 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePierGuard: A Planning Framework for Underwater Robotic Inspection of Coastal Piers
May 07, 2025Using underwater robots instead of humans for the inspection of coastal piers can enhance efficiency while reducing risks. A key challenge in performing these tasks lies in achieving efficient and rapid path planning within complex environments. Sampling-based path planning methods, such as Rapidly-exploring Random Tree* (RRT*), have demonstrated notable performance in high-dimensional spaces. In recent years, researchers have begun designing various geometry-inspired heuristics and neural network-driven heuristics to further enhance the effectiveness of RRT*. However, the performance of these general path planning methods still requires improvement when applied to highly cluttered underwater environments. In this paper, we propose PierGuard, which combines the strengths of bidirectional search and neural network-driven heuristic regions. We design a specialized neural network to generate high-quality heuristic regions in cluttered maps, thereby improving the performance of the path planning. Through extensive simulation and real-world ocean field experiments, we demonstrate the effectiveness and efficiency of our proposed method compared with previous research. Our method achieves approximately 2.6 times the performance of the state-of-the-art geometric-based sampling method and nearly 4.9 times that of the state-of-the-art learning-based sampling method. Our results provide valuable insights for the automation of pier inspection and the enhancement of maritime safety. The updated experimental video is available in the supplementary materials.
ROLO-SLAM: Rotation-Optimized LiDAR-Only SLAM in Uneven Terrain with Ground Vehicle
Jan 04, 2025LiDAR-based SLAM is recognized as one effective method to offer localization guidance in rough environments. However, off-the-shelf LiDAR-based SLAM methods suffer from significant pose estimation drifts, particularly components relevant to the vertical direction, when passing to uneven terrains. This deficiency typically leads to a conspicuously distorted global map. In this article, a LiDAR-based SLAM method is presented to improve the accuracy of pose estimations for ground vehicles in rough terrains, which is termed Rotation-Optimized LiDAR-Only (ROLO) SLAM. The method exploits a forward location prediction to coarsely eliminate the location difference of consecutive scans, thereby enabling separate and accurate determination of the location and orientation at the front-end. Furthermore, we adopt a parallel-capable spatial voxelization for correspondence-matching. We develop a spherical alignment-guided rotation registration within each voxel to estimate the rotation of vehicle. By incorporating geometric alignment, we introduce the motion constraint into the optimization formulation to enhance the rapid and effective estimation of LiDAR's translation. Subsequently, we extract several keyframes to construct the submap and exploit an alignment from the current scan to the submap for precise pose estimation. Meanwhile, a global-scale factor graph is established to aid in the reduction of cumulative errors. In various scenes, diverse experiments have been conducted to evaluate our method. The results demonstrate that ROLO-SLAM excels in pose estimation of ground vehicles and outperforms existing state-of-the-art LiDAR SLAM frameworks.
Air-Ground Collaborative Robots for Fire and Rescue Missions: Towards Mapping and Navigation Perspective
Dec 30, 2024Air-ground collaborative robots have shown great potential in the field of fire and rescue, which can quickly respond to rescue needs and improve the efficiency of task execution. Mapping and navigation, as the key foundation for air-ground collaborative robots to achieve efficient task execution, have attracted a great deal of attention. This growing interest in collaborative robot mapping and navigation is conducive to improving the intelligence of fire and rescue task execution, but there has been no comprehensive investigation of this field to highlight their strengths. In this paper, we present a systematic review of the ground-to-ground cooperative robots for fire and rescue from a new perspective of mapping and navigation. First, an air-ground collaborative robots framework for fire and rescue missions based on unmanned aerial vehicle (UAV) mapping and unmanned ground vehicle (UGV) navigation is introduced. Then, the research progress of mapping and navigation under this framework is systematically summarized, including UAV mapping, UAV/UGV co-localization, and UGV navigation, with their main achievements and limitations. Based on the needs of fire and rescue missions, the collaborative robots with different numbers of UAVs and UGVs are classified, and their practicality in fire and rescue tasks is elaborated, with a focus on the discussion of their merits and demerits. In addition, the application examples of air-ground collaborative robots in various firefighting and rescue scenarios are given. Finally, this paper emphasizes the current challenges and potential research opportunities, rounding up references for practitioners and researchers willing to engage in this vibrant area of air-ground collaborative robots.
