tune a pre-trained LLM using Group Relative Policy Optimization (GRPO) on a set of 2k diverse prompts. We then assess the pre- and post-finetuning models on both educational and general-domain benchmarks across the three HPC dimensions. Experimental results demonstrate that the fine-tuned model exhibits significantly improved alignment with pedagogical helpfulness, personalization, and creativity stimulation. This study presents a scalable and effective approach to aligning LLMs with nuanced and desirable educational traits, paving the way for the development of more engaging, pedagogically aligned AI tutors.
Empowering Large Language Model for Continual Video Question Answering with Collaborative Prompting
Oct 01, 2024



In recent years, the rapid increase in online video content has underscored the limitations of static Video Question Answering (VideoQA) models trained on fixed datasets, as they struggle to adapt to new questions or tasks posed by newly available content. In this paper, we explore the novel challenge of VideoQA within a continual learning framework, and empirically identify a critical issue: fine-tuning a large language model (LLM) for a sequence of tasks often results in catastrophic forgetting. To address this, we propose Collaborative Prompting (ColPro), which integrates specific question constraint prompting, knowledge acquisition prompting, and visual temporal awareness prompting. These prompts aim to capture textual question context, visual content, and video temporal dynamics in VideoQA, a perspective underexplored in prior research. Experimental results on the NExT-QA and DramaQA datasets show that ColPro achieves superior performance compared to existing approaches, achieving 55.14\% accuracy on NExT-QA and 71.24\% accuracy on DramaQA, highlighting its practical relevance and effectiveness.
Deep Feature Surgery: Towards Accurate and Efficient Multi-Exit Networks
Jul 19, 2024



Multi-exit network is a promising architecture for efficient model inference by sharing backbone networks and weights among multiple exits. However, the gradient conflict of the shared weights results in sub-optimal accuracy. This paper introduces Deep Feature Surgery (\methodname), which consists of feature partitioning and feature referencing approaches to resolve gradient conflict issues during the training of multi-exit networks. The feature partitioning separates shared features along the depth axis among all exits to alleviate gradient conflict while simultaneously promoting joint optimization for each exit. Subsequently, feature referencing enhances multi-scale features for distinct exits across varying depths to improve the model accuracy. Furthermore, \methodname~reduces the training operations with the reduced complexity of backpropagation. Experimental results on Cifar100 and ImageNet datasets exhibit that \methodname~provides up to a \textbf{50.00\%} reduction in training time and attains up to a \textbf{6.94\%} enhancement in accuracy when contrasted with baseline methods across diverse models and tasks. Budgeted batch classification evaluation on MSDNet demonstrates that DFS uses about $\mathbf{2}\boldsymbol{\times}$ fewer average FLOPs per image to achieve the same classification accuracy as baseline methods on Cifar100.
Statistical Parameterized Physics-Based Machine Learning Digital Twin Models for Laser Powder Bed Fusion Process
Nov 14, 2023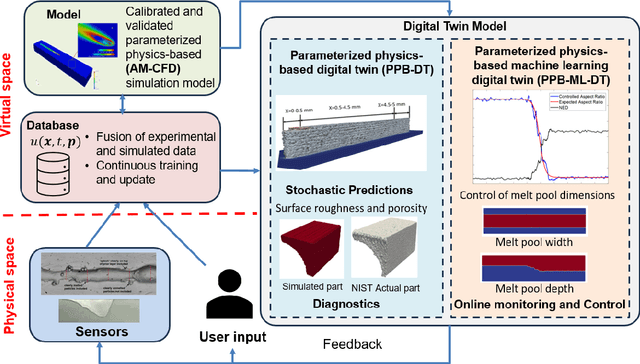
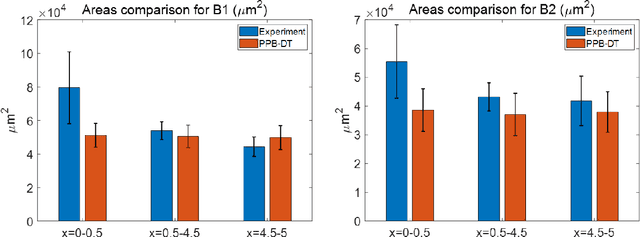
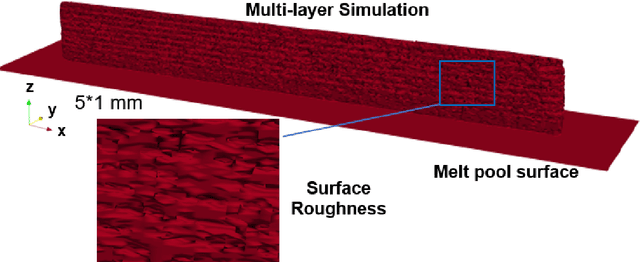
A digital twin (DT) is a virtual representation of physical process, products and/or systems that requires a high-fidelity computational model for continuous update through the integration of sensor data and user input. In the context of laser powder bed fusion (LPBF) additive manufacturing, a digital twin of the manufacturing process can offer predictions for the produced parts, diagnostics for manufacturing defects, as well as control capabilities. This paper introduces a parameterized physics-based digital twin (PPB-DT) for the statistical predictions of LPBF metal additive manufacturing process. We accomplish this by creating a high-fidelity computational model that accurately represents the melt pool phenomena and subsequently calibrating and validating it through controlled experiments. In PPB-DT, a mechanistic reduced-order method-driven stochastic calibration process is introduced, which enables the statistical predictions of the melt pool geometries and the identification of defects such as lack-of-fusion porosity and surface roughness, specifically for diagnostic applications. Leveraging data derived from this physics-based model and experiments, we have trained a machine learning-based digital twin (PPB-ML-DT) model for predicting, monitoring, and controlling melt pool geometries. These proposed digital twin models can be employed for predictions, control, optimization, and quality assurance within the LPBF process, ultimately expediting product development and certification in LPBF-based metal additive manufacturing.
AutoQNN: An End-to-End Framework for Automatically Quantizing Neural Networks
Apr 07, 2023Exploring the expected quantizing scheme with suitable mixed-precision policy is the key point to compress deep neural networks (DNNs) in high efficiency and accuracy. This exploration implies heavy workloads for domain experts, and an automatic compression method is needed. However, the huge search space of the automatic method introduces plenty of computing budgets that make the automatic process challenging to be applied in real scenarios. In this paper, we propose an end-to-end framework named AutoQNN, for automatically quantizing different layers utilizing different schemes and bitwidths without any human labor. AutoQNN can seek desirable quantizing schemes and mixed-precision policies for mainstream DNN models efficiently by involving three techniques: quantizing scheme search (QSS), quantizing precision learning (QPL), and quantized architecture generation (QAG). QSS introduces five quantizing schemes and defines three new schemes as a candidate set for scheme search, and then uses the differentiable neural architecture search (DNAS) algorithm to seek the layer- or model-desired scheme from the set. QPL is the first method to learn mixed-precision policies by reparameterizing the bitwidths of quantizing schemes, to the best of our knowledge. QPL optimizes both classification loss and precision loss of DNNs efficiently and obtains the relatively optimal mixed-precision model within limited model size and memory footprint. QAG is designed to convert arbitrary architectures into corresponding quantized ones without manual intervention, to facilitate end-to-end neural network quantization. We have implemented AutoQNN and integrated it into Keras. Extensive experiments demonstrate that AutoQNN can consistently outperform state-of-the-art quantization.