V$^2$-SfMLearner: Learning Monocular Depth and Ego-motion for Multimodal Wireless Capsule Endoscopy
Dec 23, 2024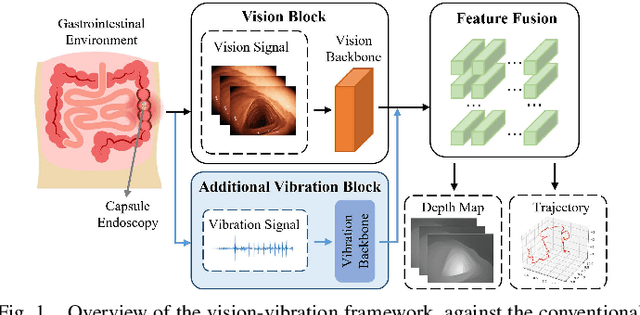
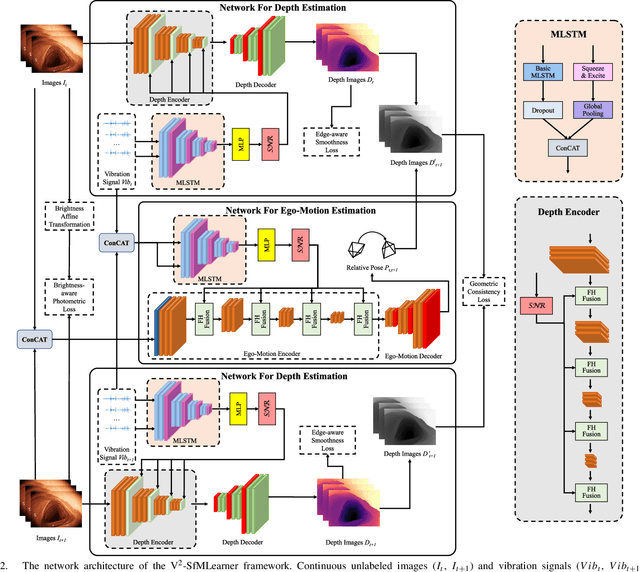
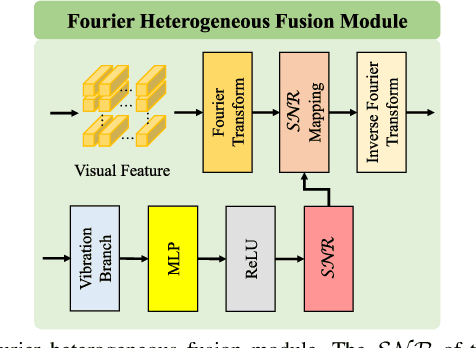
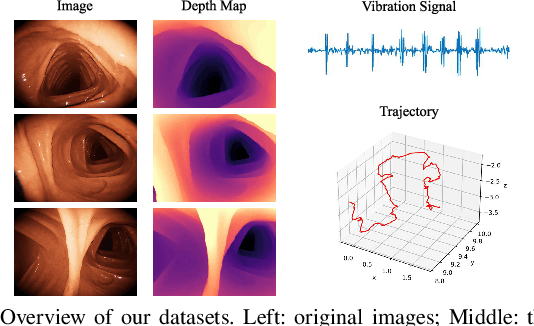
Deep learning can predict depth maps and capsule ego-motion from capsule endoscopy videos, aiding in 3D scene reconstruction and lesion localization. However, the collisions of the capsule endoscopies within the gastrointestinal tract cause vibration perturbations in the training data. Existing solutions focus solely on vision-based processing, neglecting other auxiliary signals like vibrations that could reduce noise and improve performance. Therefore, we propose V$^2$-SfMLearner, a multimodal approach integrating vibration signals into vision-based depth and capsule motion estimation for monocular capsule endoscopy. We construct a multimodal capsule endoscopy dataset containing vibration and visual signals, and our artificial intelligence solution develops an unsupervised method using vision-vibration signals, effectively eliminating vibration perturbations through multimodal learning. Specifically, we carefully design a vibration network branch and a Fourier fusion module, to detect and mitigate vibration noises. The fusion framework is compatible with popular vision-only algorithms. Extensive validation on the multimodal dataset demonstrates superior performance and robustness against vision-only algorithms. Without the need for large external equipment, our V$^2$-SfMLearner has the potential for integration into clinical capsule robots, providing real-time and dependable digestive examination tools. The findings show promise for practical implementation in clinical settings, enhancing the diagnostic capabilities of doctors.