Human-Aware Robot Navigation via Reinforcement Learning with Hindsight Experience Replay and Curriculum Learning
Oct 09, 2021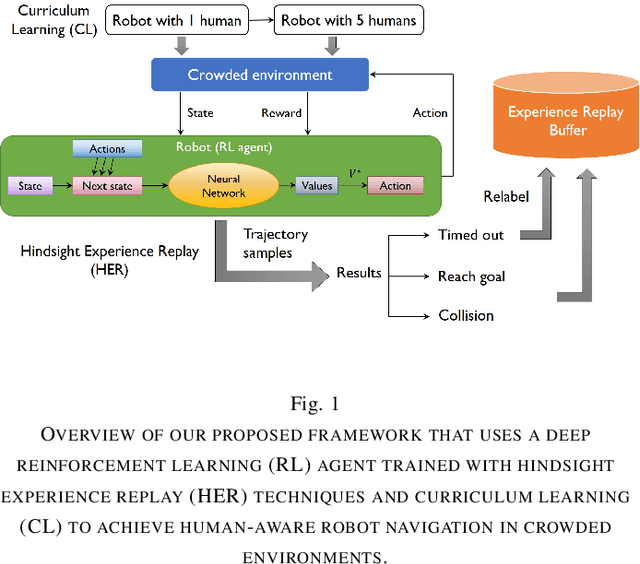
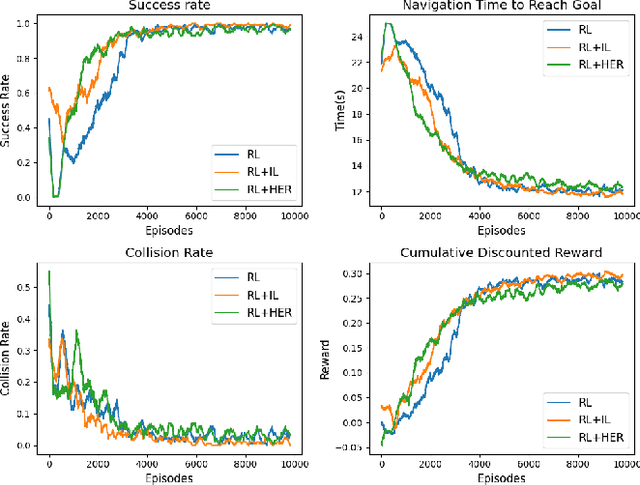
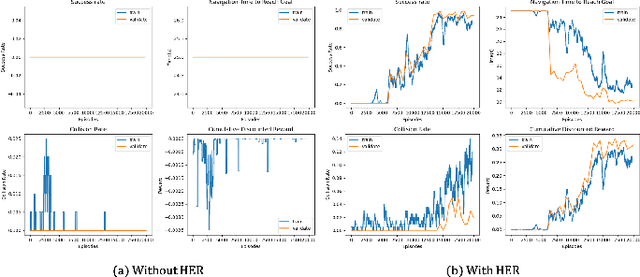
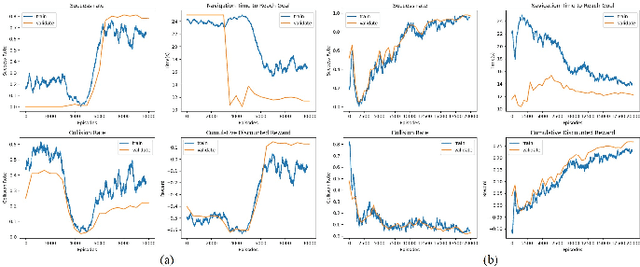
In recent years, the growing demand for more intelligent service robots is pushing the development of mobile robot navigation algorithms to allow safe and efficient operation in a dense crowd. Reinforcement learning (RL) approaches have shown superior ability in solving sequential decision making problems, and recent work has explored its potential to learn navigation polices in a socially compliant manner. However, the expert demonstration data used in existing methods is usually expensive and difficult to obtain. In this work, we consider the task of training an RL agent without employing the demonstration data, to achieve efficient and collision-free navigation in a crowded environment. To address the sparse reward navigation problem, we propose to incorporate the hindsight experience replay (HER) and curriculum learning (CL) techniques with RL to efficiently learn the optimal navigation policy in the dense crowd. The effectiveness of our method is validated in a simulated crowd-robot coexisting environment. The results demonstrate that our method can effectively learn human-aware navigation without requiring additional demonstration data.