Omni Differential Drive for Simultaneous Reconfiguration and Omnidirectional Mobility of Wheeled Robots
Dec 14, 2024Wheeled robots are highly efficient in human living environments. However, conventional wheeled designs, limited by degrees of freedom, struggle to meet varying footprint needs and achieve omnidirectional mobility. This paper proposes a novel robot drive model inspired by human movements, termed as the Omni Differential Drive (ODD). The ODD model innovatively utilizes a lateral differential drive to adjust wheel spacing without adding additional actuators to the existing omnidirectional drive. This approach enables wheeled robots to achieve both simultaneous reconfiguration and omnidirectional mobility. Additionally, a prototype was developed to validate the ODD, followed by kinematic analysis. Control systems for self-balancing and motion were designed and implemented. Experimental validations confirmed the feasibility of the ODD mechanism and the effectiveness of the control strategies. The results underline the potential of this innovative drive system to enhance the mobility and adaptability of robotic platforms.
Leveraging Semantic and Geometric Information for Zero-Shot Robot-to-Human Handover
Sep 26, 2024Human-robot interaction (HRI) encompasses a wide range of collaborative tasks, with handover being one of the most fundamental. As robots become more integrated into human environments, the potential for service robots to assist in handing objects to humans is increasingly promising. In robot-to-human (R2H) handover, selecting the optimal grasp is crucial for success, as it requires avoiding interference with the humans preferred grasp region and minimizing intrusion into their workspace. Existing methods either inadequately consider geometric information or rely on data-driven approaches, which often struggle to generalize across diverse objects. To address these limitations, we propose a novel zero-shot system that combines semantic and geometric information to generate optimal handover grasps. Our method first identifies grasp regions using semantic knowledge from vision-language models (VLMs) and, by incorporating customized visual prompts, achieves finer granularity in region grounding. A grasp is then selected based on grasp distance and approach angle to maximize human ease and avoid interference. We validate our approach through ablation studies and real-world comparison experiments. Results demonstrate that our system improves handover success rates and provides a more user-preferred interaction experience. Videos, appendixes and more are available at https://sites.google.com/view/vlm-handover/.
Collaborative Fall Detection and Response using Wi-Fi Sensing and Mobile Companion Robot
Jul 17, 2024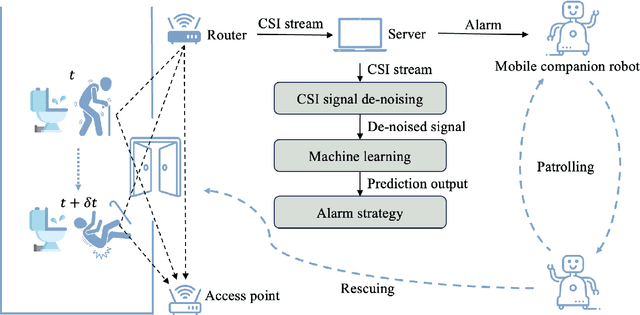
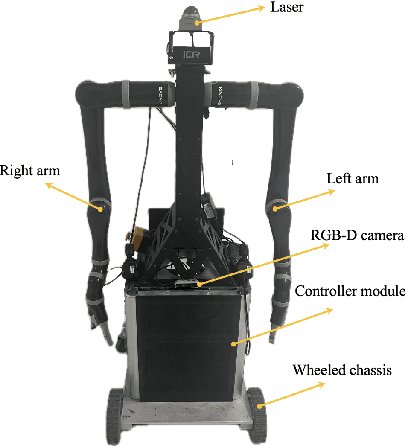
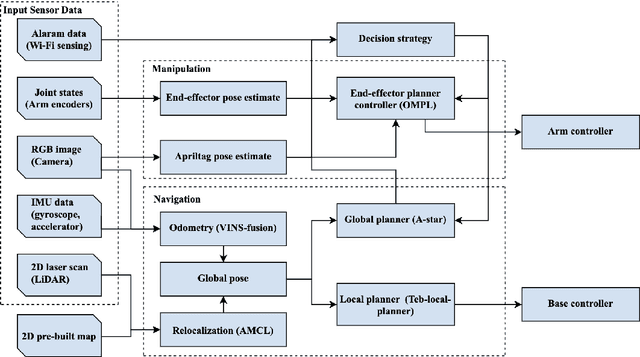
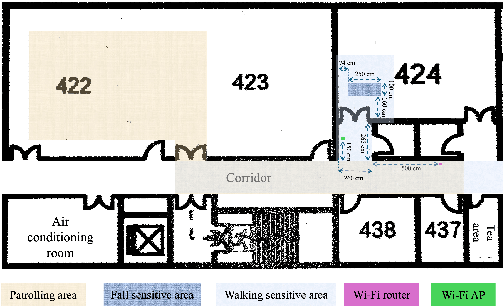
This paper presents a collaborative fall detection and response system integrating Wi-Fi sensing with robotic assistance. The proposed system leverages channel state information (CSI) disruptions caused by movements to detect falls in non-line-of-sight (NLOS) scenarios, offering non-intrusive monitoring. Besides, a companion robot is utilized to provide assistance capabilities to navigate and respond to incidents autonomously, improving efficiency in providing assistance in various environments. The experimental results demonstrate the effectiveness of the proposed system in detecting falls and responding effectively.
ODD: Omni Differential Drive for Simultaneous Reconfiguration and Omnidirectional Mobility of Wheeled Robots
Jul 14, 2024



Wheeled robots are highly efficient in human living environments. However, conventional wheeled designs, with their limited degrees of freedom and constraints in robot configuration, struggle to simultaneously achieve stability, passability, and agility due to varying footprint needs. This paper proposes a novel robot drive model inspired by human movements, termed as the Omni Differential Drive (ODD). The ODD model innovatively utilizes a lateral differential drive to adjust wheel spacing without adding additional actuators to the existing omnidirectional drive. This approach enables wheeled robots to achieve both simultaneous reconfiguration and omnidirectional mobility. To validate the feasibility of the ODD model, a functional prototype was developed, followed by comprehensive kinematic analyses. Control systems for self-balancing and motion control were designed and implemented. Experimental validations confirmed the feasibility of the ODD mechanism and the effectiveness of the control strategies. The results underline the potential of this innovative drive system to enhance the mobility and adaptability of robotic platforms.
Online Time-Informed Kinodynamic Motion Planning of Nonlinear Systems
Jul 03, 2024



Sampling-based kinodynamic motion planners (SKMPs) are powerful in finding collision-free trajectories for high-dimensional systems under differential constraints. Time-informed set (TIS) can provide the heuristic search domain to accelerate their convergence to the time-optimal solution. However, existing TIS approximation methods suffer from the curse of dimensionality, computational burden, and limited system applicable scope, e.g., linear and polynomial nonlinear systems. To overcome these problems, we propose a method by leveraging deep learning technology, Koopman operator theory, and random set theory. Specifically, we propose a Deep Invertible Koopman operator with control U model named DIKU to predict states forward and backward over a long horizon by modifying the auxiliary network with an invertible neural network. A sampling-based approach, ASKU, performing reachability analysis for the DIKU is developed to approximate the TIS of nonlinear control systems online. Furthermore, we design an online time-informed SKMP using a direct sampling technique to draw uniform random samples in the TIS. Simulation experiment results demonstrate that our method outperforms other existing works, approximating TIS in near real-time and achieving superior planning performance in several time-optimal kinodynamic motion planning problems.
QUADFormer: Learning-based Detection of Cyber Attacks in Quadrotor UAVs
Jun 02, 2024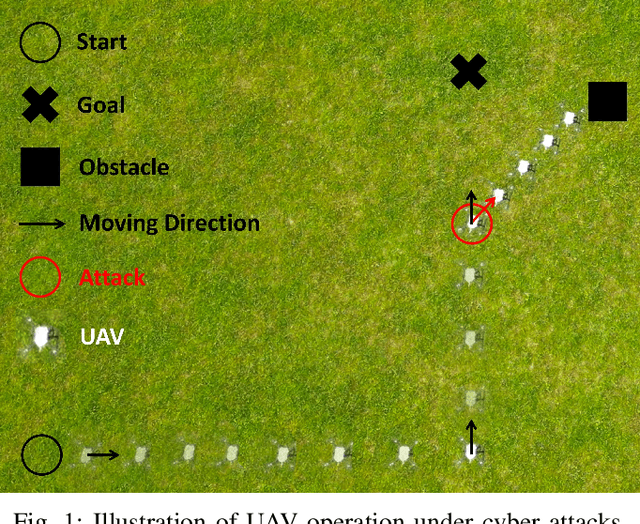
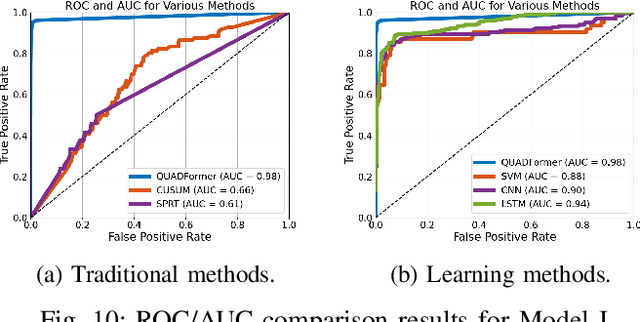
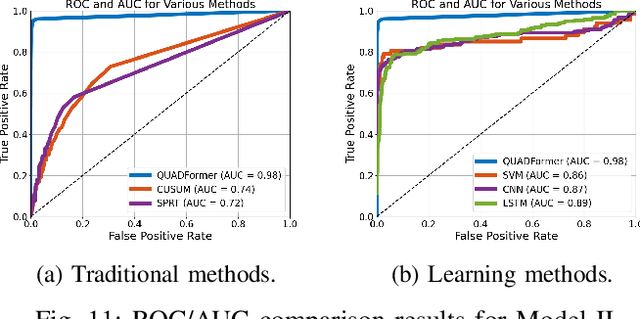
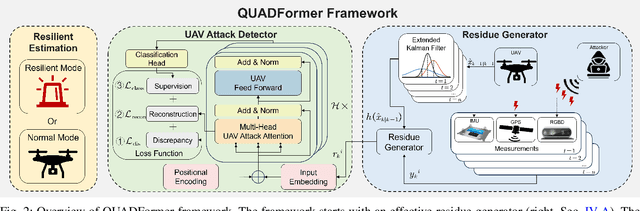
Safety-critical intelligent cyber-physical systems, such as quadrotor unmanned aerial vehicles (UAVs), are vulnerable to different types of cyber attacks, and the absence of timely and accurate attack detection can lead to severe consequences. When UAVs are engaged in large outdoor maneuvering flights, their system constitutes highly nonlinear dynamics that include non-Gaussian noises. Therefore, the commonly employed traditional statistics-based and emerging learning-based attack detection methods do not yield satisfactory results. In response to the above challenges, we propose QUADFormer, a novel Quadrotor UAV Attack Detection framework with transFormer-based architecture. This framework includes a residue generator designed to generate a residue sequence sensitive to anomalies. Subsequently, this sequence is fed into a transformer structure with disparity in correlation to specifically learn its statistical characteristics for the purpose of classification and attack detection. Finally, we design an alert module to ensure the safe execution of tasks by UAVs under attack conditions. We conduct extensive simulations and real-world experiments, and the results show that our method has achieved superior detection performance compared with many state-of-the-art methods.